一、计算机基础
计算机(computer)俗称电脑,是现代一种用于高速计算的电子计算机器,可以进行数值计算,又可以进行逻辑计算,还具有存储记忆功能。是能够按照程序运行,自动、高速处理海量数据的现代化智能电子设备。
计算机是20世纪最先进的科学技术发明之一,对人类的生产活动和社会活动产生了极其重要的影响。它的应用领域从最初的军事科研应用扩展到社会的各个领域,已形成了规模巨大的计算机产业,带动了全球范围的技术进步,由此引发了深刻的社会变革。

1.1、计算机如何工作的?
1.1.1、字节与二进制
二进制(binary),发现者莱布尼茨,是在数学和数字电路中以2为基数的记数系统,是以2为基数代表系统的二进位制。这一系统中,通常用两个不同的符号0(代表零)和1(代表一)来表示。逢二进一,电路只能实现二进制的逻辑运算。
首先要了解字节和二进制。字节(Byte)是计算机信息技术用于计量的存储单位。计算机中表示数据的最小单位是 bit(位),其值可以取 0 或 1 ,一个字节占有8个比特位。
1
2
3
|
0000 0001
0000 0001
0000 0010
|
1.1.2、1+1如何计算的
我们以1+1为例:我曾经一个女朋友问过我一个特别简单的问题:1+1计算机是如何计算到2的?
CPU 有一个指令指挥官,他负责指令的分类与调度。例如,他看到指令是「010100010010」,首先从前 4 位 0101 判断,这是一个寄存器设置命令,于是就打电话通知寄存器来领取数据;如果看到前 4 位是 1010,就知道这是一个加法指令,就通知算术运算单位的加法器来领取任务。待加法器计算完了,他又会将运算结果发给寄存器保存。
加法器就是一个电路系统,如下:
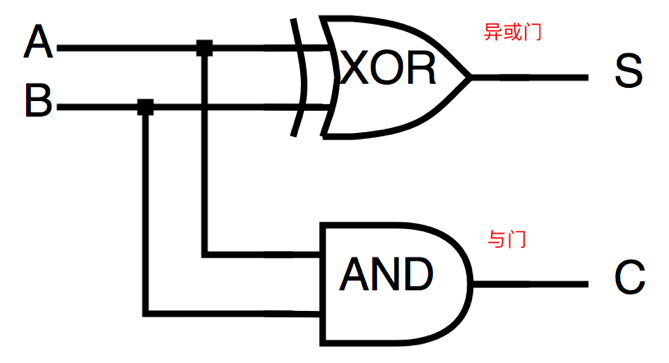
注:在上图中,A、B 是输入,S 是结果,C 是进位结果。
其中异或门的逻辑是这样的:
1.1、计算机发展
1943年,此时正是二战时期,美国为了实验新式火炮,需要计算火炮的弹道表。需要进行大量计算。一张弹道表需要计算近4000条弹道,每条弹道需要计算750此乘法和更多的加减法,工作量巨大。 你可以想象这样一个场景:一发炮弹打出去,100多人用一种手摇计算机算个不停,还经常出错,费力不讨好。当时任职宾夕法尼亚大学莫尔电机工程学院的莫希利(John Mauchly)于 1942年提出了试制第一台电子计算机的初始设想——“高速电子管计算装置的使用”,期望用电子管代替继电器以提高机器的计算速度。
美国军方得知这一设想后,拨款成立了一个以莫希利、埃克特(John Eckert)为首的研制小组。终于在1946年2月14日,世界上第二台电子计算机,世界上第一台通用计算机 (多个行业都可以使用)埃历阿克”(ENIAC,译成中文是“电子数字积分和计算机”)诞生于美国宾夕法尼亚大学。
ENIAC长30.48米,宽6米,高2.4米,占地面积约170平方米,30个操作台,重达30英吨,耗电量150千瓦,造价48万美元。它包含了17,468根真空管(电子管)7,200根晶体二极管,1,500 个中转,70,000个电阻器,10,000个电容器,1500个继电器,6000多个开关。
每秒能进行5000次加法运算(据测算,人最快的运算速度每秒仅 5次加法运算),每秒400次乘法运算,是使用继电器运转的机电式计算机的1000倍、手工计算的20万倍。。它还能进行平方和立方运算,计算正弦和余弦等三角函数的值及其它一些更复杂的运算。
以我们的眼光来看,这当然很微不足道。但这在当时可是很了不起的成就!原来需要20多分钟时间才能计算出来的一条弹道,现在只要短短的30秒!
ENIAC奠定了电脑的发展基础,开辟了计算机科学技术的新纪元,有人将其称为人类第三次产业革命开始的标志。
根据计算机所采用的物理器件的发展,一般把电子计算机的发展分成四个阶段。
-
电子管计算机时代(1946~1958)
特点:逻辑元件采用的是电子管,软件方面采用的是机器语言、汇编语言。缺点是体积大、功耗高、可靠性差。速度慢(一般为每秒数千次至数万次)、价格昂贵。


-
晶体管计算机时代(1956-1963)
特点:软件方面的操作系统、高级语言及其编译程序应用领域以科学计算和事务处理为主,并开始进入工业控制领域。特点是体积缩小、能耗降低、可靠性提高、运算速度提高(一般为每秒数10万次,可高达300万次)、性能比第1代计算机有很大的提高。


-
集成电路计算机时代(1964-1971)
特点:硬件方面,逻辑元件采用中、小规模集成电路(MSI、SSI),主存储器仍采用磁芯。软件方面出现了分时操作系统以及结构化、规模化程序设计方法。特点是速度更快(一般为每秒数百万次至数千万次),而且可靠性有了显著提高,价格进一步下降,产品走向了通用化、系列化和标准化等。应用领域开始进入文字处理和图形图像处理领域。

逻辑门数小于10门(或含元件数小于100个)


第一台集成电路的计算机IBM360
1970年4月,英特尔公司的泰德·霍夫主持设计了世界上第一款商用计算机微处理器—“intel4004”。它在片上集成了2250个晶体管,每秒运算6万次,成本不到100美元,被视作“一件划时代的作品”。

-
大规模集成电路计算机时代(1972-至今)
特点:硬件方面,逻辑元件采用大规模和超大规模集成电路(LSI和VLSI)。软件方面出现了数据库管理系统、网络管理系统和面向对象语言等。1971年世界上第一台微处理器在美国硅谷诞生,开创了微型计算机的新时代。应用领域从科学计算、事务管理、过程控制逐步走向家庭。
由于集成技术的发展,半导体芯片的集成度更高,每块芯片可容纳数万乃至数百万个晶体管,并且可以把运算器和控制器都集中在一个芯片上、从而出现了微处理器,并且可以用微处理器和大规模、超大规模集成电路组装成微型计算机,就是我们常说的微电脑或PC机。微型计算机体积小,价格便宜,使用方便,但它的功能和运算速度已经达到甚至超过了过去的大型计算机。另一方面,利用大规模、超大规模集成电路制造的各种逻辑芯片,已经制成了体积并不很大,但运算速度可达一亿甚至几十亿次的巨型计算机。

1.2、计算机硬件组成
其中,CPU包括运算器和控制器,相当于计算机的大脑,是计算机的运算核心和控制核心。

(1) 运算器是用来进行数据运算加工的。运算器的主要部件:
(1)数据缓冲器:分为输入缓冲和输出缓冲,输入缓冲暂时存放外设送过来的数据,输出缓冲暂时存放送往外设的数据.
(2)ALU(算数逻辑单元):是运算器的主要部件,能完成常见的位运算(左移,右移,与,或非等)和算术运算(加减乘除等).
(3)状态字寄存器:存放运算状态(条件码,进位,溢出,结果正负等)和运算控制信息.
(4)通用寄存器:暂时存放或传送数据或指令,保存ALU的运算中间结果.
(2) 控制器是是计算机的指挥中心,负责决定执行程序的顺序,给出执行指令时机器各部件所需要的操作控制命令,用于协调和控制计算机的运行。控制器的主要部件:
(1)程序计数器(Program Counter):简称PC,用来存储从内存提取的下一条指令的地址.当CPU执行一条指令时,首先需要根据PC中存放的指令地址,将指令由内存取到指令寄存器中,此过程称为"取指令".与此同时,PC中的地址或自动加1或由转移指针给出下一条指令的地址,此后经过分析指令,执行指令,完成第一条指令的执行,而后根据PC取出第二条指令的地址,如此循环,执行每一条指令,保证程序能够连续地执行下去.
(2)时序发生器:用于发送时序脉冲,CPU依据不同的时序脉冲有节奏地进行工作,类似于CPU的节拍器.
(3)指令编译器:用于翻译指令及控制传输指令包含的数据.
(4)指令寄存器:用于缓存从内存或高速缓存里取出的指令,CPU执行指令时,就可以从指令寄存器中取出相关指令来进行执行.
(5)主存地址寄存器:保存当前CPU正要访问的内存单元的地址,通过总线跟主存通信.
(6)主存数据寄存器:保存当前CPU正要读或写的主存数据,通过总线与主存通信.
(7)通用寄存器:用于暂时存放或传送数据或指令.
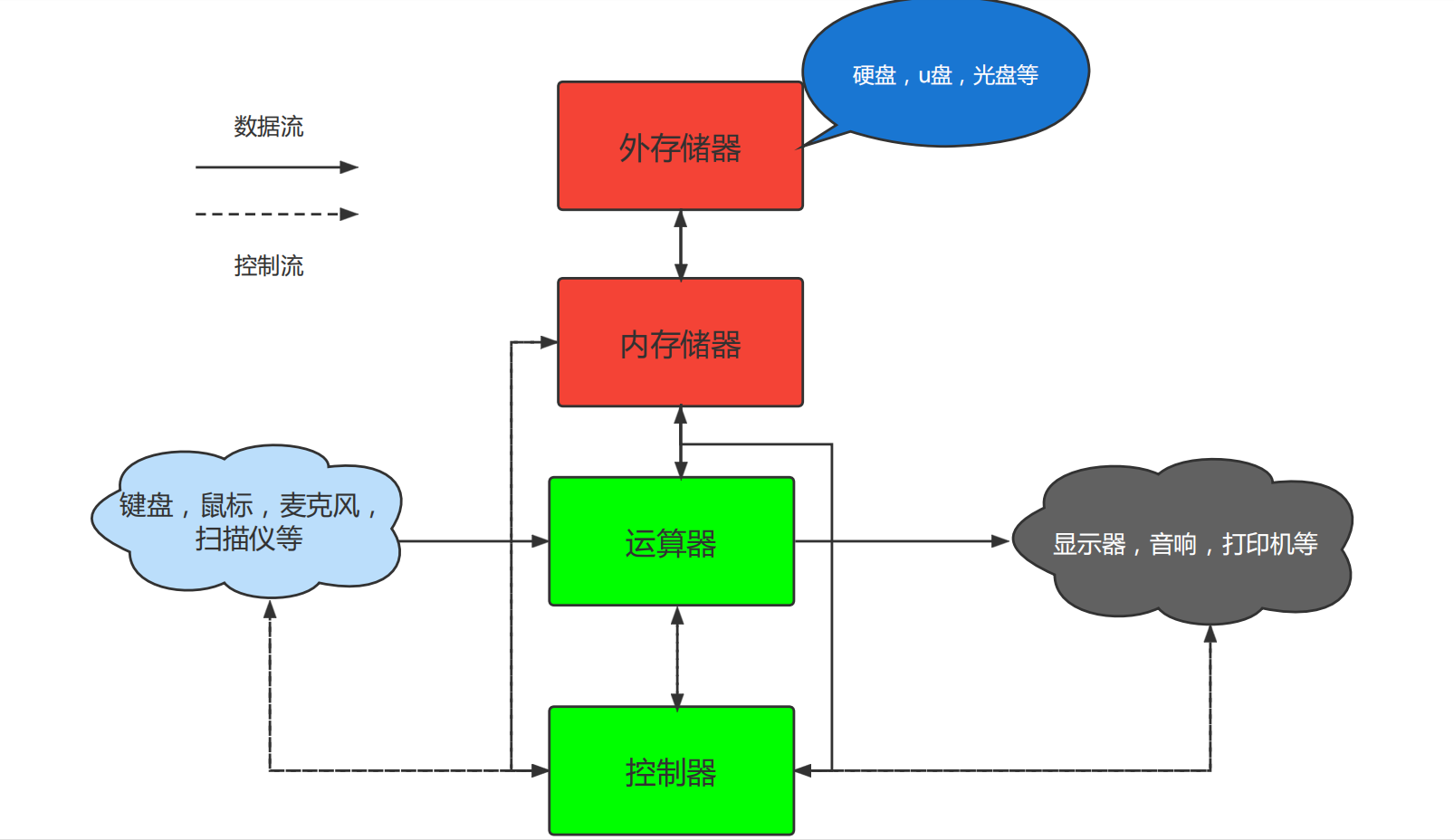
储存器可分为内储存器和外储存器两部分:内存属于内储存器,内存是CPU与硬盘之间的桥梁,只负责在CPU与硬盘之间做数据预存加速的功能。断电后即会被清除。输入设备的数据是从设备接口进去到端口缓冲器的,再经主板的输入输出总线(I/O总线)直接到CPU的,不经过内存。

外储存器是指除计算机内存及CPU缓存以外的储存器,此类储存器一般断电后仍然能保存数据。常见的外存储器有硬盘、软盘、光盘、U盘等。

输入设备就是键盘、鼠标、麦克风、扫描仪等等,向电脑输入信息。输入设备则相反,电脑向外部输出信息,如显示器、打印、音像、写入外存等。
1.3、冯-诺伊曼计算机

提到计算机,就不得不提及在计算机的发展史上做出杰出贡献的著名应用数学家冯诺依曼(Von Neumann,是他带领专家提出了一个全新的存储程序的通用电子计算机方案。这个方案规定了新机器由5个部分组成:运算器、逻辑控制装置、存储器、输入和输出。并描述了这5个部分的职能和相互关系。
早期的ENIAC有一个致命的缺点就是程序与计算两分离。在埃历阿克ENIAC尚未投入运行前,冯·诺依曼就已开始着手起草一份新的设计报告,要对这台电子计算机进行脱胎换骨的改造。他把新机器的方案命名为“离散变量自动电子计算机”,英文缩写译音是“埃德瓦克”(EDVAC)。1945年6月,冯·诺依曼与戈德斯坦、勃克斯等人,为埃德瓦克方案联名发表了一篇长达101页纸洋洋万言的报告,即计算机史上著名的“101页报告”。这份报告奠定了现代电脑体系结构坚实的根基,直到今天,仍然被认为是现代电脑科学发展里程碑式的文献。报告明确规定出计算机的五大部件**(输入系统、输出系统、存储器、运算器、控制器),并用二进制替代十进制运算**,大大方便了机器的电路设计。埃德瓦克方案的革命意义在于**“存储程序”**──程序也被当作数据存进了机器内部,以便电脑能自动依次执行指令,再也不必去接通什么线路。
人们后来把根据这一方案思想设计的机器统称为“诺依曼机”。自冯·诺依曼设计的埃德瓦克始,直到今天我们用“奔腾”芯片制作的多媒体计算机为止,电脑一代又一代的“传人”,大大小小千千万万台计算机,都没能够跳出诺依曼机的掌心。在这个意义上,冯·诺依曼是当之无愧的“计算机之父”。而
总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,它是由导线组成的传输线束, 按照计算机所传输的信息种类,计算机的总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。总线是一种内部结构,它是cpu、内存、输入、输出设备传递信息的公用通道,主机的各个部件通过总线相连接,外部设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统。
二、编程语言介绍
2.1、什么是编程语言
编程语言是用来控制计算机的一系列指令(Instruction),它有固定的格式和词汇(不同编程语言的格式和词汇不一样)。就像我们中国人之间沟通需要汉语,英国人沟通需要英语一样,人与计算机之间进行沟通需要一门语言作为介质,即编程语言。
编程语言的发展经历了机器语言(指令系统)=>汇编语言=>高级语言(C、java、Go等)。
- 计算机在设计中规定了一组指令(二级制代码),这组指令的集和就是所谓的机器指令系统,用机器指令形式编写的程序称为机器语言。
- 但由于机器语言的千上万条指令难以记忆,并且维护性和移植性都很差,所以在机器语言的基础上,人们提出了采用字符和十进制数代替二进制代码,于是产生了将机器语言符号化的汇编语言。
- 虽然汇编语言相较于机器语言简单了很多,但是汇编语言是机器指令的符号化,与机器指令存在着直接的对应关系,无论是学习还是开发,难度依然很大。所以更加接近人类语言,也更容易理解和修改的高级语言就应运而生了,高级语言的一条语法往往可以代替几条、几十条甚至几百条汇编语言的指令。因此,高级语言易学易用,通用性强,应用广泛。
2.2、编译型语言与解释性语言
计算机是不能理解高级语言的,更不能直接执行高级语言,它只能直接理解机器语言,所以使用任何高级语言编写的程序若想被计算机运行,都必须将其转换成计算机语言,也就是机器码。而这种转换的方式分为编译和解释两种。由此高级语言也分为编译型语言和解释型语言。
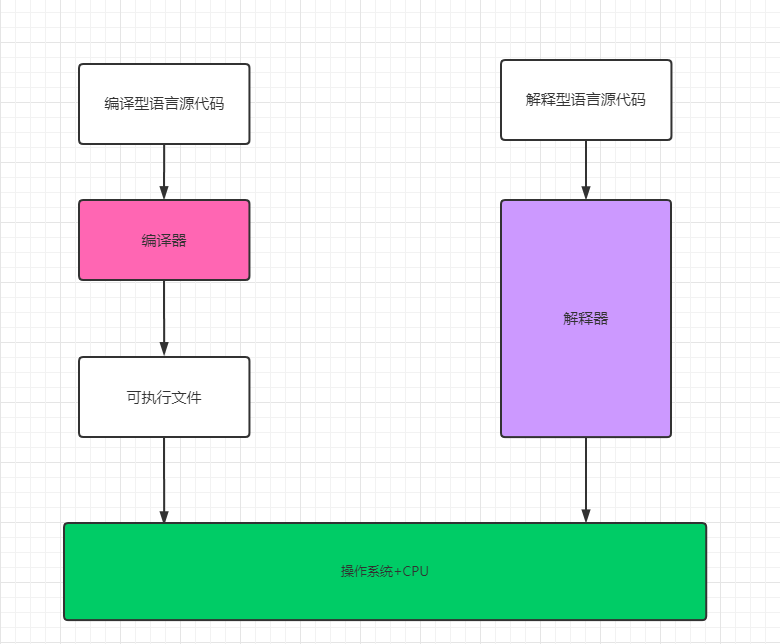
使用专门的编译器,针对特定的平台,将高级语言源代码一次性的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。
编译型语言写的程序执行之前,需要一个专门的编译过程,把源代码编译成机器语言的文件,如exe格式的文件,以后要再运行时,直接使用编译结果即可,如直接运行exe文件。因为只需编译一次,以后运行时不需要编译,所以编译型语言执行效率高。
1、一次性的编译成平台相关的机器语言文件,运行时脱离开发环境,运行效率高;
2、与特定平台相关,一般无法移植到其他平台;
使用专门的解释器对源程序逐行解释成特定平台的机器码并立即执行。是代码在执行时才被解释器一行行动态翻译和执行,而不是在执行之前就完成翻译。
1.解释型语言每次运行都需要将源代码解释称机器码并执行,执行效率低;
2.只要平台提供相应的解释器,就可以运行源代码,所以可以方便源程序移植;
三、Python语言介绍
3.1、了解Python语言
Python 是1989 年荷兰人 Guido van Rossum (简称 Guido)在圣诞节期间为了打发时间,发明的一门面向对象的解释性编程语言。Python来自Guido所挚爱的电视剧Monty Python’s Flying Circus。

Guido对于Python的设计理念就是一门介于shell和C之间的语言。可以像shell那样,轻松高效编程,也可以像C语言那样,能够全面调用计算机的功能接口。
python的设计哲学:优雅、明确、简洁。

3.2、Python解释器下载与安装
3.2.1、python解释器的分类
-
CPython:官方版本的解释器。这个解释器是用C语言开发的,所以叫CPython。CPython是使用最广的Python解释器。我们通常说的、下载的、讨论的、使用的都是这个解释器。
-
Ipython:基于CPython之上的一个交互式解释器,在交互方式上有所增强,执行Python代码的功能和CPython是完全一样的。CPython用»>作为提示符,而IPython用In [序号]:作为提示符。
-
PyPy:一个追求执行速度的Python解释器。采用JIT技术,对Python代码进行动态编译(注意,不是解释),可以显著提高Python代码的执行速度。绝大部分CPython代码都可以在PyPy下运行,但还是有一些不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。
-
Jython:运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
-
IronPython:和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
3.2.2、python解释器的版本
Python主要有三个版本:1994年发布的Python 1.0版本(淘汰)、2000年的2.0版本、以及08年发布的3.0版本。
Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
Python 2.5 - September 19, 2006
Python 2.6 - October 1, 2008
Python 2.7 - July 3, 2010
In November 2014, it was announced that Python 2.7 would be
supported until 2020, and reaffirmed that there would be no 2.8 release
as users were expected to move to Python 3.4+ as soon as possible
Python 3.0 - December 3, 2008
Python 3.1 - June 27, 2009
Python 3.2 - February 20, 2011
Python 3.3 - September 29, 2012
Python 3.4 - March 16, 2014
Python 3.5 - September 13, 2015
Python 3.6 - December 16,2016
3.2.3、python解释器的下载安装
Python 安装包下载地址:https://www.python.org/downloads/

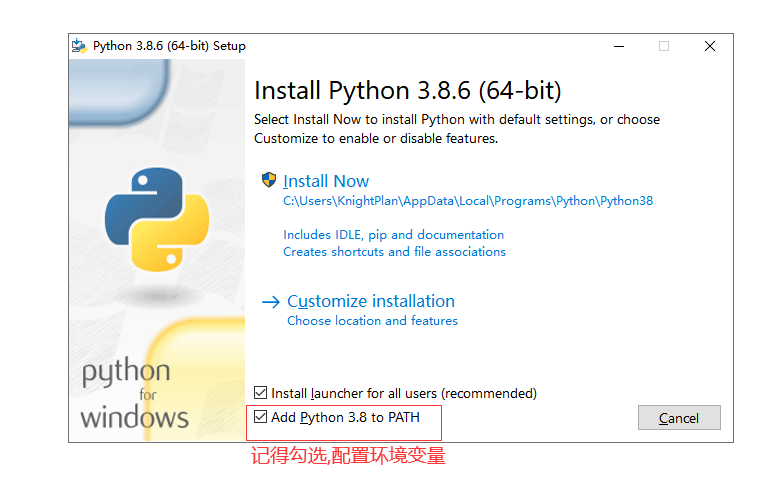
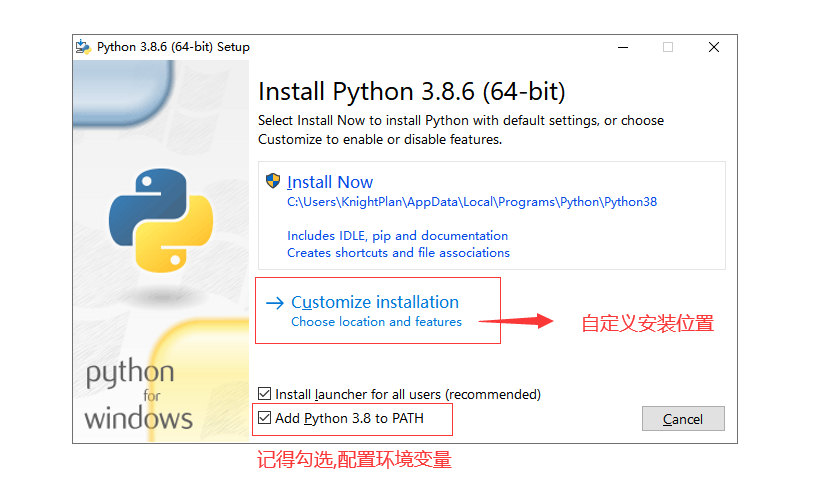

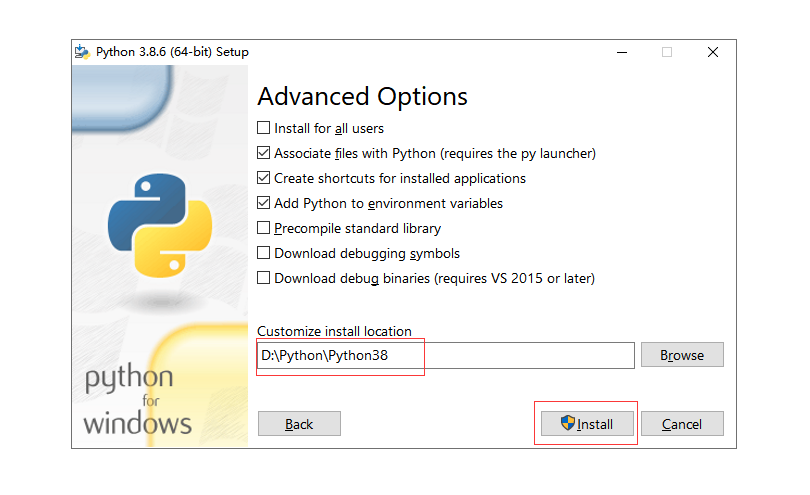

安装完成以后,打开 Windows 的命令行程序(命令提示符),在窗口中输入python命令(注意字母p是小写的),如果出现 Python 的版本信息,并看到命令提示符>>>,就说明安装成功了,如下图所示。
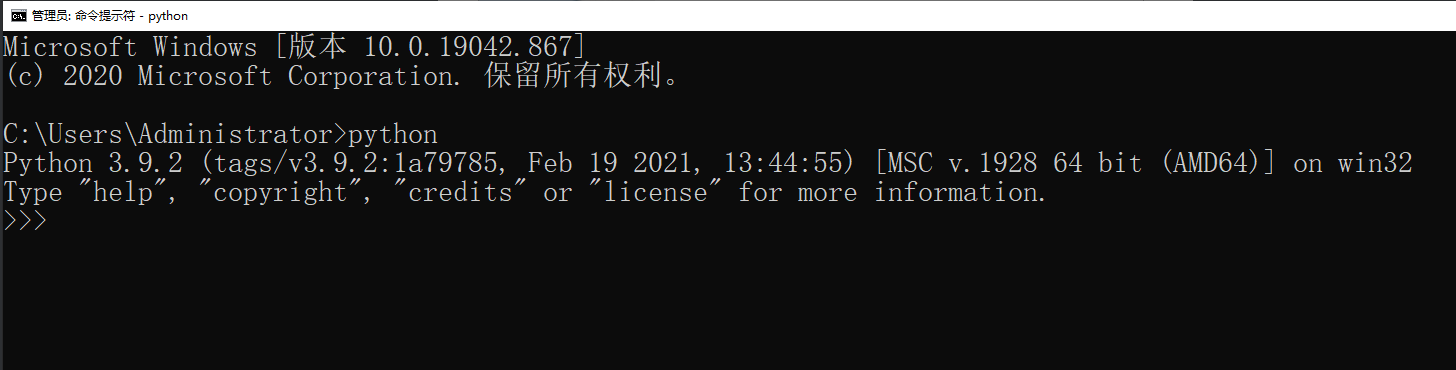
3.3、第一个Python程序
在任意位置创建一个文本文件,写下符合python语法的代码,比如print("hi,yuan!")
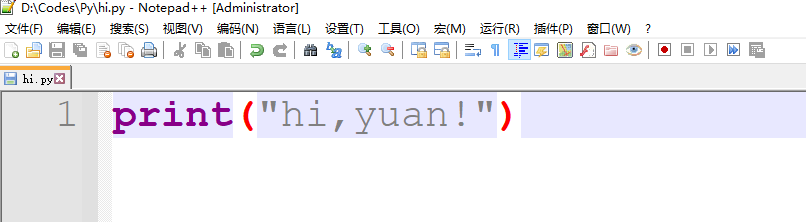
保存后在终端该路径下,通过python命令用python解释器执行该文件即可得到打印结果:
python python文件名
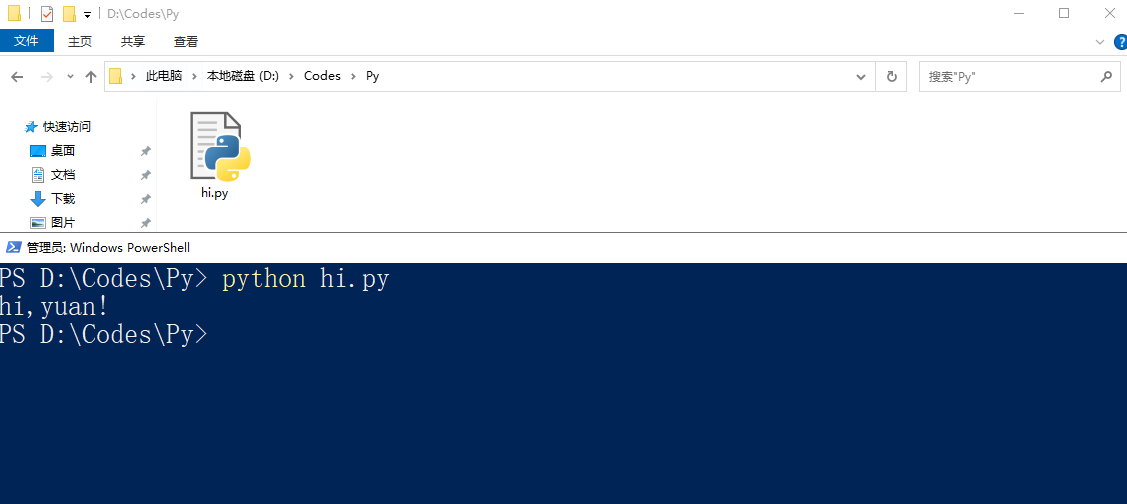
3.4、Pycharm的安装与使用
IDE 是 Intergreated Development Environment 的缩写,中文称为集成开发环境,用来表示辅助程序员开发的应用软件,是它们的一个总称。
PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
3.4.1、pycharm的安装
下载地址:https://www.jetbrains.com/pycharm/download/

3.4.2、IDE的快捷键
| 快捷键 |
作用 |
| Ctrl + / |
单行注释 |
| Ctrl + Shift + / |
多行注释 |
| Ctrl + D |
复制当前光标所在行 |
| Ctrl + X |
删除当前光标所在行 |
| Ctrl + Alt + L |
格式化代码 |
| Ctrl + Shift + F |
全局查找 |
| Ctrl + Alt + left/right |
返回至上次浏览的位置 |
| Ctrl + W |
快速选中代码 |
| Ctrl + R |
替换 |
四、基础语法
4.1、变量
4.1.1、python的标识符规范
简单地理解,标识符就是一个名字,就好像我们每个人都有属于自己的名字,它的主要作用就是作为变量、函数、类、模块以及其他对象的名称。Python中标识符的命名不是随意的,而是要遵守一定的命令规则
- 标识符是由字符(A~Z 和 a~z)、下划线和数字组成,但第一个字符不能是数字。
- 标识符不能和 Python 中的保留字相同。有关保留字,后续章节会详细介绍。
- Python中的标识符中,不能包含空格、@、% 以及 $ 等特殊字符。
- 在 Python 中,标识符中的字母是严格区分大小写
- Python 语言中,以下划线开头的标识符有特殊含义
- Python 允许使用汉字作为标识符(不推荐)
标识符的命名,除了要遵守以上这几条规则外,不同场景中的标识符,其名称也有一定的规范可循,例如:
1
2
3
4
5
6
7
8
|
'''
- 当标识符用作模块名时,应尽量短小,并且全部使用小写字母,使用下划线分割多个字母,例如 game_mian、game_register 等。
- 当标识符用作包的名称时,应尽量短小,也全部使用小写字母,不推荐使用下划线,例如 com.mr、com.mr.book 等。
- 当标识符用作类名时,应采用单词首字母大写的形式。例如,定义一个图书类,可以命名为 Book。
- 模块内部的类名,可以采用 "下划线+首字母大写" 的形式,如 _Book;
- 函数名、类中的属性名和方法名,应全部使用小写字母,多个单词之间可以用下划线分割;
- 常量命名应全部使用大写字母,单词之间可以用下划线分割;
'''
|
4.1.2、python的关键字
| and |
as |
assert |
break |
class |
continue |
| def |
del |
elif |
else |
except |
finally |
| for |
from |
False |
global |
if |
import |
| in |
is |
lambda |
nonlocal |
not |
None |
| or |
pass |
raise |
return |
try |
True |
| while |
with |
yield |
|
|
|
4.1.3、变量
变量是一段有名字的连续存储空间。我们通过定义变量来申请并命名这样的存储空间,并通过变量的名字来使用这段存储空间。在编程语言中,将数据放入变量的过程叫做赋值(Assignment)。Python 使用等号=作为赋值运算符,具体格式为:
变量名 = 任意类型的值
例如:
1
2
3
4
|
x = 10
y = "hi,yuan"
z = True
x = "hello world"
|
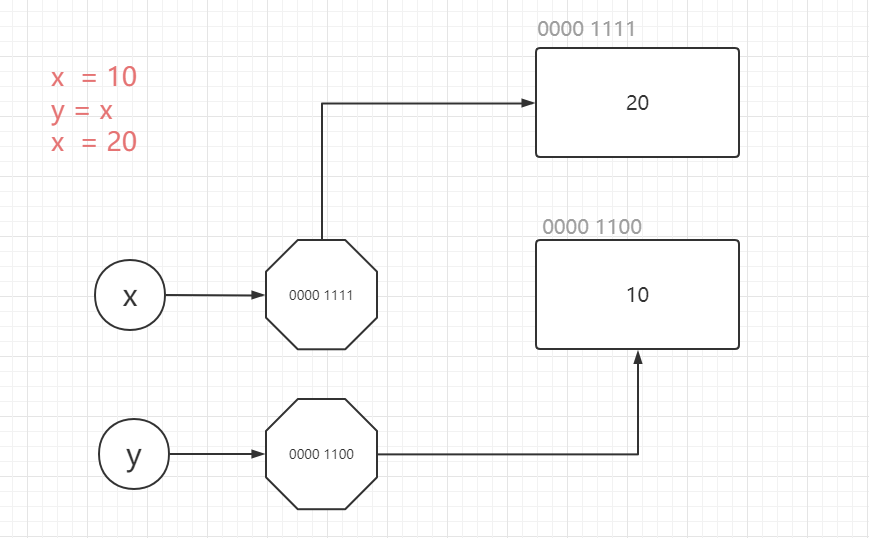
python作为动态语言的代表,是不同于C语言等静态语言的变量存储原理的
1
2
3
4
|
x = 10
print(id(x))
x = 20
print(id(x))
|
4.2、基本语法
(1)注释
注释就是对代码的解释和说明,其目的是让人们能够更加轻松地了解代码。注释是编写程序时,写程序的人给一个语句、程序段、函数等的解释或提示,能提高程序代码的可读性。一般情况下,合理的代码注释应该占源代码的 1/3 左右。
注释只是为了提高公认阅读,不会被解释器执行。
Python 支持两种类型的注释,分别是单行注释和多行注释。
1
2
3
4
5
|
# 单行注释
"""
这是一个多行注释
三引号里面的任何内容不会被解释器执行
"""
|
(2)语句分隔符
就像我们写作文一样,逗号、句号等语句分隔符是非常重要的,程序也一样,要想让解释器能读懂,语句和语句之间一定要有分隔符。在C、Java等语言的语法中规定,必须以分号作为语句结束的标识。Python也支持分号,同样用于一条语句的结束标识。但在Python中分号的作用已经不像C、Java中那么重要了,Python中的分号可以省略,主要通过换行来识别语句的结束。
(3)缩进
和其它程序设计语言(如 Java、C 语言)采用大括号“{}”分隔代码块不同,Python 采用冒号( : )和代码缩进和来区分代码块之间的层次。在 Python 中,对于类定义、函数定义、流程控制语句、异常处理语句等,行尾的冒号和下一行的缩进,表示下一个代码块的开始,而缩进的结束则表示此代码块的结束。
注意,Python 中实现对代码的缩进,可以使用空格或者 Tab 键实现。但无论是手动敲空格,还是使用 Tab 键,通常情况下都是采用 4 个空格长度作为一个缩进量(默认情况下,一个 Tab 键就表示 4 个空格)。
(4)Python编码规范(PEP 8)
Python 采用 PEP 8 作为编码规范,其中 PEP 是 Python Enhancement Proposal(Python 增强建议书)的缩写,8 代表的是 Python 代码的样式指南。下面仅给大家列出 PEP 8 中初学者应严格遵守的一些编码规则:
1、不要在行尾添加分号,也不要用分号将两条命令放在同一行
2、通常情况下,在运算符两侧、函数参数之间以及逗号两侧,都建议使用空格进行分隔。
3、使用必要的空行可以增加代码的可读性,通常在顶级定义(如函数或类的定义)之间空两行,而方法定义之间空一行,另外在用于分隔某些功能的位置也可以空一行。
4.3、基本数据类型
4.3.1、整型和浮点型
在python中整数都属于整型,不同于C语言会根据整数的大小将整型分类为short、int、long、long long 四种类型,python只有一种整型,即int类型,无论整型数字多大多小都属于int。
1
2
|
x = 10
print(type(x)) # <class 'int'>
|
说道整型,就不得不提到整型数字之间进制。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 十六进制
print(0x11)
print(0x111)
# 二进制
print(0b101)
print(0B101)
# 八进制
print(0o12)
print(0o23)
# 十进制转换为二进制
print(bin(3))
# 十进制转换为十六进制
print(hex(19))
# 十进制转换为八进制
print(oct(10))
|
在python中小数都属于浮点型(float),有两种表现形式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 小数点形式
f = 3.14
print(f) # 3.14
print(type(f)) # <class 'float'>
# 指数形式: aEn 或 aen
'''
3.2E5 = 3.2×105,其中 3.2 是尾数,5 是指数。
2.7E-3 = 2.7×10-2,其中 2.7 是尾数,-3 是指数。
0.2E8 = 0.2×107,其中 0.2 是尾数,8 是指数。
'''
f1 = 3.2E5
print(f1) # 320000.0
print(type(f1)) # <class 'float'>
f2 = 3.2E-5
print(f2) # 3.2e-05
print(type(f2)) # <class 'float'>
f3 = 3.1415926123456789876543217789
print(f3) # 双精度(double float,保留17为有效数字)
print(type(f3))
|
4.3.2、布尔类型
布尔型(Boolean)是一种数据的类型,这种类型只有两种值,即"真"与"假"。在python中用 bool表示布尔类型,“真"用关键字true表示,“假"用false表示。
1
2
3
4
5
6
|
print(4 == 2) # False
print(5 > 1) # True
name = "yuan"
print(name == "alvin") # False
print(1 == "1") # False
|
不光表达式的结果是布尔值,任意值都有自己的布尔值,这就涉及到布尔的零值。
1
2
3
4
5
6
7
8
9
10
|
# 任意数据类型都一个具体值的布尔值为False,我们称为零值。该类型的其他值的布尔值皆为True。
print(bool("")) # 字符串的零值 “”
print(bool(0)) # 整型的零值 0
print(bool(False)) # 布尔类型的零值 False
print(bool("0"))
print(bool("-1"))
print(bool("yuan"))
print(bool(-1))
print(bool(0.1))
|
4.3.3、字符串
字符串是由零个或多个字符组成的有限序列。字符串的内容可以包含字母、标点、特殊符号、中文、日文等全世界的所有字符。
在python中字符串是通过单引号''或者双引号""标识的。
1
2
3
4
5
6
7
8
|
s1 = "hi yuan"
print(s1)
s2 = ""
print(s2)
s3 = 'yuan老师是最帅的老师!'
print(s3)
|
Python 字符串中的双引号和单引号没有任何区别!
(1)字符串的转义符
| 转义字符 |
说明 |
| \n |
换行符,将光标位置移到下一行开头。 |
| \r |
回车符,将光标位置移到本行开头。 |
| \t |
水平制表符,也即 Tab 键,一般相当于四个空格。 |
| \a |
蜂鸣器响铃。注意不是喇叭发声,现在的计算机很多都不带蜂鸣器了,所以响铃不一定有效。 |
| \b |
退格(Backspace),将光标位置移到前一列。 |
| \ |
反斜线 |
| ' |
单引号 |
| " |
双引号 |
| \ |
在字符串行尾的续行符,即一行未完,转到下一行继续写。 |
1
2
3
4
5
6
7
8
|
s1 = "hi yuan\nhi,alvin"
print(s1)
s2 = 'I\'m yuan'
print(s2)
s3 = "D:\\nythonProject\\nenv\\Scripts\\python.exe"
print(s3)
|
(2)长字符串
1
2
3
4
5
6
7
|
s = """
s = "hi yuan\\nhi,alvin"
I'm yuan
这是一个python解释器路径:"D:\\nythonProject\\nenv\Scripts\python.exe"
长字符串中放置单引号或者双引号不会导致解析错误
"""
print(s)
|
(3)格式化输出
之前讲到过 print() 函数的用法,这只是最简单最初级的形式,print() 还有很多高级的玩法,比如格式化输出。
1
2
3
|
name = "yuan"
age = 23
print("My name is %s; My age is %d"%(name,age))
|
在 print() 函数中,由引号包围的是格式化字符串,它相当于一个字符串模板,可以放置一些转换说明符(占位符)。本例的格式化字符串中包含一个%s和%d说明符,它最终会被后面的name和age 变量的值所替代。中间的%是一个分隔符,它前面是格式化字符串,后面是要输出的表达式。
print() 函数使用以%开头的转换说明符对各种类型的数据进行格式化输出,具体请看下表。
| 转换说明符 |
解释 |
| %d、%i |
转换为带符号的十进制整数 |
| %o |
转换为带符号的八进制整数 |
| %x、%X |
转换为带符号的十六进制整数 |
| %e |
转化为科学计数法表示的浮点数(e 小写) |
| %E |
转化为科学计数法表示的浮点数(E 大写) |
| %f、%F |
转化为十进制浮点数 |
| %g |
智能选择使用 %f 或 %e 格式 |
| %G |
智能选择使用 %F 或 %E 格式 |
| %c |
格式化字符及其 ASCII 码 |
| %r |
使用 repr() 函数将表达式转换为字符串 |
| %s |
使用 str() 函数将表达式转换为字符串 |
(4)归属序列类型
字符串属于序列类型,所谓序列,指的是一块可存放多个值的连续内存空间,这些值按一定顺序排列,可通过每个值所在位置的编号(称为索引)访问它们。

Python 还支持索引值是负数,此类索引是从右向左计数,换句话说,从最后一个元素开始计数,从索引值 -1 开始,如图 所示。

序列类型支持的操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# (1)索引取值
s = "hello yuan"
print(s[6])
print(s[-10])
# (2)切片取值:序列类型对象[start : end : step]
s = "hello yuan"
print(s[1:4]) # ell :取索引1到索引3(左闭又开)
print(s[:4]) # hell :start缺省,默认从0取
print(s[1:]) # ello yuan : end缺省,默认取到最后
print(s[1:-1]) # ello yua
print(s[6:9]) # yua
print(s[-4:-1]) # yua
print(s[-1:-4]) # 空
print(s[-1:-4:-1]) #nau step为1:从左向右一个一个取。为-1 ,从右向左一个取
# (3)判断存在:Python 中,可以使用 in 关键字检查某元素是否为序列的成员。
s = "hello yuan"
print("yuan" in s) # True
# (4)支持两种类型相同的序列使用“+”运算符做相加操作,它会将两个序列进行连接,但不会去除重复的元素。
# 使用数字 n 乘以一个序列会生成新的序列,其内容为原来序列被重复 n 次的结果
s = "hello"+" yuan"
print(s) # hello yuan
s= "*"*10
print(s) # **********
|
(5)内置方法(重点)
| 方法 |
作用 |
示例 |
输出 |
upper |
全部大写 |
"hello".upper() |
"HELLO" |
lower |
全部小写 |
"Hello".lower() |
"hello" |
startswith() |
是否以a开头 |
"Yuan".startswith("Yu") |
True |
endswith() |
是否以a结尾 |
"Yuan".endswith("a") |
False |
isdigit() |
是否全数字 |
'123'.isdigit() |
True |
isalpha() |
是否全字母 |
'yuan123'.isalpha() |
False |
isalnum() |
是否全为字母或数字 |
'yuan123'.isalnum() |
True |
strip() |
去两边空格 |
" hi yuan \n".strip() |
"hi yuan" |
join() |
将多个字符串连接在一起 |
"-".join(["yuan","alvin","eric"]) |
"yuan-alvin-eric" |
split() |
按某字符分割字符串,默认按空格分隔 |
"yuan-alvin-eric".split("-") |
['yuan', 'alvin', 'eric'] |
find() |
搜索指定字符串,没有返回-1 |
"hello world".index("w") |
6 |
index() |
同上,但是找不到会报错 |
"hello world".index("w") |
6 |
count() |
统计指定的字符串出现的次数 |
"hello world".count("l") |
3 |
replace() |
替换old为new |
'hello world'.replace(‘world',‘python') |
"hello python" |
format() |
格式化方法 |
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# 任意数据对象.方法()实现对数据的某种操作
# 不同数据类型对象支持不同方法
# 字符串类型对象支持哪些方法
s1 = "yuan"
s2 = "RAIN"
# (1) upper方法和lower方法
s3 = s1.upper()
s4 = s2.lower()
print(s3) # "YUAN"
print(s4) # "rain"
s5 = "hello yuan"
s6 = "hi world"
# (2) startswith和endswith:判断字符串是否以什么开头和结尾
print(s5.startswith("hello")) # True
print(s6.startswith("hello")) # False
print(s6.startswith("hi wor")) # True
print(s6.endswith("hi wor")) # False
# (3) isdigit(): 判断字符串是否是一个数字字符串
s7 = "123"
s8 = "123A"
print(s7.isdigit()) # True
print(s8.isdigit()) # False
s9 = "123SAA%#"
print(s9.isalnum()) # False 不能包含特殊符号
# (4) strip(): 去除两端空格和换行符号
s10 = " I am yuan "
print(s10)
print(s10.strip())
name = input("请输入姓名>>").strip()
print(name)
# (5) split分割方法: 将一个字符串分割成一个列表
s11 = "rain-yuan-alvin-eric"
print(s11.split("-")) # ['rain', 'yuan', 'alvin', 'eric']
# (6) join方法: 将一个列表中的字符串拼接成一个字符串
names_list = ['rain', 'yuan', 'alvin', 'eric']
s12 = "-".join(names_list) # 用什么分隔符拼接names_list列表
print(s12,type(s12)) # "rain-yuan-alvin-eric"
|
4.3.4、类型转换
1
2
3
4
5
|
i = int("3")
print(i,type(i)) # 3 <class 'int'>
s = str(3.14)
print(s,type(s)) # 3.14 <class 'str'>
|
4.4、运算符
4.4.1、算数运算符
| 运算符 |
说明 |
实例 |
结果 |
| + |
加 |
1+1 |
2 |
| - |
减 |
1-1 |
0 |
| * |
乘 |
1*3 |
3 |
| / |
除法(和数学中的规则一样) |
4/2 |
2 |
| // |
整除(只保留商的整数部分) |
7 // 2 |
3 |
| % |
取余,即返回除法的余数 |
7 % 2 |
1 |
| ** |
幂运算/次方运算,即返回 x 的 y 次方 |
2 ** 4 |
16,即 24 |
4.4.2、赋值运算符
| 运算符 |
说 明 |
用法举例 |
等价形式 |
| = |
最基本的赋值运算 |
x = y |
x = y |
| += |
加赋值 |
x += y |
x = x + y |
| -= |
减赋值 |
x -= y |
x = x - y |
| *= |
乘赋值 |
x *= y |
x = x * y |
| /= |
除赋值 |
x /= y |
x = x / y |
| %= |
取余数赋值 |
x %= y |
x = x % y |
| **= |
幂赋值 |
x **= y |
x = x ** y |
| //= |
取整数赋值 |
x //= y |
x = x // y |
| &= |
按位与赋值 |
x &= y |
x = x & y |
| |= |
按位或赋值 |
x |= y |
x = x | y |
| ^= |
按位异或赋值 |
x ^= y |
x = x ^ y |
| «= |
左移赋值 |
x «= y |
x = x « y,这里的 y 指的是左移的位数 |
| »= |
右移赋值 |
x »= y |
x = x » y,这里的 y 指的是右移的位数 |
4.4.3、比较运算符
| 比较运算符 |
说明 |
| > |
大于,如果>前面的值大于后面的值,则返回 True,否则返回 False。 |
| < |
小于,如果<前面的值小于后面的值,则返回 True,否则返回 False。 |
| == |
等于,如果==两边的值相等,则返回 True,否则返回 False。 |
| >= |
大于等于(等价于数学中的 ≥),如果>=前面的值大于或者等于后面的值,则返回 True,否则返回 False。 |
| <= |
小于等于(等价于数学中的 ≤),如果<=前面的值小于或者等于后面的值,则返回 True,否则返回 False。 |
| != |
不等于(等价于数学中的 ≠),如果!=两边的值不相等,则返回 True,否则返回 False。 |
| is |
判断两个变量所引用的对象是否相同,如果相同则返回 True,否则返回 False。 |
| is not |
判断两个变量所引用的对象是否不相同,如果不相同则返回 True,否则返回 False。 |
4.4.4、逻辑运算符
| 逻辑运算符 |
含义 |
基本格式 |
说明 |
| and |
逻辑与运算 |
a and b |
当 a 和 b 两个表达式都为真时,a and b 的结果才为真,否则为假。 |
| or |
逻辑或运算 |
a or b |
当 a 和 b 两个表达式都为假时,a or b 的结果才是假,否则为真。 |
| not |
逻辑非运算 |
not a |
如果 a 为真,那么 not a 的结果为假;如果 a 为假,那么 not a 的结果为真。相当于对 a 取反。 |
1
2
3
|
print(2>1 and 1==2) # False
print(not 3<5) # False
print(not(4<2) or 1==2) # True
|
值得注意的是逻辑运算符有一套很好玩的短路算法
1
2
3
4
|
print(2 and 1)
print(0 and 1)
print(0 or 1)
print(3 or 5)
|
4.5、输入输出函数
(1)print函数
**print()**用于打印输出,是python中最常见的一个函数。
1
2
3
4
5
6
7
8
9
10
11
12
|
def print(self, *args, sep=' ', end='\n', file=None): # known special case of print
"""
print(value, ..., sep=' ', end='\n', file=sys.stdout, flush=False)
Prints the values to a stream, or to sys.stdout by default.
Optional keyword arguments:
file: a file-like object (stream); defaults to the current sys.stdout.
sep: string inserted between values, default a space.
end: string appended after the last value, default a newline.
flush: whether to forcibly flush the stream.
"""
pass
|
以上信息说明input函数在python中是一个内建函数,其从标准输入中读入一个字符串,并自动忽略换行符。也就是说所有形式的输入按字符串处理,如果想要得到其他类型的数据进行强制类型转化。
1
2
3
4
|
name = input("您的姓名:")
age = input("您的年龄:")
print(name,type(name))
print(age,type(age))
|
4.6、章节练习题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
"""
1. 分析下面代码的运行结果?
x = 10
y = x
y = 20
print(x)
print(y)
2. 用print打印出下面内容:
文能提笔安天下,
武能上马定乾坤。
心存谋略何人胜,
古今英雄唯是君。
3. 利用 input函数,连续输入两个数字求和?
4. 分别使用%占位符以及format方法两种方式制作趣味模板程序需求:
等待用户输名字、地址、爱好,
根据用户的名字和爱好进任意格式化输出
如:敬爱可亲的xxx,最喜欢在xxx地方法xxx
5. 有 names = " 张三 李四 王五 赵六 "
将names字符串中所有的名字放在一个列表中
6. 查找字符串" 张三 李四 王五 赵六 "王五的索引位置
7. 将十进制1025分别转换为二进制,八进制以及十六进制
8. 将"goods"与"food"以及"meat"拼接为完整路径,即"/goods/food/meat/"
9. s = "hello world"切片操作
(1) s[1:4]
(2) s[-1:-4]
(3) 打印"world"如何切片
10. "1" == 1的结果是什么?结果是什么数据类型
"""
|
五、流程控制语句
程序是由语句构成,而流程控制语句 是用来控制程序中每条语句执行顺序的语句。可以通过控制语句实现更丰富的逻辑以及更强大的功能。几乎所有编程语言都有流程控制语句,功能也都基本相似。
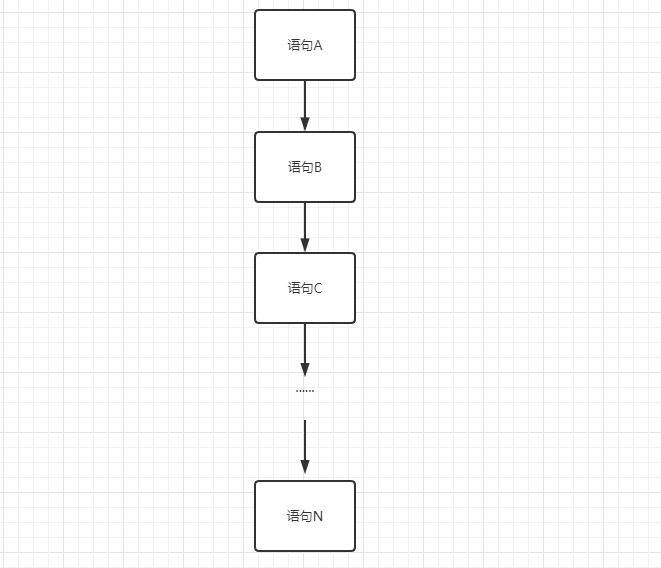
其流程控制方式有
这里最简单最常用的就是顺序结构,即语句从上至下一一执行。
1
2
|
print("OK")
print("not OK") # 从上到下依次执行
|
5.1、分支语句
顺序结构的程序虽然能解决计算、输出等问题,但不能做判断再选择。对于要先做判断再选择的问题就要使用分支结构。
5.1.1、单分支语句
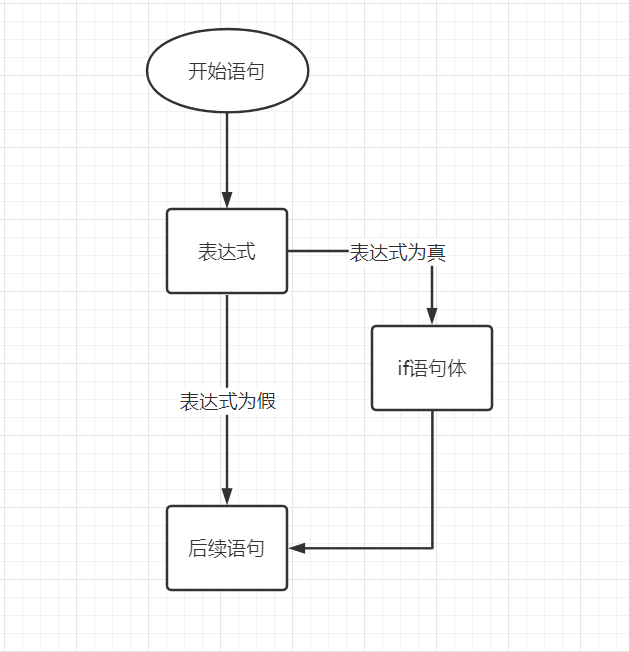
语法:
1
2
3
4
5
6
7
8
9
10
11
|
'''
if 表达式:
代码块
'''
user = input("用户名>>")
pwd = input("密码>>")
if user == "root" and pwd == "123": # 返回一个布尔值
print("登录成功") # 强烈建议使用四个缩进
print("程序结束")
|
说明:
1、“表达式”可以是一个单一的值或者复杂语句,形式不限,但解释器最后会通过bool获取一个true或者false的布尔值
2、“代码块”由:与具由相同缩进标识的若干条语句组成(一般是四个缩进)。
5.1.2、双分支语句
双分支语句顾名思义,二条分支二选一执行!
语法格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
'''
if 表达式:
代码块 1
else:
代码块 2
'''
user = input("用户名>>")
pwd = input("密码>>")
if user == "root" and pwd == "123": # 返回一个布尔值
print("登录成功") # 强烈建议使用四个缩进
print("祝贺你")
else:
print("登录失败")
print("不好意思")
|
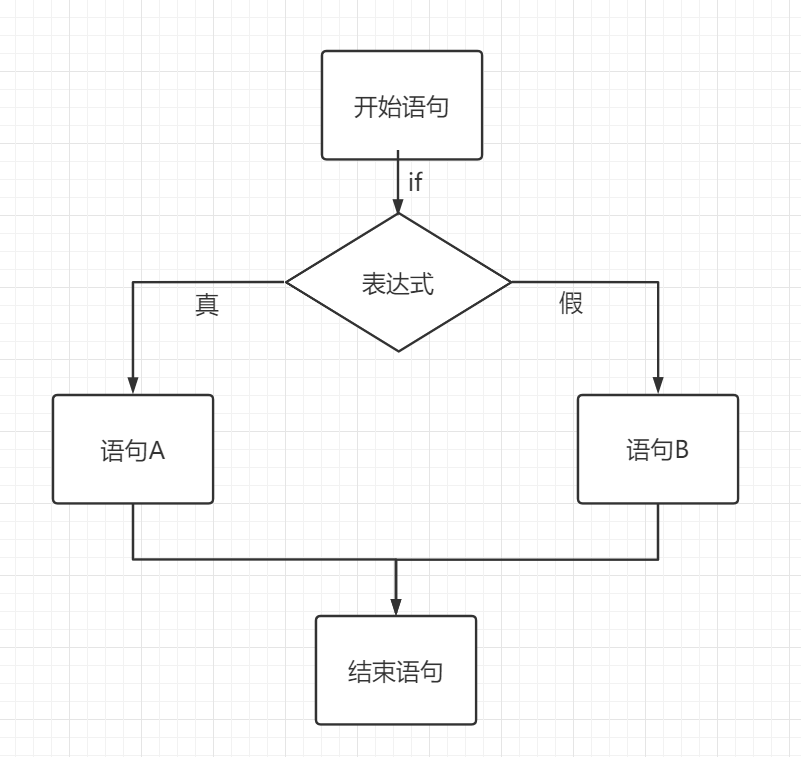
5.1.3、多分支语句
多分支即从比双分支更多的分支选择一支执行。
语法格式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
'''
if 表达式 1:
代码块 1
elif 表达式 2:
代码块 2
elif 表达式 3:
代码块 3
...# 其它elif语句
else:
代码块 n
'''
score = input("请输入您的成绩>>") # "100"
# 当成绩大于90的时候显示优秀,否则显示一般
# 将数字字符串,比如"100",转换成一个整型数字的时候,需要int转换
score = int(score) # 100
if score > 100 or score < 0:
print("您的输入有误!")
elif score > 90:
print("成绩优秀")
elif score > 70: # else if
print("成绩良好")
elif score > 60:
print("成绩及格")
else:
print("成绩不及格")
|

5.1.4、if嵌套
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
score = input("请输入您的成绩>>") # "100"
if score.isdigit():
score = int(score) # 100
if score > 100 or score < 0:
print("您的输入有误!")
elif score > 90:
print("成绩优秀")
elif score > 70: # else if
print("成绩良好")
elif score > 60:
print("成绩及格")
else:
print("成绩不及格")
else:
print("请输入一个数字")
|
5.2、循环语句
在不少实际问题中有许多具有规律性的重复操作,因此在程序中就需要重复执行某些语句。一组被重复执行的语句称之为循环体,能否继续重复,决定循环的终止条件。
Python语言中的循环语句支持 while循环(条件循环)和for循环(遍历循环)。
5.2.1、while循环
语法:
1
2
3
4
|
'''
while 表达式:
循环体
'''
|
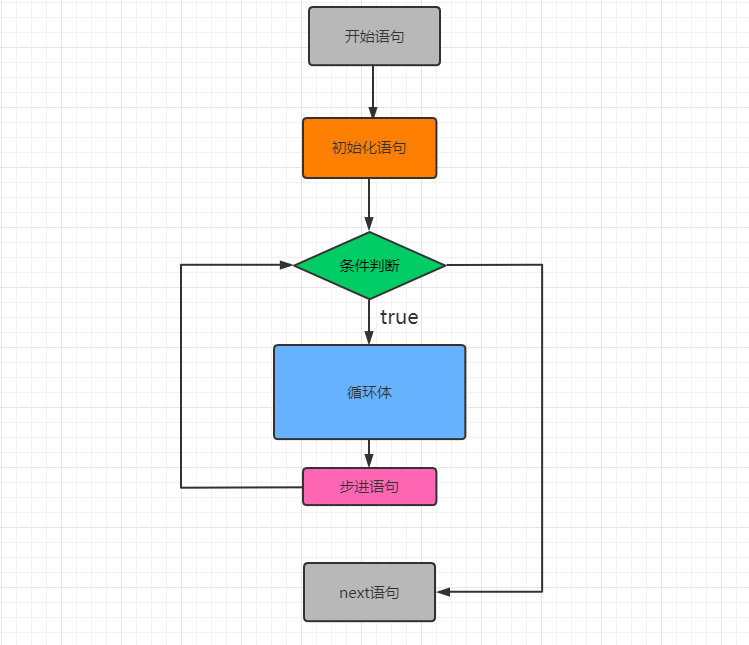
(1)无限循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 案例1
while 1:
print("OK") # 无限循环打印OK,这样使用没有什么意义
# 案例2
while 1:
score = input("请输入您的成绩>>") # "100"
if score.isdigit():
score = int(score) # 100
if score > 100 or score < 0:
print("您的输入有误!")
elif score > 90:
print("成绩优秀")
elif score > 70: # else if
print("成绩良好")
elif score > 60:
print("成绩及格")
else:
print("成绩不及格")
else:
print("请输入一个数字")
|
(2)限定次数循环
循环打印十遍"hello world”
1
2
3
4
5
|
count = 0 # 初始化语句
while count < 10: # 条件判断
print("hello world")
count+=1 # 步进语句
print("end")
|
5.2.2、for循环
for 循环的语法格式如下:
1
2
3
4
|
'''
for 迭代变量 in 字符串|列表|元组|字典|集合:
代码块
'''
|
格式中,迭代变量用于存放从序列类型变量中读取出来的元素,所以一般不会在循环中对迭代变量手动赋值;代码块指的是具有相同缩进格式的多行代码(和 while 一样),由于和循环结构联用,因此代码块又称为循环体。
1
2
3
4
5
6
7
8
|
for i in "hello world":
print(i)
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # [1,2,3,4,5,6,7,8,9] range函数: range(start,end,step)
print(i)
|
5.2.3、退出循环
如果想提前结束循环(在不满足结束条件的情况下结束循环),可以使用break或continue关键字。
当 break 关键字用于 for 循环时,会终止循环而执行整个循环语句后面的代码。break 关键字通常和 if 语句一起使用,即满足某个条件时便跳出循环,继续执行循环语句下面的代码。
不同于break退出整个循环,continue指的是退出当次循环。
1
2
3
4
5
6
7
8
|
while 1:
num = int(input("num>>"))
for i in range(1, num + 1):
# if i > 100:
if i == 6:
# break
continue
print(i)
|
配合debug模式理解
5.2.4、循环嵌套
在一个循环体语句中又包含另一个循环语句,称为循环嵌套
在控制台上打印一个如下图所示的正方形
*****
*****
*****
*****
*****
1
2
3
4
|
for i in range(5):
for j in range(5):
print("*",end="")
print("")
|
在控制台上打印一个如下图所示的三角形
*
**
***
****
*****
1
2
3
4
|
for i in range(5):
for j in range(i+1):
print("*",end="")
print("")
|
5.3、练习题
5.3.1、随堂练习
1
2
3
4
5
6
7
8
9
10
11
12
|
# 1、计算1-100的累计和
# 2、猜数游戏
'''
程序随机内置一个位于一定范围内的数字作为猜测的结果,由用户猜测此数字。用户每猜测一次,由系统提示猜测结果:太大了、太小了或者猜对了,直到用户猜对结果或者猜测次数用完导致失败。
设定一个理想数字比如:66,
让用户三次机会猜数字,如果比66大,则显示猜测的结果大了;
如果比66小,则显示猜测的结果小了;
只有等于66,显示猜测结果正确,退出循环。
最多三次都没有猜测正确,退出循环,并显示‘都没猜对,继续努力’。
'''
|
5.3.2、课后作业
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
'''
1、求偶数元素的和[1,2,1,2,3,3,6,5,8]
2、写代码:计算 1 - 2 + 3 - 4 + ... + 99 中除了88以外所有数的总和?
3、求1+2!+3!+4!+……+10!的和.
4、斐波那契数列指的是这样一个数列 0, 1, 1, 2, 3, 5, 8, 13,特别指出:第0项是0,第1项是第一个1。从第三项开始,每一项都等于前两项之和。
计算索引为10的斐波那契数列对应的值
5、打印菱形小星星
*
***
*****
*******
*********
***********
***********
*********
*******
*****
***
*
'''
|
六、重要数据类型
6.1、列表
6.1.1、列表声明
在实际开发中,经常需要将一组(不只一个)数据存储起来,以便后边的代码使用。列表就是这样的一个数据结构。
列表会将所有元素都放在一对中括号[ ]里面,相邻元素之间用逗号,分隔,如下所示:
[element1, element2, element3, ..., elementn]
不同于C,java等语言的数组,python的列表可以存放不同的,任意的数据类型对象。
1
2
3
4
5
6
|
l = [123,"yuan",True]
print(l,type(l))
# 注意
a,b = [1,2]
print(a,b)
|
6.1.2、序列操作
列表是 Python 序列的一种,我们可以使用索引(Index)访问列表中的某个元素(得到的是一个元素的值),也可以使用切片访问列表中的一组元素(得到的是一个新的子列表)。
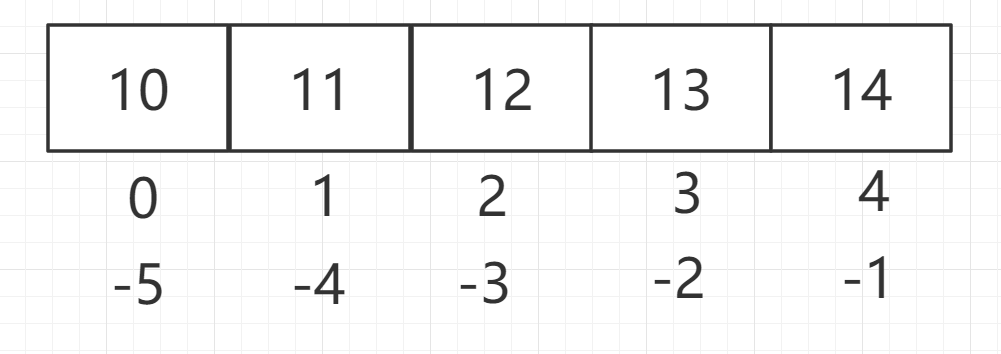
1
2
3
|
l = [10,11,12,13,14]
print(l[2]) # 12
print(l[-1]) # 14
|
1
2
3
4
5
6
7
8
9
10
11
|
l = [10,11,12,13,14]
print(l[2:5])
print(l[-3:-1])
print(l[:3])
print(l[1:])
print(l[:])
print(l[2:4])
print(l[-3:-1])
print(l[-1:-3])
print(l[-1:-3:-1])
print(l[::2])
|
1、取出的元素数量为:结束位置 - 开始位置;
2、取出元素不包含结束位置对应的索引,列表最后一个元素使用 list[len(slice)] 获取;
3、当缺省开始位置时,表示从连续区域开头到结束位置;
4、当缺省结束位置时,表示从开始位置到整个连续区域末尾;
5、两者同时缺省时,与列表本身等效;
6、step为正,从左向右切,为负从右向左切。
in 关键字检查某元素是否为序列的成员
1
2
3
|
l = [10,11,12,13,14]
print(20 in l) # False
print(12 in l) # True
|
1
2
3
|
l1 = [1,2,3]
l2 = [4,5,6]
print(l1+l2) # [1, 2, 3, 4, 5, 6]
|
1
2
3
4
5
6
7
8
9
|
for name in ["张三",'李四',"王五"]:
print(name)
for i in range(10): # range函数: range(start,end,step)
print(i)
# 基于for循环从100打印到1
for i in range(100,0,-1):
print(i)
|
6.1.3、列表内置方法
| 方法 |
作用 |
示例 |
结果 |
append() |
向列表追加元素 |
l.append(4) |
l:[1, 2, 3, 4] |
insert() |
向列表任意位置添加元素 |
l.insert(0,100) |
l:[100, 1, 2, 3] |
extend() |
向列表合并一个列表 |
l.extend([4,5,6]) |
l:[1, 2, 3, 4, 5, 6] |
pop() |
根据索引删除列表元素(为空删除最后一个元素) |
l.pop(1) |
l:[1, 3] |
remove() |
根据元素值删除列表元素 |
l.remove(1) |
l:[2, 3] |
clear() |
清空列表元素 |
l.clear() |
l:[] |
sort() |
排序(升序) |
l.sort() |
l:[1,2,3] |
reverse() |
翻转列表 |
l.reverse() |
l:[3,2,1] |
count() |
元素重复的次数 |
l.count(2) |
返回值:1 |
index() |
查找元素对应索引 |
l.index(2) |
返回值:1 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
# 增删改查: [].方法()
# (1) ******************************** 增(append,insert,extend) ****************
l1 = [1, 2, 3]
# append方法:追加一个元素
l1.append(4)
print(l1) # [1, 2, 3, 4]
# insert(): 插入,即在任意位置添加元素
l1.insert(1, 100) # 在索引1的位置添加元素100
print(l1) # [1, 100, 2, 3, 4]
# 扩展一个列表:extend方法
l2 = [20, 21, 22, 23]
# l1.append(l2)
l1.extend(l2)
print(l1) # [1, 100, 2, 50, 3, 4,[20,21,22,23]]
# 打印列表元素个数python内置方法:
print(len(l1))
# (2) ******************************** 删(pop,remove,clear) **********************
l4 = [10, 20, 30, 40, 50]
# 按索引删除:pop,返回删除的元素
# ret = l4.pop(2)
# print(ret)
# print(l4) # [10, 20, 40, 50]
# 按着元素值删除
l4.remove(30)
print(l4) # [10, 20, 40, 50]
# 清空列表
l4.clear()
print(l4) # []
# (3) ******************************** 修改(没有内置方法实现修改,只能基于索引赋值) ********
l5 = [10, 20, 30, 40, 50]
# 将索引为1的值改为200
l5[1] = 200
print(l5) # [10, 200, 30, 40, 50]
# 将l5中的40改为400 ,step1:查询40的索引 step2:将索引为i的值改为400
i = l5.index(40) # 3
l5[i] = 400
print(l5) # [10, 20, 30, 400, 50]
# (4) ******************************** 查(index,sort) *******************************
l6 = [10, 50, 30, 20,40 ]
l6.reverse() # 只是翻转 [40, 20, 30, 50, 10]
print(l6) # []
# # 查询某个元素的索引,比如30的索引
# print(l6.index(30)) # 2
# 排序
# l6.sort(reverse=True)
# print(l6) # [50, 40, 30, 20, 10]
|
6.1.4、可变和不可变数据类型
Python的数据类型可以分为可变数据类型(列表和字典)和不可变数据类型(整型、浮点型、字符串、布尔类型以及元组)。
可变类型:在id(内存地址)不变的情况下,value(值)可以变,则称为可变类型
不可变类型:value(值)一旦改变,id(内存地址)也改变,则称为不可变类型(id变,意味着创建了新的内存空间)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# (1)
x = 10
print(id(x))
x = 100
print(id(x))
s = "yuan"
print(id(s))
s= "alvin"
print(id(s))
# (2)
# l = [1,2,3]
# print(id(l))
# l = [1,2,3,4]
# print(id(l))
# (3)
l = [1,2,3]
print(id(l))
l[0] = 10
print(id(l))
print(l)
l.append(4)
print(l)
|
6.1.5、深浅拷贝
深浅拷贝是python中经常涉及到一个面试,也是同学们经常出错的地方,那么什么是深浅拷贝呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# 案例1:变量赋值
l1 = [1,2,3]
l2 = l1 # 不是拷贝,完全指向一块内存空间
print(id(l1))
print(id(l2))
l2[1] = 200
print(l1)
# 案例2
l1 = [1, 2, 3]
l2 = [4, 5, l1]
l1[0] = 100
print(l2)
# 案例3:浅拷贝:两种方式:切片和copy方法
l1 = [1,2,3,["yuan","alvin"]]
l2 = l1.copy() # 等同于l2 = l1[:]
print(id(l1))
print(id(l2))
l2[1] = 200
print(l1)
l2[3][0] = "张三"
print(l1)
#案例4: 深拷贝
import copy
l1 = [1,2,3,["yuan","alvin"]]
l2 = copy.deepcopy(l1)
l2[3][0] = "张三"
print(l1)
|
6.1.6、列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
1
|
variable = [表达式 for 迭代变量 in 可迭代对象 [if 条件表达式] ]
|
[if 条件表达式] 不是必须的,可以使用,也可以省略。
例如: 计算1-100中所有偶数的平方
1
2
3
|
# 计算1-100中所有偶数的平方
new_l = [i * i for i in range(100) if i % 2 == 0]
print(new_l)
|
以上所看到的列表推导式都只有一个循环,实际上它可使用多个循环,就像嵌套循环一样。
练习1:
1
2
3
4
|
old = [[1, 2], [3, 4], [5, 6]]
# 从old中一个一个取出值,对取出的值(i)再进行一次遍历取值操作(也可以进行判断或者运算)
new = [j for i in old for j in i]
print(new)
|
练习2:
1
2
3
4
|
l1 = [1, 2, 3]
l2 = [4, 5, 6]
ret = [[i,j] for i in l1 for j in l2]
print(ret) # [[1, 4], [1, 5], [1, 6], [2, 4], [2, 5], [2, 6], [3, 4], [3, 5], [3, 6]]
|
6.2、元组
6.2.1、声明元组
Python的元组与列表类似,不同之处在于元组的元素只能读,不能修改。通常情况下,元组用于保存无需修改的内容。
元组使用小括号表示,声明一个元组:
1
|
(element1, element2, element3, ..., elementn)
|
需要注意的一点是,当创建的元组中只有一个字符串类型的元素时,该元素后面必须要加一个逗号,,否则 Python 解释器会将它视为字符串。
1
2
|
l = (1,2,3)
print(l,type(l)) # (1, 2, 3) <class 'tuple'>
|
6.2.2、序列操作
和列表一样,支持索引和切片操作。
1
2
3
4
5
|
l = (1,2,3,4,5)
print(l[2]) # 3
print(l[2:4]) # (3, 4)
print(l[:4]) # (1, 2, 3, 4)
print(2 in l)
|
6.2.3、内置方法
1
2
3
|
l = (1,2,3,4,5)
print(l.count(3))
print(l.index(2))
|
6.3、字典
字典是Python提供的唯一内建的映射(Mapping Type)数据类型。
6.3.1、声明字典
python使用 { } 创建字典,由于字典中每个元素都包含键(key)和值(value)两部分,因此在创建字典时,键和值之间使用冒号:分隔,相邻元素之间使用逗号,分隔,所有元素放在大括号{ }中。
使用{ }创建字典的语法格式如下:
1
|
dictname = {'key':'value1', 'key2':'value2', ...}
|
1、同一字典中的各个键必须唯一,不能重复。
2、字典是键值对是无序的,但在3.6版本后,字典默认做成有序的了,这是新的版本特征。
6.3.2、字典的基本操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# (1) 查键值
print(book["title"]) # 返回字符串 西游记
print(book["authors"]) # 返回列表 ['rain', 'yuan']
# (2) 添加或修改键值对,注意:如果键存在,则是修改,否则是添加
book["price"] = 299 # 修改键的值
book["publish"] = "北京出版社" # 添加键值对
# (3) 删除键值对 del 删除命令
print(book)
del book["publish"]
print(book)
del book
print(book)
# (4) 判断键是否存在某字典中
print("price" in book)
# (5) 循环
for key in book:
print(key,book[key])
|
6.3.3、字典的内置方法
1
|
d = {"name":"yuan","age":18}
|
| 方法 |
作用 |
示例 |
结果 |
get() |
查询字典某键的值,取不到返回默认值 |
d.get("name",None) |
"yuan" |
setdefault() |
查询字典某键的值,取不到给字典设置键值,同时返回设置的值 |
d.setdefault("age",20) |
18 |
keys() |
查询字典中所有的键 |
d.keys() |
['name','age'] |
values() |
查询字典中所有的值 |
d.values() |
['yuan', 18] |
items() |
查询字典中所有的键和值 |
d.items() |
[('name','yuan'), ('age', 18)] |
pop() |
删除字典指定的键值对 |
d.pop(“age”) |
{'name':'yuan'} |
popitem() |
删除字典最后的键值对 |
d.popitem() |
{'name':'yuan'} |
clear() |
清空字典 |
d.clear() |
{} |
update() |
更新字典 |
t={"gender":"male","age":20}d.update(t) |
{'name':'yuan','age': 20, 'gender': 'male'} |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
dic = {"name": "yuan", "age": 22, "sex": "male"}
# (1)查字典的键的值
print(dic["names"]) # 会报错
name = dic.get("names")
sex = dic.get("sexs", "female")
print(sex)
print(dic.keys()) # 返回值:['name', 'age', 'sex']
print(dic.values()) # 返回值:['yuan', 22, 'male']
print(dic.items()) # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# setdefault取某键的值,如果能取到,则返回该键的值,如果没有改键,则会设置键值对
print(dic.setdefault("name")) # get()不会添加键值对 ,setdefault会添加
print(dic.setdefault("height", "180cm"))
print(dic)
# (2)删除键值对 pop popitem
sex = dic.pop("sex") # male
print(sex) # male
print(dic) # {'name': 'yuan', 'age': 22}
dic.popitem() # 删除最后一个键值对
print(dic) # {'name': 'yuan'}
dic.clear() # 删除键值对
# (3) 添加或修改 update
add_dic = {"height": "180cm", "weight": "60kg"}
dic.update(add_dic)
print(dic) # {'name': 'yuan', 'age': 22, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}
update_dic = {"age": 33, "height": "180cm", "weight": "60kg"}
dic.update(update_dic)
print(dic) # {'name': 'yuan', 'age': 33, 'sex': 'male', 'height': '180cm', 'weight': '60kg'}
# (4) 字典的循环
dic = {"name": "yuan", "age": 22, "sex": "male"}
# 遍历键值对方式1
# for key in dic: # 将每个键分别赋值给key
# print(key, dic.get(key))
# 遍历键值对方式2
# for i in dic.items(): # [('name', 'yuan'), ('age', 22), ('sex', 'male')]
# print(i[0],i[1])
# 关于变量补充
# x = (10, 20)
# print(x, type(x)) # (10, 20) <class 'tuple'>
# x, y = (10, 20)
# print(x, y)
for key, value in dic.items():
print(key, value)
|
6.3.4、字典的进阶使用
字典属于可变数据类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 案例1
stu01 = {"name": "rain"}
stus = {1001: stu01}
print(stus)
stu01["name"] = "alvin"
print(stus)
print(id(stus[1001]))
stus[1001] = {"name": "eric"}
print(stu01)
print(id(stus[1001]))
# 案例2
students_dict= {}
scores_dict = {
"chinese": 100,
"math": 90,
"english": 50,
}
stu_dic = {
"name": "rain",
"scores": scores_dict
}
students_dict[1002] = stu_dic
print(students_dict)
scores_dict["math"] = 0
print(students_dict)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
# 案例1:列表存放字典
data = [
{"name": "rain", "age": 22},
{"name": "eric", "age": 32},
{"name": "alvin", "age": 24},
]
# 循环data,每行按着格式『姓名:rain,年龄:22』将每个学生的信息逐行打印
for stu_dic in data: # data是一个列表
# print(stu_dic) #
print("『姓名:%s,年龄:%s』" % (stu_dic.get("name"), stu_dic.get("age")))
# 将data中第二个学生的年龄查询出来
print(data[1].get("age"))
# 案例2:
data2 = {
1001: {"name": "rain", "age": 22},
1002: {"name": "eric", "age": 32},
1003: {"name": "alvin", "age": 24},
}
# 循环data2,每行按着格式『学号1001, 姓名:rain,年龄:22』将每个学生的信息逐行打印
for stu_id, stu_dic in data2.items():
# print(stu_id,stu_dic)
name = stu_dic.get("name")
age = stu_dic.get("age")
print("『学号: %s, 姓名 %s,年龄:%s』" % (stu_id, name, age))
# name = "yuan"
# age = 22
# sex = "male"
#
# print("『姓名:", name, "年龄:", age, "性别:", sex, "』")
# print("『姓名: %s 年龄: %s 性别: %s 』" % (name, age, sex))
# print("姓名:name")
|
6.3.5、字典生成式
同列表生成式一样,字典生成式是用来快速生成字典的。通过直接使用一句代码来指定要生成字典的条件及内容,替换了使用多行条件或者是多行循环代码的传统方式。
格式:
{字典内容+循环条件+判断条件}
1
2
3
|
stu = {"id": "1001", "name": "alvin", "age": 22, "score": 100, "weight": "50kg"}
stu = {k: v for k, v in stu.items() if k == "score" or k == "name"}
print(stu)
|
练习:将一个字典中的键值倒换
1
2
3
|
dic = {"1": 1001, "2": 1002, "3": 1003}
new_dic = {v: k for k, v in dic.items()}
print(new_dic)
|
练习:将所有的key值变为大写
1
|
print({k.upper():v for k,v in d.items()})
|
6.3.5、字典的hash存储
hash:百度百科
Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的输入(又叫做预映射pre-image)通过散列算法变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
字典对象的核心其实是个散列表,而散列表是一个稀疏数组(不是每个位置都有值),每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用,由于,所有bucket结构和大小一致,我们可以通过偏移量来指定bucket的位置
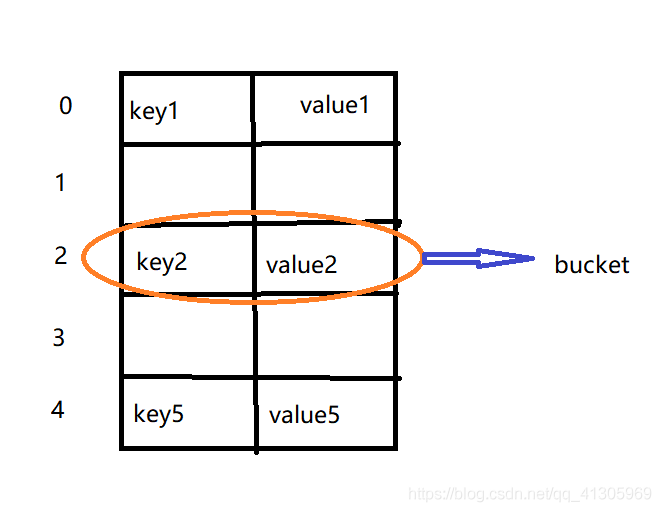
将一对键值放入字典的过程:
先定义一个字典,再写入值
1
2
|
d = {}
d["name"] = "yuan"
|
在执行第二行时,第一步就是计算"name"的散列值,python中可以用hash函数得到hash值,再将得到的值放入bin函数,返回int类型的二进制
1
|
print(bin(hash("name")))
|
结果为:
0b111111010001111101010011011000111110111101101110101100100101100
假设数组长度为10,我们取出计算出的散列值,最右边3位数作为偏移量,即100,十进制是数字4,我们查看偏移量为4对应的bucket的位置是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量101,十进制是数字5,再查看偏移量5的bucket是否为空,直到单元为空的bucket将键值放进去。以上就是字典的存储原理
当进行字典的查询时:
1
2
|
d["name"]
d.get("name")
|
第一步与存储一样,先计算键的散列值,取出后三位111,十进制为4的偏移量,找到对应的bucket的位置,查看是否为空,如果为空就返回None,不为空就获取键并计算键的散列值,计算后将刚计算的散列值与要查询的键的散列值比较,相同就返回对应bucket位置的value,不同就往前再取三位重新计算偏移量,依次取完后还是没有结果就返回None
参考文章
6.4、集合
Python 中的集合,和数学中的集合概念一样。由不同可hash的不重复的元素组成的集合。
6.4.1、声明集合
Python 集合会将所有元素放在一对大括号 {} 中,相邻元素之间用“,”分隔,如下所示:
1
|
{element1,element2,...}
|
其中,elementn 表示集合中的元素,个数没有限制。
从内容上看,同一集合中,只能存储不可变的数据类型,包括整形、浮点型、字符串、元组,无法存储列表、字典、集合这些可变的数据类型,否则 Python 解释器会抛出 TypeError 错误。
由于集合中的元素是无序的,因此无法向列表那样使用下标访问元素。Python 中,访问集合元素最常用的方法是使用循环结构,将集合中的数据逐一读取出来。
1
2
3
|
s = {"zhangsan",18,"male"}
for item in s:
print(item)
|
6.4.2、内置方法
1
2
|
a = {1,2,3}
b = {3,4,5}
|
| 方法 |
作用 |
示例 |
结果 |
add() |
向集合添加元素 |
a.add(4) |
{1, 2, 3, 4} |
update() |
向集合更新一个集合 |
`a.update({3,4,5}) |
{1, 2, 3, 4, 5} |
remove() |
删除集合中的元素 |
a.remove(2) |
{1, 3} |
discard() |
删除集合中的元素 |
a.discard(2) |
{1, 3} |
pop() |
随机删除集合一个元素 |
a.pop() |
{2,3} |
clear() |
清空集合 |
a.clear() |
{} |
intersection() |
返回两个集合的交集 |
a.intersection(b) |
{3} |
difference() |
返回两个集合的差集 |
a.difference(b)b.difference(a) |
{1,2}{4,5} |
symmetric_difference() |
返回两个集合的对称差集 |
a.symmetric_difference(b) |
{1, 2, 4, 5} |
union() |
返回两个集合的并集 |
a.union(b) |
{1, 2, 3, 4, 5} |
6.5、章节练习题
6.5.1、列表练习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 1. l1 = [1, 2, 3, 4, 5]
# (1)在l1的元素3后面插入300
# (2)删除元素2
# (3)将5更改为500
# (4)将2,3,4切片出来
# (5)l1[-3:-5]的结果
# (6)l1[-3:]的结果
# 2. 通过input引导用户输入一个姓名,判断该姓名是否存在于列表names中
# names = ["yuan","eric","alvin","george"]
# 3. l = [1,2,3,[4,5]]
# (1)将4修改为400
# (2)在l的[4,5]列表中追加一个6,即使l变为[1,2,3,[4,5,6]]
# 4. 数一下字符串"天津 北京 上海 深圳 大连"中的城市个数
# 5. 将字符串"56,45,6,7,2,88,12,100"转换为按顺序显示的"2 6 7 12 45 56 88 100"
|
6.5.2、字典练习
学生成绩管理系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
# 确定数据以什么数据类型和格式进行存储
students_dict = {
1001: {
"name": "yuan",
"scores": {
"chinese": 100,
"math": 89,
"english": 100,
}
},
1002: {
"name": "rain",
"scores": {
"chinese": 100,
"math": 100,
"english": 100,
}
},
}
while 1:
print('''
1. 查看所有学生成绩
2. 添加一个学生成绩
3. 修改一个学生成绩
4. 删除一个学生成绩
5. 退出程序
''')
choice = input("请输入您的选择:")
if choice == "1":
# 查看所有学生信息
print("*" * 60)
for sid, stu_dic in students_dict.items():
# print(sid,stu_dic)
name = stu_dic.get("name")
chinese = stu_dic.get("scores").get("chinese")
math = stu_dic.get("scores").get("math")
english = stu_dic.get("scores").get("english")
print("学号:%4s 姓名:%4s 语文成绩:%4s 数学成绩%4s 英文成绩:%4s" % (sid, name, chinese, math, english))
print("*" * 60)
elif choice == "2":
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if int(sid) in students_dict: # 该学号已经存在!
print("该学号已经存在!")
else: # # 该学号不存在!
break
name = input("请输入学生姓名>>>")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 构建学生字典
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
stu_dic = {
"name": name,
"scores": scores_dict
}
print("stu_dic", stu_dic)
students_dict[int(sid)] = stu_dic
elif choice == "3":
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if int(sid) in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 修改学生成绩
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
students_dict.get(int(sid)).update({"scores": scores_dict})
print("修改成功")
elif choice == "4":
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if int(sid) in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
students_dict.pop(int(sid))
print("删除成功")
elif choice == "5":
# 退出程序
break
else:
print("输入有误!")
|
七、函数
设计一个程序:
期待结果:
*
***
*****
*******
*********
***********
*********
*******
*****
***
*
*
***
*****
*******
*********
***********
*********
*******
*****
***
*
如果没有函数,我们的实现方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 打印一个菱形
rows=6
i=j=k=1
#菱形的上半部分
for i in range(rows):
for j in range(rows-i):
print(" ",end=" ")
j+=1
for k in range(2*i-1):
print("*",end=" ")
k+=1
print("\n")
#菱形的下半部分
for i in range(rows):
for j in range(i):
print(" ",end=" ")
j+=1
for k in range(2*(rows-i)-1):
print("*",end=" ")
k+=1
print("\n")
|
相信大家一定看出来了,这种方式会出现大量重复代码,对于阅读和维护整个程序都会变得十分麻烦。
这时候,函数就出现了!
简单说,函数就是一段封装好的,可以重复使用的代码,它使得我们的程序更加模块化,避免大量重复的代码。
刚才的程序函数版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
def print_ling():
rows=6
i=j=k=1
#菱形的上半部分
for i in range(rows):
for j in range(rows-i):
print(" ",end=" ")
j+=1
for k in range(2*i-1):
print("*",end=" ")
k+=1
print("\n")
#菱形的下半部分
for i in range(rows):
for j in range(i):
print(" ",end=" ")
j+=1
for k in range(2*(rows-i)-1):
print("*",end=" ")
k+=1
print("\n")
print_ling()
print_ling()
|
7.1、函数声明
声明一个函数,也就是创建一个函数,可以理解为将一段可以重复使用的代码通过关键字def包裹起来。具体的语法格式如下:
1
2
3
4
5
6
7
8
9
10
|
'''
def 函数名(参数列表):
'''
# 函数文档
params:
return:
'''
# 实现特定功能的多行代码
[return [返回值]]
'''
|
其中,用 [] 括起来的为可选择部分,即可以使用,也可以省略。此格式中,各部分参数的含义如下:
- 函数名:一个符合 Python 语法的标识符,最好见名知意,多个单词可以使用
_表示,比如cal_sum
- 形参列表:设置该函数可以接收多少个参数,多个参数之间用逗号( , )分隔。
- [return [返回值] ]:整体作为函数的可选参参数,用于设置该函数的返回值。
- python的函数体是通过冒号+缩进声明的
1
2
|
def foo():
print("foo函数")
|
7.2、函数调用
函数的声明并没有执行函数中的代码块,想要执行函数体,需要进行函数调用,一个函数可以调用多次。
函数调用语法:
1
2
3
4
|
def foo():
print("foo函数")
foo()
|
debug模式运行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
# 函数的声明
def bar():
print("bar1")
print("bar2")
print("bar3")
# 函数的声明
def foo():
print("foo1")
print("foo2")
print("foo3")
# 函数调用
foo()
# 函数调用
bar()
# 函数调用
foo()
|
7.3、函数参数
像上面我们举的例子,我想打印一个八层菱形和六层菱形,怎么设计?
7.3.1、形参和实参
声明一个计算1-100和的函数
1
2
3
4
5
|
def cal_sum():
ret = 0
for i in range(1,101):
ret+=i
print(ret)
|
但是问题来了,如果我想计算1-200的和怎么呢,再声明一个新的函数吗?明显我们会发现计算1-100和与计算1-200的和逻辑是相同的,只有一个动态变化值,所以我们引入了参数的概念,这样可以使函数的功能更加强大灵活:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# 案例1
def cal_sum(temp): # temp就是引入的函数形式参数
ret = 0
for i in range(1,temp+1):
ret+=i
print(ret)
cal_sum(100) # 每次调用可以根据需要传入需要的值,这个具体的值成为实际参数简称实参。
cal_sum(101)
# 案例2
def add():
x = 10
y = 20
print(x+y)
def add(x, y): # 声明的参数称之为形式参数,简称形参
print(x + y)
# 调用add函数 # 将调用过程中传入的值称之为实际参数,简称实参
add(5, 6) # 将5赋值给x,将6赋值给了y ,函数体将x+y,即5+6计算出来,打印
# 调用add函数
add(10, 5) # 将10赋值给x,将6赋值给了5 ,函数体将x+y,即10+5计算出来,打印
|
在函数的定义阶段 括号内写的变量名,叫做该函数的形式参数,简称形参。在函数的调用阶段,括号内实际传入的值,叫做实际参数,简称实参。该例中,temp就是的函数形式参数,而每次调用根据需要传入的值,比如100,101都是实参。
形参就相当于变量名,而实参就相当于变量的值,函数调用传参的过程 就是给形参变量名赋值的过程。
函数参数只有在函数调用阶段有效,函数运行结束,参数作为垃圾释放。
7.3.2、位置参数
位置参数,有时也称必备参数,指的是必须按照正确的顺序将实际参数传到函数中,换句话说,调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 例1
def add(x,y): # x,y是形参,用来接收实参
print(x+y)
add(2,3) # 2,3 是实际参数,分别传递给形参x,y
# 例2
def add(x,y,z):
print(x+y)
add(2,3) # 缺少一个实际参数传递给z
# 例3
def add(x,y):
print(x+y)
add(2,3,4) # 缺少一个形式参数接收给z
|
7.3.3、默认参数
Python 允许为参数设置默认值,即在定义函数时,直接给形式参数指定一个默认值。这样的话,即便调用函数时没有给拥有默认值的形参传递参数,该参数可以直接使用定义函数时设置的默认值。
1
2
3
4
5
6
7
|
def print_stu_info(name,age,gender="male"):
print("学员姓名:",name)
print("学员年龄:",age)
print("学员性别:",gender)
print_stu_info("张三",23)
|
当定义一个有默认值参数的函数时,有默认值的参数必须位于所有没默认值参数的后面,否则报错!
7.3.4、关键字参数
关键字参数可以避免牢记参数位置的麻烦,令函数的调用和参数传递更加灵活方便。关键字参数是指使用形式参数的名字来确定输入的参数值。通过此方式指定函数实参时,不再需要与形参的位置完全一致,只要将参数名写正确即可。
1
2
3
4
5
6
7
8
9
10
11
12
|
def print_stu_info(name,age,height,weight,job):
print("学员姓名:",name)
print("学员年龄:",age)
print("学员身高:",height)
print("学员体重:",weight)
print("学员工作:",job)
print_stu_info("张三",23,"180cm","80kg","销售")
print_stu_info(name="张三",height="180cm",weight="90kg",job="销售",age=23)
print_stu_info("张三",height="180cm",weight="90kg",job="销售",age=23)
|
使用位置参数和关键字参数混合传参的方式。但需要注意,混合传参时关键字参数必须位于所有的位置参数之后。
7.3.5、不定长参数
在函数定义中使用*args和**kwargs传递可变长参数。*args用作传递非命名键值可变长参数列表(位置参数);**kwargs用作传递键值可变长参数列表。*args 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数。**kwargs的参数会以字典的形式导入。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# *args
def add(*args):
print(args)
print(type(args))
ret = 0
for i in args:
ret += i
print(ret)
add(12,23,45)
# **kwargs
def print_stu_info(**kwargs,):
print(kwargs)
print_stu_info(name="张三",height=190)
|
同时使用*args和**kwargs:
1
2
3
4
5
6
|
def print_stu_info(name, age=18, *args, **kwargs):
print(name, age)
print(args)
print(kwargs)
print_stu_info("yuan", 20, "China", "Beijing", height="188cm", weight="60kg")
|
注意点:
1、参数arg、*args、**kwargs三个参数的位置必须是一定的。必须是(arg,*args,**kwargs)这个顺序,否则程序会报错。
2、不定长参数的长度可以为零。
3、args 和 kwargs其实只是编程人员约定的变量名字,args 是 arguments 的缩写,表示位置参数;kwargs 是 keyword arguments 的缩写,表示关键字参数。
7.4、函数返回值
到目前为止,我们创建的函数都只是对传入的数据进行了处理,处理完了就结束。但实际上,在更多场景中,我们还需函数将处理的结果反馈回来。通过关键字return语句可以返回任意类型的数值。
7.4.1、基本使用
1
2
3
4
5
|
def add(x,y):
return x+y # return是函数的终止语句
ret = add(2,3)
print(ret)
|
7.4.2、默认返回值
在 Python 中,有一个特殊的常量 None(N 必须大写)。和 False 不同,它不表示 0,也不表示空字符串,而表示没有值,也就是空值。None 是 NoneType数据类型的唯一值(其他编程语言可能称这个值为 null、nil 或 undefined),也就是说,我们不能再创建其它 NoneType类型的变量,但是可以将 None 赋值给任何变量。
Python一个函数中如果没有return语句或者return后没有具体值,都默认返回None,比如print()函数就没有返回。
7.4.3、返回多个值
return也可以返回多个值,python其实会将多个值放在一个元组中元组返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def login(user,pwd):
flag = False
if user == 'yuan' and pwd == 123:
flag = True
return flag,user
# ret = login("yuan",123)
flag,user = login("yuan",123)
if flag:
print("{}登陆成功!".format(user))
else:
print("用户名或者密码错误!")
|
7.5、函数嵌套
1
2
3
4
5
6
7
8
|
def foo():
def bar():
print("bar功能")
print("foo功能")
foo()
|
7.6、作用域
所谓作用域(Scope),就是变量的有效范围,就是变量可以在哪个范围以内使用。有些变量可以在整段代码的任意位置使用,有些变量只能在函数内部使用。
LEGB含义解释
| 字母 |
英语 |
释义 |
简称 |
作用空间 |
| L |
Local(function) |
当前函数内的作用域 |
局部作用域 |
局部 |
| E |
Enclosing Functions Locals |
外部嵌套函数的作用域 |
嵌套作用域 |
局部 |
| G |
Global(module) |
函数外部所在的命名空间 |
全局作用域 |
全局 |
| B |
Built In(python) |
Python内置模块的命名空间 |
内建作用域 |
内置 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# 案例1
def foo():
x = 10
foo()
print(x)
# 案例2
x = 100
def foo():
x = 10
foo()
print(x)
# 案例3
x = 100
def foo():
x = 10
print(x)
foo()
print(x)
# 案例4
x = 100
def foo():
print(x)
foo()
# 案例5
x = 100
def foo():
x = 12
def bar():
x = 1
print(x)
bar()
foo()
|
7.7、匿名函数
lambda 表达式,又称匿名函数,常用来表示内部仅包含 1 行表达式的函数。如果一个函数的函数体仅有 1 行表达式,则该函数就可以用 lambda 表达式来代替。
lambda 表达式的语法格式如下:
1
|
# name = lambda [list] : 表达式
|
其中,定义 lambda 表达式,必须使用 lambda 关键字;[list] 作为可选参数,等同于定义函数是指定的参数列表;value 为该表达式的名称。
1
2
3
4
5
|
def add(x, y):
return x+ y
print(add(2,3))
(lambda x,y:x+y)(2,3)
|
可以这样理解 lambda 表达式,其就是简单函数(函数体仅是单行的表达式)的简写版本。相比函数,lambda 表达式具有以下 2 个优势:
- 对于单行函数,使用 lambda 表达式可以省去定义函数的过程,让代码更加简洁;
- 对于不需要多次复用的函数,使用 lambda 表达式可以在用完之后立即释放,提高程序执行的性能。
7.8、高阶函数
7.8.1、高阶函数定义
一个高阶函数应该具备下面至少一个特点:
- 将一个或者多个函数作为形参
- 返回一个函数作为其结果
1
2
3
4
5
6
|
# 一切皆数据,函数亦是变量
def foo():
print("foo")
foo = 10
foo()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
import time
def foo():
print("foo功能")
time.sleep(2)
def bar():
print("bar功能")
time.sleep(3)
def timer(func):
start = time.time()
# foo()
func()
end = time.time()
print("时耗",end-start)
timer(foo)
timer(bar)
|
1
2
3
4
5
6
7
8
|
def foo():
def bar():
print("bar功能!")
return bar
func = foo()
func()
|
7.8.2、常见函数
常见内置函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
bool
bin
oct
hex
sum
max
min
abs
pow
divmod
round
chr
ord
list
dict
set
len
any
all
zip
sorted
# ----------------------------------------------- sorted函数 -----------------------------------------------
stu_dict = {1001: {"name": "yuan", "score": {"chinese": 100, "math": 90, "english": 80, "average": 90}},
1002: {"name": "alvin", "score": {"chinese": 100, "math": 100, "english": 100, "average": 100}},
1003: {"name": "rain", "score": {"chinese": 80, "math": 70, "english": 60, "average": 60}}
}
# 按着平均成绩排序
stu_list = [v for k,v in stu_dict.items()]
ret = sorted(stu_list,key=lambda stu:stu["score"]["average"],reverse=True)
print(ret)
# ----------------------------------------------- zip函数 -----------------------------------------------
# 可以将多个序列(列表、元组、字典、集合、字符串以及 range() 区间构成的列表)“压缩”成一个 zip 对象。
# 所谓“压缩”,其实就是将这些序列中对应位置的元素重新组合,生成一个个新的元组。
my_list = [1, 2, 3]
my_tuple = [4, 5, 6]
print(list(zip(my_list, my_tuple)))
|
常见高阶函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# filter函数:对sequence中的item依次执行function(item),将执行结果为True的item组成一个List/String/Tuple(取决于sequence的类型)。
def foo(x):
if x % 2 == 0:
return True
l = [1, 2, 3, 4]
print(list(filter(foo, l)))
print(list(filter(lambda x: x % 2 == 0, l)))
# map函数:对sequence中的item依次执行function(item),将function(item)执行结果(返回值)组成一个List返回
def bar(x):
return x * x
l = [1, 2, 3, 4]
print(list(map(bar, l)))
print(list(map(lambda x: x * x, l)))
# reduce函数
# 函数将一个数据集合(列表,元组等)中的所有数据进行下列操作:
# 用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,
# 得到的结果再与第三个数据用 function 函数运算,最后得到一个结果,逐步迭代。
from functools import reduce
def bar(x, y):
return x * y
l = [1, 2, 3, 4]
print(reduce(bar, l))
print(reduce(lambda x, y: x * y, l))
|
练习题:
1
2
|
# 一行代码计算1-100的和
# 如何把元组("a","b")和元组(1,2),变为字典{"a":1,"b":2}
|
7.9、闭包
首先看一下维基上对闭包的解释:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使已经离开了创造它的环境也不例外。所以,有另一种说法认为闭包是由函数和与其相关的引用环境组合而成的实体。
简单来说就是一个函数定义中引用了函数外定义的变量,并且该函数可以在其定义环境外被执行。这样的一个函数我们称之为闭包。
闭包需要满足以下三个条件:
1、必须是一个嵌套函数
2、必须返回嵌套函数
3、嵌套函数必须引用外部非全局的局部自由变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
def foo():
x = 10
def inner():
print(x)
print("bar功能!")
return inner
func = foo()
func()
def foo(x):
def inner():
print(x)
print("bar功能!")
return inner
func = foo(12)
func()
|
价值:能够动态灵活的创建以及传递函数,体现出函数式编程的特点。所以在一些场合,我们就多了一种编码方式的选择,适当的使用闭包可以使得我们的代码简洁高效。
7.10、装饰器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import time
def foo():
print("foo功能")
time.sleep(2)
def bar():
print("bar功能")
time.sleep(3)
def timer(target_func):
def wrapper():
start = time.time()
target_func()
end = time.time()
print("时耗", end - start)
return wrapper
foo = timer(foo)
foo()
bar = timer(bar)
bar()
|
练习:设计一个装饰器,能够计算某个函数被调用次数!
7.11、迭代器
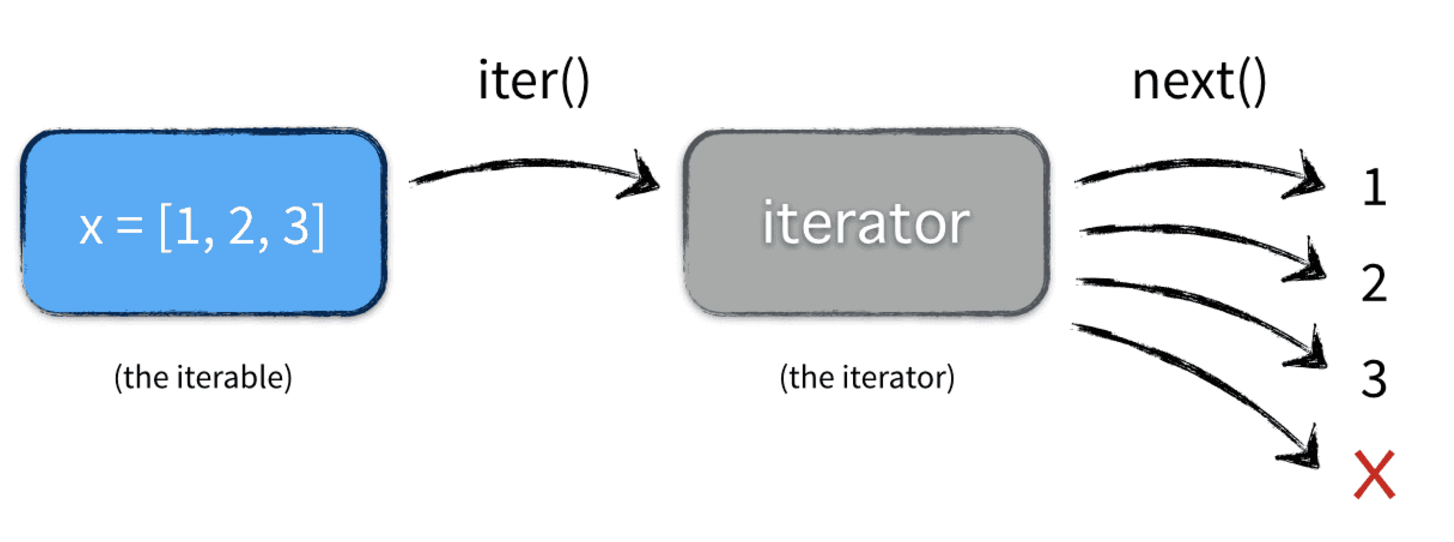
(1)可迭代对象和迭代器
在具体讲迭代器之前,先了解一个概念:可迭代对象(Iterable)。之前在数据类型中介绍的容器对象(列表,元组,字典,集合等)都是可迭代对象;从语法形式上讲,能调用__iter__方法的数据对象就是可迭代对象:
1
2
3
4
5
6
|
>>> [1,2,3].__iter__()
<listiterator object at 0x10221b150>
>>> {'name':'alvin'}.__iter__()
<dictionary-keyiterator object at 0x1022180a8>
>>> {7,8,9}.__iter__()
<setiterator object at 0x1021ff9b0>
|
obj.__iter__()方法调用后返回的就是一个迭代器对象(Iterator)。迭代器对象的特性就是能够调用__next__方法依次计算出迭代器中的下一个值。基于此就可以实现无论是否数据为序列对象,都可以通过迭代取值的方式完成查询功能。
1
2
3
4
5
6
7
8
9
10
11
12
|
>>> s={1,2,3}
>>> i=s.__iter__() # 返回可迭代对象s的迭代器对象i
>>> i.__next__() # 从第一个元素开始,i通过__next__方法就可以得到可迭代对象s的下一个值。
1
>>> i.__next__()
2
>>> i.__next__()
3
>>> i.__next__() #迭代结束,没有下一个值时调用__next__()抛出StopIteration的异常
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
|
1、针对一个没有索引的可迭代数据类型,我们执行s.__iter__()方法便得到一个迭代器,每执行一次i.__next__()就获取下一个值,待所有值全部取出后,就会抛出异常StopIteration,不过这并不代表错误发生,而是一种迭代完成的标志。需要强调的是:此处我们迭代取值的过程,不再是通过索引而是通过__next__方法。
2、可以用iter(s)取代s.__iter__(),其实iter(s)本质就是在调用s.__iter__(),这与len(s)会调用s.__len__()是一个原理,同理,可以用next(i)取代i.__next__()。obj.__iter__()方法的调用后返回的就是一个迭代器对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
class ListIterator(object):
def __init__(self, l):
self.l = l
self.index = 0
def __iter__(self):
return self
def __next__(self):
try:
ret = self.l[self.index]
self.index += 1
return ret
except IndexError:
raise StopIteration
# l1 = [1, 2, 3]
# l2 = [2, 3, 4]
# print(id(l1.__iter__()))
# print(id(l2.__iter__()))
# print(id({"name": "yuan"}.__iter__()))
iterator = ListIterator([100, 101, 102])
print(iterator.__next__())
print(iterator.__next__())
print(iterator.__next__())
for i in iterator:
print(i)
|
(2)你不了解的for循环
之前的学习只知道for循环是用来遍历某个数据对象的。但for循环内部到底是怎么工作的,关键字in后面可以放什么数据类型呢?让我们带着这些疑问一起去解析for循环的实现机制。
1
2
3
|
#for循环的形式:
for val in obj:
print(val)
|
解析:关键字in后面数据对象必须是可迭代对象。for 循环首先会调用可迭代对象内的__iter__方法返回一个迭代器,然后再调用这个迭代器的next方法将取到的值赋给val,即关键字for后的变量。循环一次,调用一次next方法,直到捕捉StopIteration异常,结束迭代。解析:关键字in后面数据对象必须是可迭代对象。for 循环首先会调用可迭代对象内的__iter__方法返回一个迭代器,然后再调用这个迭代器的next方法将取到的值赋给val,即关键字for后的变量。循环一次,调用一次next方法,直到捕捉StopIteration异常,结束迭代。
1
2
3
4
5
6
7
8
9
10
|
l = [11, 22, 33]
for i in l: # 调用iter方法返回一个关于[11,22,33]的迭代器
print(i) # 迭代器调用next方法返回的值赋值给i,即i=next(iter(l))
it = [1, 2, 3, 4, 5].__iter__()
for j in it:
print(j)
for j in it:
print(j)
|

(3)自定义迭代器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class Fib(object):
def __init__(self, max):
self.max = max
self.n, self.a, self.b = 0, 0, 1
def __iter__(self):
return self
def __next__(self):
if self.n < self.max:
r = self.b
self.a, self.b = self.b, self.a + self.b # 这次结果作为下次的初始值
self.n = self.n + 1
return r
raise StopIteration()
for i in Fib(10):
print(i)
|
迭代器协议要求迭代对象具有 __iter__()和__next__()两个方法,__next__之前讲过,是用于计算下一个值的,而__iter__则是返回迭代器本身,目的是使for循环可以遍历迭代器对象,for循环的本质是调用被迭代对象内部的__iter__方法将其变成一个迭代器然后进行迭代取值的操作,如果对象没有__iter__方法则会报错。所以可以说,迭代器对象都是可迭代对象就是因为其内部定义了__iter__方法。
7.12、生成器
生成器算得上是Python语言中最吸引人的特性之一,生成器其实是一种特殊的迭代器,不过这种迭代器更加优雅。它不需要再像上面一样在类中定义__iter__() 和__next__() 方法了,只需要在函数中声明一个 yiled 关键字。 所以生成器是一种特殊的迭代器(反之不成立),因此任何生成器也是以一种懒加载的模式生成值。用生成器来实现斐波那契数列的例子是:
1
2
3
4
5
6
7
8
9
|
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
for i in fib(10):
print(i)
|
(1)生成器对象
简单说,生成器就是使用了yield关键字的函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def countdown(n):
print('countdown start')
while n > 0:
yield n
n -= 1
print('Done!')
print(countdown) # <function countdown at 0x000001CDD6A2F040>
gen = countdown(5)
print(gen) # <generator object countdown at 0x000001CDD6B82350>
# 生成器对象也是迭代器对象,一定拥有iter和next,由yield关键字在函数调用时封装好的,不用再自己定义
# print(gen.__iter__())
# print(gen.__next__())
# print(gen.__next__())
# print(gen.__next__())
for i in gen:
print(i)
|
解析:生成器函数调用时只会返回一个生成器对象。只有当生成器对象调用__next__方法时才会触发函数体代码执行,直到遇到关键字yield停止,将yield后的值作为返回值返回,所以,yield类似于return的功能,但不同于return的是,return返回,函数结束;而yield将函数的状态挂起,等待生成器对象再次调用__next__方法时,函数从挂起的位置后的第一条语句继续运行直到再遇见yield并返回其后的值;如果不断调用__next__方法,最后一次进入函数体,待执行代码不再有yield此时报出迭代异常的错误。
另外,对比迭代器,生成器对象多几个方法:
(1)一个内置的close方法用来关闭自己
(2)一个内置的send方法,进入生成器,类似于next,但是多一个传值给yield变量的功能。
yield的功能总结:
(1)封装iter和next方法
(2)执行函数时遇到yield返回其后的值,不同于return,yiled可以返回多次值
(3)挂起函数的状态,等待下一次调用next方法时找到对应的暂停位置继续执行。
(2)生成器表达式
创建一个生成器对象有两种方式,一是通过在函数中创建yield关键字来实现。另一种就是生成器表达式,这是一种类似于数据类型中学过的列表生成式的语法格式,只是将[]换成(),即:
1
|
(expression for item in iterable if condition)
|
不同于列表生成式最后返回一个列表结果,生成器表达式顾名思义会返回一个生成器对象,比如:
1
2
3
4
5
|
>>> [x*x for x in range(4)] # 列表推导式
[0, 1, 4, 9]
>>> gen=(x*x for x in range(4))
>>> gen
<generator object <genexpr> at 0x101be0ba0>
|
当需要用到其中的值时,再通过调用next方法或者for循环将值一个个地计算出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
>>> next(gen)
0
>>> next(gen)
1
>>> next(gen)
4
>>> next(gen)
9
>>> next(gen)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
#------------for 循环------------------
>>> gen=(x*x for x in range(4))
>>> for i in gen:
... print(i)
...
0
1
4
9
|
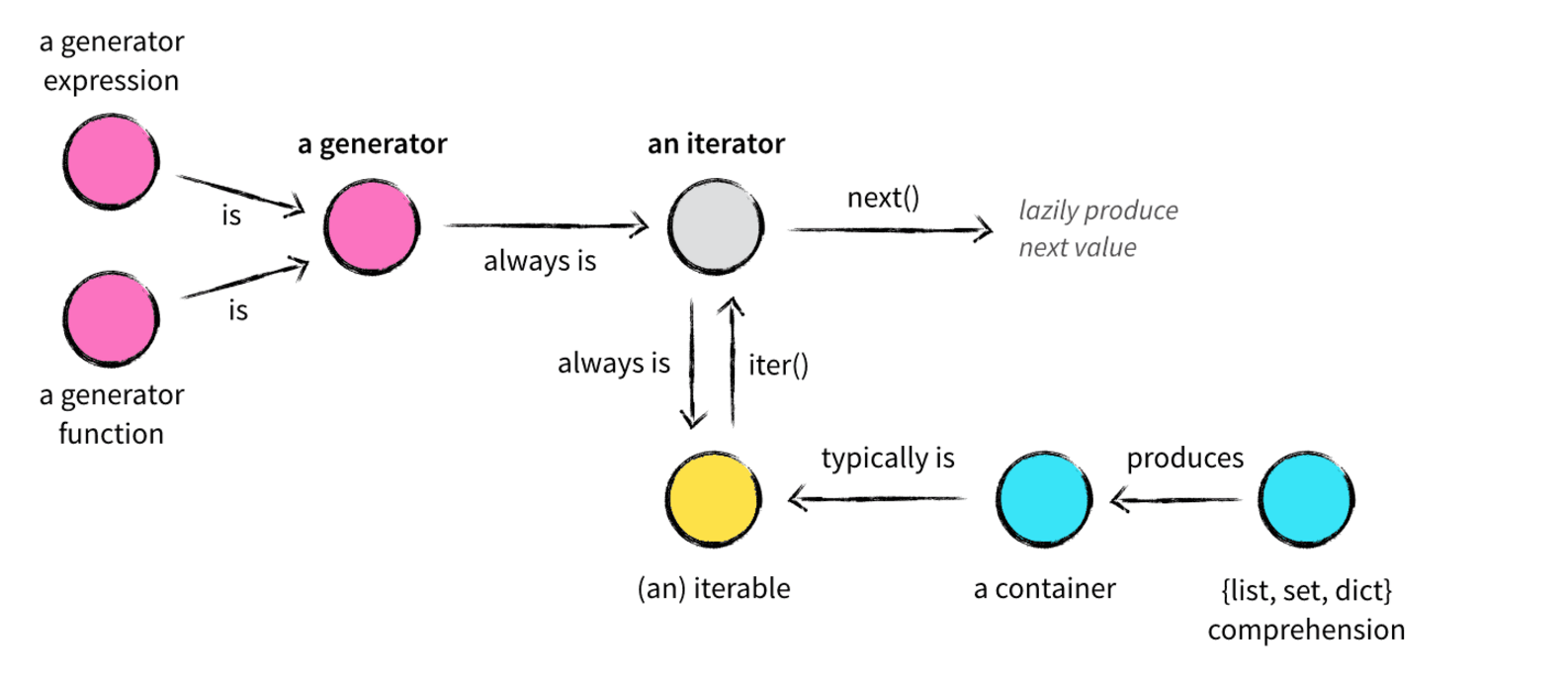
(3)可迭代对象、迭代器、生成器关系
(4)面试题
1
2
3
4
5
6
7
8
9
10
11
12
|
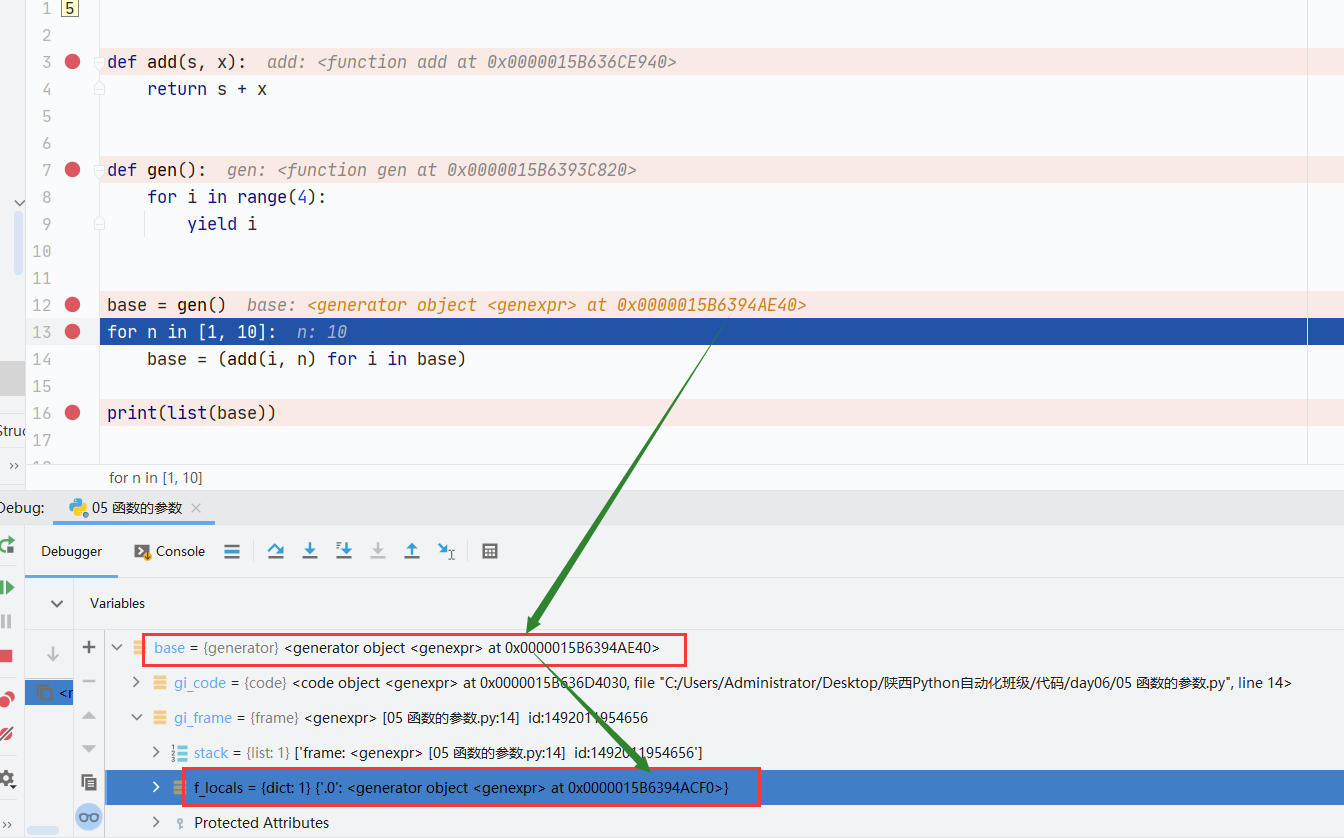
def add(s, x):
return s + x
def gen():
for i in range(4):
yield i
base = gen()
for n in [1, 10]:
base = (add(i, n) for i in base)
print(list(base))
|
配合debug模式运行,其中gi_frame, gi_code, gi_running.gi_code是生成器的代码,根据这个对象我们可以获取到生成器的函数名、文件名。gi_frame相当于栈帧,记录了生成器执行的状态,根据这个对象我们可以获取到执行到的行号信息。
八、文件操作
8.1、编码
8.1.1、编码方式

众所周知,计算机起源于美国,英文只有26个字符,算上其他所有特殊符号也不会超过128个。字节是计算机的基本储存单位,一个字节(bytes)包括八个比特位(bit),能够表示出256个二进制数字,所以美国人在这里只是用到了一个字节的前七位即127个数字来对应了127个具体字符,而这张对应表就是ASCII码字符编码表,简称ASCII表。后来为了能够让计算机识别拉丁文,就将一个字节的最高位也应用了,这样就多扩展出128个二进制数字来对应新的符号。这张对应表因为是在ASCII表的基础上扩展的最高位,因此称为扩展ASCII表。到此位置,一个字节能表示的256个二进制数字都有了特殊的符号对应。
但是,当计算机发展到东亚国家后,问题又出现了,像中文,韩文,日文等符号也需要在计算机上显示。可是一个字节已经被西方国家占满了。于是,我中华民族自己重写一张对应表,直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,即支持ASCII码表,但两个大于127的字符连在一起时,就表示一个汉字,这样就可以将几千个汉字对应一个个二进制数了。而这种编码方式就是GB2312,也称为中文扩展ASCII码表。再后来,我们为了对应更多的汉字规定只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。这样能多出几万个二进制数字,就算甲骨文也能够用了。而这次扩展的编码方式称为GBK标准。当然,GBK标准下,一个像”苑”这样的中文符号,必须占两个字节才能存储显示。
与此同时,其它国家也都开发出一套编码方式,即本国文字符号和二进制数字的对应表。而国家彼此间的编码方式是互不支持的,这会导致很多问题。于是ISO国际化标准组织为了统一编码,统计了世界上所有国家的字符,开发出了一张万国码字符表,用两个字节即六万多个二进制数字来对应。这就是Unicode编码方式。这样,每个国家都使用这套编码方式就再也不会有计算机的编码问题了。Unicode的编码特点是对于任意一个字符,都需要两个字节来存储。这对于美国人而言无异于吃上了世界的大锅饭,也就是说,如果用ASCII码表,明明一个字节就可以存储的字符现在为了兼容其他语言而需要两个字节了,比如字母I,本可以用01001001来存储,现在要用Unicode只能是00000000 01001001存储,而这将导致大量的空间被浪费掉。基于此,美国人创建了utf8编码,而utf8编码是一种针对Unicode的可变长字符编码方式,根据具体不同的字符计算出需要的字节,对于ASCII码范围的字符,就用一个字节,而且符号与数字的对应也是一致的,所以说utf8是兼容ASCII码表的。但是对于中文,一般是用三个字节存储的。
8.1.1、编码和解码
1
2
3
4
5
6
7
8
9
10
11
12
|
s = "苑昊"
b1 = s.encode()
b2 = s.encode("GBK")
print(b1) # 默认utf8 : b'\xe8\x8b\x91\xe6\x98\x8a'
print(b2) # b'\xd4\xb7\xea\xbb'
print(b1.decode()) # 这里如果用GBK解码就会出现乱码
print(b2.decode("GBK"))
print(type(b1)) # <class 'bytes'>
print(type(b2)) # <class 'bytes'>
|
![]()
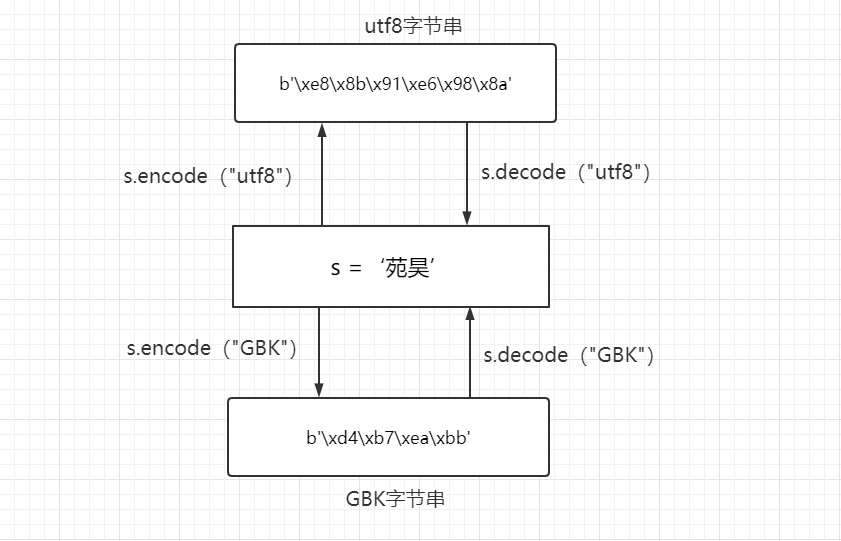
Python 3 最重要的新特性大概要算是对文本和二进制数据作了更为清晰的区分,不再会对bytes字节串进行自动解码。文本总是Unicode,由str类型表示,二进制数据则由bytes类型表示。Python 3不会以任意隐式的方式混用str和bytes,正是这使得两者的区分特别清晰。
8.1、打开文件
在 Python中,如果想要操作文件,首先需要创建或者打开指定的文件,并创建一个文件对象,而这些工作可以通过内置的 open() 函数实现。open() 函数用于创建或打开指定文件,该函数的常用语法格式如下:
1
|
file = open(file_name [, mode='r' [ , buffering=-1 [ , encoding = None ]]])
|
此格式中,用 [] 括起来的部分为可选参数,即可以使用也可以省略。其中,各个参数所代表的含义如下:
1
2
3
4
5
6
7
|
'''
- file:表示要创建的文件对象。
- file_name:要创建或打开文件的文件名称,该名称要用引号(单引号或双引号都可以)括起来。需要注意的是,如果要打开的文件和当前执行的代码文件位于同一目录,则直接写文件名即可;否则,此参数需要指定打开文件所在的完整路径。
- mode:可选参数,用于指定文件的打开模式。可选的打开模式如表 1 所示。如果不写,则默认以只读(r)模式打开文件。
- buffering:可选参数,用于指定对文件做读写操作时,是否使用缓冲区。
- encoding:手动设定打开文件时所使用的编码格式,不同平台的 ecoding 参数值也不同,以 Windows 为例,其默认为 cp936(实际上就是 GBK 编码)。
'''
|
open() 函数支持的文件打开模式如表 1 所示。
| 模式 |
意义 |
注意事项 |
| r |
只读模式打开文件,读文件内容的指针会放在文件的开头。 |
操作的文件必须存在。 |
rb |
以二进制格式、采用只读模式打开文件,读文件内容的指针位于文件的开头,一般用于非文本文件,如图片文件、音频文件等。 |
|
| r+ |
打开文件后,既可以从头读取文件内容,也可以从开头向文件中写入新的内容,写入的新内容会覆盖文件中等长度的原有内容。 |
|
rb+ |
以二进制格式、采用读写模式打开文件,读写文件的指针会放在文件的开头,通常针对非文本文件(如音频文件)。 |
|
| w |
以只写模式打开文件,若该文件存在,打开时会清空文件中原有的内容。 |
若文件存在,会清空其原有内容(覆盖文件);反之,则创建新文件。 |
wb |
以二进制格式、只写模式打开文件,一般用于非文本文件(如音频文件) |
|
| w+ |
打开文件后,会对原有内容进行清空,并对该文件有读写权限。 |
|
wb+ |
以二进制格式、读写模式打开文件,一般用于非文本文件 |
|
| a |
以追加模式打开一个文件,对文件只有写入权限,如果文件已经存在,文件指针将放在文件的末尾(即新写入内容会位于已有内容之后);反之,则会创建新文件。 |
|
| ab |
以二进制格式打开文件,并采用追加模式,对文件只有写权限。如果该文件已存在,文件指针位于文件末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
|
| a+ |
以读写模式打开文件;如果文件存在,文件指针放在文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
|
| ab+ |
以二进制模式打开文件,并采用追加模式,对文件具有读写权限,如果文件存在,则文件指针位于文件的末尾(新写入文件会位于已有内容之后);反之,则创建新文件。 |
|
将以上几个容易混淆的文件打开模式的功能做了很好的对比:
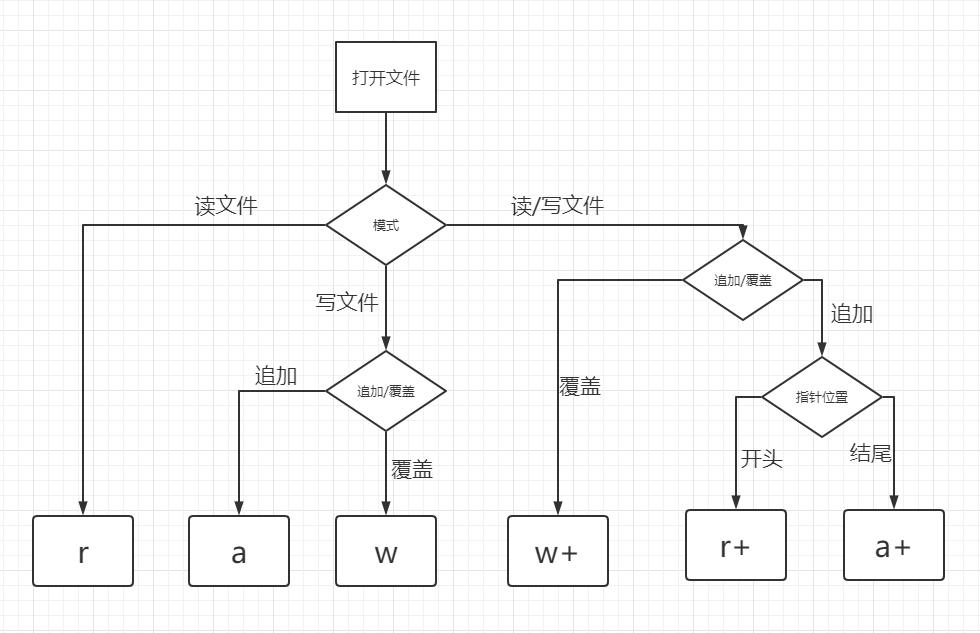
open()返回的文件对象常用的属性:
1
2
3
4
5
6
|
'''
- file.name:返回文件的名称;
- file.mode:返回打开文件时,采用的文件打开模式;
- file.encoding:返回打开文件时使用的编码格式;
- file.closed:判断文件是否己经关闭。
'''
|
注意,当操作文件结束后,必须调用 close() 函数手动将打开的文件进行关闭,这样可以避免程序发生不必要的错误。
8.2、读文件
Python提供了如下 3 种函数,它们都可以帮我们实现读取文件中数据的操作:
read() 函数:逐个字节或者字符读取文件中的内容;readline() 函数:逐行读取文件中的内容;readlines() 函数:一次性读取文件中多行内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
# (1) 读字符
f = open("满江红",encoding="utf8")
print(f.read()) # 默认读取所有字符
print(f.read(3))
print(f.readline())
print(f.readlines())
# (2) 读字节
f = open("满江红",mode="rb")
print(f.read())
print(f.read(2))
print(f.read(3))
print(f.read(2).decode())
print(f.read(12).decode())
# (3) 循环读文件
f = open("满江红",encoding="utf8")
for line in f.readlines():
print(line,end="")
for line in f:
print(line,end="")
|
8.3、写文件
1
2
3
4
5
6
7
|
f = open("满江红new",mode="w",encoding="utf8") # w:覆盖模式 a: 追加模式
f.write("怒发冲冠,凭栏处、潇潇雨歇。\n")
f.writelines(["抬望眼,","仰天长啸,壮怀激烈"]) # 将字符串列表写入文件中
f.flush()
import time
time.sleep(100)
f.close() # 没有close,只有在程序退出时才会被释放掉
|
8.4、seek与tell方法
文件指针用于标明文件读写的起始位置。使用 open() 函数打开文件并读取文件中的内容时,总是会从文件的第一个字符(字节)开始读起,而借助seek函数则可以移动文件指针的位置,在通过 read() 和 write() 函数读写指定位置的数据。而 tell() 函数则是获取光标当前位置。
当向文件中写入数据时,如果不是文件的尾部,写入位置的原有数据不会自行向后移动,新写入的数据会将文件中处于该位置的数据直接覆盖掉。
seek() 函数用于将文件指针移动至指定位置,该函数的语法格式如下:
1
|
file.seek(offset[, whence])
|
其中,各个参数的含义如下:
- whence:作为可选参数,用于指定文件指针要放置的位置,该参数的参数值有 3 个选择:0 代表文件头(默认值)、1 代表当前位置、2 代表文件尾。
- offset:表示相对于 whence 位置文件指针的偏移量,正数表示向后偏移,负数表示向前偏移。例如,当
whence == 0 &&offset == 3(即 seek(3,0) ),表示文件指针移动至距离文件开头处 3 个字符的位置;当whence == 1 &&offset == 5(即 seek(5,1) ),表示文件指针向后移动,移动至距离当前位置 5 个字符处。
1
2
3
4
5
6
7
8
|
# hi friends,welcome to oldboy!
f = open("hi",mode="rb")
print(f.tell()) # 0
print(f.read(3)) # b'hi '
print(f.tell()) # 3
f.seek(3,1)
print(f.read(1)) # b'e'
|
注意,当 offset 值非 0 时,Python 要求文件必须要以二进制格式打开,否则会抛出 io.UnsupportedOperation 错误。
8.5、章节练习
基于函数实现持久化存储的学生成绩管理系统
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
|
# 确定数据以什么数据类型和格式进行存储
import json
# 全局变量 students_dict
students_dict = {}
def init():
global students_dict
# 打开student_scores.json文件,读取json数据
try:
with open("student_scores.json", "r") as f:
student_scores_json = f.read()
# 反序列化
students_dict = json.loads(student_scores_json)
# print("初始化students_dict", students_dict)
except FileNotFoundError:
pass
def save():
# 生成一个students_scores.json
file = open("student_scores.json", "w")
students_json = json.dumps(students_dict)
file.write(students_json)
file.close()
def show_students():
'''
查看所有学生信息
'''
# print("students_dict", students_dict)
print("*" * 60)
for sid, stu_dic in students_dict.items():
# print(sid,stu_dic)
name = stu_dic.get("name")
chinese = stu_dic.get("scores").get("chinese")
math = stu_dic.get("scores").get("math")
english = stu_dic.get("scores").get("english")
print("学号:%4s 姓名:%4s 语文成绩:%4s 数学成绩%4s 英文成绩:%4s" % (sid, name, chinese, math, english))
print("*" * 60)
def add_student():
'''
添加一个学生和对应成绩
'''
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if sid in students_dict: # 该学号已经存在!
print("该学号已经存在!")
else: # # 该学号不存在!
break
name = input("请输入学生姓名>>>")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 构建学生字典
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
stu_dic = {
"name": name,
"scores": scores_dict
}
# print("stu_dic", stu_dic)
students_dict[sid] = stu_dic
# print("students_dict", students_dict)
def update_student():
'''
更新一个学生成绩
'''
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if sid in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 修改学生成绩
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
students_dict.get(sid).update({"scores": scores_dict})
print("修改成功")
print("students_dict", students_dict)
def delete_student():
'''
删除一个学生和对应成绩
'''
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if sid in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
students_dict.pop(sid)
print("删除成功")
print("students_dict", students_dict)
def main():
# 初始化读取student_scores文件获取学生成绩字典students_dict
init()
while 1:
print('''
1. 查看所有学生成绩
2. 添加一个学生成绩
3. 修改一个学生成绩
4. 删除一个学生成绩
5. 保存
6. 退出程序
''')
choice = input("请输入您的选择:")
if choice == "1":
show_students()
elif choice == "2":
add_student()
elif choice == "3":
update_student()
elif choice == "4":
delete_student()
elif choice == "5":
save()
elif choice == "6":
break
else:
print("输入有误!")
# 一般程序中的main函数是主要逻辑函数
main()
|
九、模块与包
9.1、常见模块
9.1.1、time模块
(1)三种时间形式
在Python中,通常有这三种方式来表示时间:时间戳、元组(struct_time)、格式化的时间字符串:
(1) 时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
(2) 格式化的时间字符串(Format String): ‘1988-03-16’
(3) 元组(struct_time) :struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# <1> 时间戳
>>> import time
>>> time.time()
1493136727.099066
# <2> 时间字符串
>>> time.strftime("%Y-%m-%d %X")
'2017-04-26 00:32:18'
# <3> 时间元组
>>> time.localtime()
time.struct_time(tm_year=2017, tm_mon=4, tm_mday=26,
tm_hour=0, tm_min=32, tm_sec=42, tm_wday=2,
tm_yday=116, tm_isdst=0)
|
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
(2)时间转换
1
2
3
4
5
6
7
8
9
10
11
|
# 一 时间戳 <----> 结构化时间: localtime/gmtime mktime
>>> time.localtime(3600*24)
>>> time.gmtime(3600*24)
>>> time.mktime(time.localtime())
#字符串时间 <----> 结构化时间: strftime/strptime
>>> time.strftime("%Y-%m-%d %X", time.localtime())
>>> time.strptime("2017-03-16","%Y-%m-%d")
|
(3)、其它方法
1
2
3
4
5
|
>>> time.asctime(time.localtime(312343423))
'Sun Nov 25 10:03:43 1979'
>>> time.ctime(312343423)
'Sun Nov 25 10:03:43 1979'
>>> time.sleep(seconds) # 线程推迟指定的时间运行,单位为秒。
|
9.1.2、datetime模块
datetime模块定义了以下几个类:
| 类名称 |
描述 |
| datetime.date |
表示日期,常用的属性有:year, month和day |
| datetime.time |
表示时间,常用属性有:hour, minute, second, microsecond |
| datetime.datetime |
表示日期时间 |
| datetime.timedelta |
表示两个date、time、datetime实例之间的时间间隔,分辨率(最小单位)可达到微秒 |
(1) date和time类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
import datetime
# (1) date类
date = datetime.date(2021,5,29)
print(date.year)
print(date.month)
print(date.day)
today = datetime.date.today()
print(today)
# 可以比较
print(today == date)
print(today < date)
# (2) time类: 时分秒
time = datetime.time(20,0,0)
print(time.hour)
print(time.minute)
print(time.second)
print(time.isoformat())
print(time.strftime('%H %M %S'))
|
(2) datetime类
1
|
class datetime.datetime(year, month, day, hour=0, minute=0, second=0, microsecond=0, tzinfo=None)
|
| 类方法/属性名称 |
描述 |
| datetime.today() |
返回一个表示当前本期日期时间的datetime对象 |
| datetime.now([tz]) |
返回指定时区日期时间的datetime对象,如果不指定tz参数则结果同上 |
| datetime.utcnow() |
返回当前utc日期时间的datetime对象 |
| datetime.fromtimestamp(timestamp[, tz]) |
根据指定的时间戳创建一个datetime对象 |
| datetime.utcfromtimestamp(timestamp) |
根据指定的时间戳创建一个datetime对象 |
| datetime.strptime(date_str, format) |
将时间字符串转换为datetime对象 |
对象方法和属性
| 对象方法/属性名称 |
描述 |
| dt.year, dt.month, dt.day |
年、月、日 |
| dt.hour, dt.minute, dt.second |
时、分、秒 |
| dt.date() |
获取datetime对象对应的date对象 |
| dt.time() |
获取datetime对象对应的time对象, tzinfo 为None |
| dt.isoformat([sep]) |
返回一个‘%Y-%m-%d |
| dt.strftime(format) |
返回指定格式的时间字符串 |
(3) datetime.timedelta类
datetime.timedelta类的定义:
1
|
class datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, hours=0, weeks=0)
|
timedelta对象表示连个不同时间之间的差值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# datetime类: 年月日时分秒
import datetime
dt = datetime.datetime(2012,12,12,20,5,0)
print(dt.year)
print(dt.minute)
# 获取当前时间
now = datetime.datetime.now()
today = datetime.datetime.today()
print(now)
print(today)
print(today == now)
# 计算此刻三天前的时间对象
delta = datetime.timedelta(days=3)
before_3day = now - delta
print(before_3day)
|
9.1.3、random模块
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
>>> import random
>>> random.random() # 大于0且小于1之间的小数
0.7664338663654585
>>> random.randint(1,5) # 大于等于1且小于等于5之间的整数
2
>>> random.randrange(1,3) # 大于等于1且小于3之间的整数
1
>>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5]
1
>>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合
[[4, 5], '23']
>>> random.uniform(1,3) #大于1小于3的小数
1.6270147180533838
>>> item=[1,3,5,7,9]
>>> random.shuffle(item) # 打乱次序
>>> item
[5, 1, 3, 7, 9]
>>> random.shuffle(item)
>>> item
[5, 9, 7, 1, 3]
|
随机验证码案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import random
def v_code():
code = ''
for i in range(5):
num=random.randint(0,9)
alf=chr(random.randint(65,90))
add=random.choice([num,alf])
code="".join([code,str(add)])
return code
print(v_code())
|
9.1.4、hash模块
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
(1)摘要算法介绍
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
1
2
3
4
5
6
7
8
|
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?')
print md5.hexdigest()
# 计算结果如下:
d26a53750bc40b38b65a520292f69306
|
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
1
2
3
4
|
md5 = hashlib.md5()
md5.update('how to use md5 in ')
md5.update('python hashlib?')
print md5.hexdigest()
|
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
1
2
3
4
5
6
|
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in ')
sha1.update('python hashlib?')
print sha1.hexdigest()
|
SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
(2)摘要算法应用
任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中:
1
2
3
4
5
|
name | password
--------+----------
michael | 123456
bob | abc999
alice | alice2008
|
如果以明文保存用户口令,如果数据库泄露,所有用户的口令就落入黑客的手里。此外,网站运维人员是可以访问数据库的,也就是能获取到所有用户的口令。正确的保存口令的方式是不存储用户的明文口令,而是存储用户口令的摘要,比如MD5:
1
2
3
4
5
|
username | password
---------+---------------------------------
michael | e10adc3949ba59abbe56e057f20f883e
bob | 878ef96e86145580c38c87f0410ad153
alice | 99b1c2188db85afee403b1536010c2c9
|
考虑这么个情况,很多用户喜欢用123456,888888,password这些简单的口令,于是,黑客可以事先计算出这些常用口令的MD5值,得到一个反推表:
1
2
3
|
'e10adc3949ba59abbe56e057f20f883e': '123456'
'21218cca77804d2ba1922c33e0151105': '888888'
'5f4dcc3b5aa765d61d8327deb882cf99': 'password'
|
这样,无需破解,只需要对比数据库的MD5,黑客就获得了使用常用口令的用户账号。
对于用户来讲,当然不要使用过于简单的口令。但是,我们能否在程序设计上对简单口令加强保护呢?
由于常用口令的MD5值很容易被计算出来,所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”:
1
|
hashlib.md5("salt".encode("utf8"))
|
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。有没有办法让使用相同口令的用户存储不同的MD5呢?
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
摘要算法在很多地方都有广泛的应用。要注意摘要算法不是加密算法,不能用于加密(因为无法通过摘要反推明文),只能用于防篡改,但是它的单向计算特性决定了可以在不存储明文口令的情况下验证用户口令。
9.1.5、logging模块
(1)日志介绍
日志是一种可以追踪某些软件运行时所发生事件的方法。软件开发人员可以向他们的代码中调用日志记录相关的方法来表明发生了某些事情。一个事件可以用一个可包含可选变量数据的消息来描述。此外,事件也有重要性的概念,这个重要性也可以被称为严重性级别(level)。
在软件开发阶段或部署开发环境时,为了尽可能详细的查看应用程序的运行状态来保证上线后的稳定性,我们可能需要把该应用程序所有的运行日志全部记录下来进行分析,这是非常耗费机器性能的。当应用程序正式发布或在生产环境部署应用程序时,我们通常只需要记录应用程序的异常信息、错误信息等,这样既可以减小服务器的I/O压力,也可以避免我们在排查故障时被淹没在日志的海洋里。那么,怎样才能在不改动应用程序代码的情况下实现在不同的环境记录不同详细程度的日志呢?这就是日志等级的作用了,我们通过配置文件指定我们需要的日志等级就可以了。
不同的应用程序所定义的日志等级可能会有所差别,分的详细点的会包含以下几个等级:
| 级别 |
何时使用 |
| DEBUG |
详细信息,典型地调试问题时会感兴趣。 详细的debug信息。 |
| INFO |
证明事情按预期工作。 关键事件。 |
| WARNING |
表明发生了一些意外,或者不久的将来会发生问题(如‘磁盘满了’)。软件还是在正常工作。 |
| ERROR |
由于更严重的问题,软件已不能执行一些功能了。 一般错误消息。 |
| CRITICAL |
严重错误,表明软件已不能继续运行了。 |
| NOTICE |
不是错误,但是可能需要处理。普通但是重要的事件。 |
| ALERT |
需要立即修复,例如系统数据库损坏。 |
| EMERGENCY |
紧急情况,系统不可用(例如系统崩溃),一般会通知所有用户。 |
一条日志信息对应的是一个事件的发生,而一个事件通常需要包括以下几个内容:
-
事件发生时间
-
事件发生位置
-
事件的严重程度–日志级别
-
事件内容
上面这些都是一条日志记录中可能包含的字段信息,当然还可以包括一些其他信息,如进程ID、进程名称、线程ID、线程名称等。日志格式就是用来定义一条日志记录中包含那些字段的,且日志格式通常都是可以自定义的。
logging模块默认定义了以下几个日志等级,它允许开发人员自定义其他日志级别,但是这是不被推荐的,尤其是在开发供别人使用的库时,因为这会导致日志级别的混乱。
| 日志等级(level) |
描述 |
| DEBUG |
最详细的日志信息,典型应用场景是 问题诊断 |
| INFO |
信息详细程度仅次于DEBUG,通常只记录关键节点信息,用于确认一切都是按照我们预期的那样进行工作 |
| WARNING |
当某些不期望的事情发生时记录的信息(如,磁盘可用空间较低),但是此时应用程序还是正常运行的 |
| ERROR |
由于一个更严重的问题导致某些功能不能正常运行时记录的信息 |
| CRITICAL |
当发生严重错误,导致应用程序不能继续运行时记录的信息 |
开发应用程序或部署开发环境时,可以使用DEBUG或INFO级别的日志获取尽可能详细的日志信息来进行开发或部署调试;
应用上线或部署生产环境时,应该使用WARNING或ERROR或CRITICAL级别的日志来降低机器的I/O压力和提高获取错误日志信息的效率。日志级别的指定通常都是在应用程序的配置文件中进行指定的。
说明:
- 上面列表中的日志等级是从上到下依次升高的,即:DEBUG < INFO < WARNING < ERROR < CRITICAL,而日志的信息量是依次减少的;
- 当为某个应用程序指定一个日志级别后,应用程序会记录所有日志级别大于或等于指定日志级别的日志信息,而不是仅仅记录指定级别的日志信息,nginx、php等应用程序以及这里的python的logging模块都是这样的。同样,logging模块也可以指定日志记录器的日志级别,只有级别大于或等于该指定日志级别的日志记录才会被输出,小于该等级的日志记录将会被丢弃。
(2)basicConfig日志
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import logging
LOG_FORMAT = "%(asctime)s %(name)s %(levelname)s %(pathname)s %(message)s "#配置输出日志格式
DATE_FORMAT = '%Y-%m-%d %H:%M:%S %a ' #配置输出时间的格式,注意月份和天数不要搞乱了
logging.basicConfig(level=logging.DEBUG,
format=LOG_FORMAT,
datefmt = DATE_FORMAT ,
# filename=r"test.log", #有了filename参数就不会直接输出显示到控制台,而是直接写入文件
)
logging.debug("debug")
logging.info("info")
logging.warning("warning")
logging.error("error")
logging.critical("critical")
|
| 参数名称 |
描述 |
| filename |
指定日志输出目标文件的文件名(可以写文件名也可以写文件的完整的绝对路径,写文件名日志放执行文件目录下,写完整路径按照完整路径生成日志文件),指定该设置项后日志信心就不会被输出到控制台了 |
| filemode |
指定日志文件的打开模式,默认为’a’。需要注意的是,该选项要在filename指定时才有效 |
| format |
指定日志格式字符串,即指定日志输出时所包含的字段信息以及它们的顺序。logging模块定义的格式字段下面会列出。 |
| datefmt |
指定日期/时间格式。需要注意的是,该选项要在format中包含时间字段%(asctime)s时才有效 |
| level |
指定日志器的日志级别 |
| stream |
指定日志输出目标stream,如sys.stdout、sys.stderr以及网络stream。需要说明的是,stream和filename不能同时提供,否则会引发 ValueError异常 |
| style |
Python 3.2中新添加的配置项。指定format格式字符串的风格,可取值为’%’、’{‘和’$’,默认为’%’ |
| handlers |
Python 3.3中新添加的配置项。该选项如果被指定,它应该是一个创建了多个Handler的可迭代对象,这些handler将会被添加到root logger。需要说明的是:filename、stream和handlers这三个配置项只能有一个存在,不能同时出现2个或3个,否则会引发ValueError异常。 |
format格式字符串参数
| 字段/属性名称 |
使用格式 |
描述 |
| asctime |
%(asctime)s |
将日志的时间构造成可读的形式,默认情况下是‘2016-02-08 12:00:00,123’精确到毫秒 |
| name |
%(name)s |
所使用的日志器名称,默认是’root’,因为默认使用的是 rootLogger |
| filename |
%(filename)s |
调用日志输出函数的模块的文件名; pathname的文件名部分,包含文件后缀 |
| funcName |
%(funcName)s |
由哪个function发出的log, 调用日志输出函数的函数名 |
| levelname |
%(levelname)s |
日志的最终等级(被filter修改后的) |
| message |
%(message)s |
日志信息, 日志记录的文本内容 |
| lineno |
%(lineno)d |
当前日志的行号, 调用日志输出函数的语句所在的代码行 |
| levelno |
%(levelno)s |
该日志记录的数字形式的日志级别(10, 20, 30, 40, 50) |
| pathname |
%(pathname)s |
完整路径 ,调用日志输出函数的模块的完整路径名,可能没有 |
| process |
%(process)s |
当前进程, 进程ID。可能没有 |
| processName |
%(processName)s |
进程名称,Python 3.1新增 |
| thread |
%(thread)s |
当前线程, 线程ID。可能没有 |
| threadName |
%(thread)s |
线程名称 |
| module |
%(module)s |
调用日志输出函数的模块名, filename的名称部分,不包含后缀即不包含文件后缀的文件名 |
| created |
%(created)f |
当前时间,用UNIX标准的表示时间的浮点数表示; 日志事件发生的时间–时间戳,就是当时调用time.time()函数返回的值 |
| relativeCreated |
%(relativeCreated)d |
输出日志信息时的,自Logger创建以 来的毫秒数; 日志事件发生的时间相对于logging模块加载时间的相对毫秒数 |
| msecs |
%(msecs)d |
日志事件发生事件的毫秒部分。logging.basicConfig()中用了参数datefmt,将会去掉asctime中产生的毫秒部分,可以用这个加上 |
说明
-
logging.basicConfig()函数是一个一次性的简单配置工具使,也就是说只有在第一次调用该函数时会起作用,后续再次调用该函数时完全不会产生任何操作的,多次调用的设置并不是累加操作。
-
如果要记录的日志中包含变量数据,可使用一个格式字符串作为这个事件的描述消息(logging.debug、logging.info等函数的第一个参数),然后将变量数据作为第二个参数*args的值进行传递,如:
1
|
logging.warning('%s is %d years old.', 'Tom', 10),
|
输出内容为
1
|
WARNING:root:Tom is 10 years old.
|
(3)logger日志
日志流处理流程是一个模块级别的函数是logging.getLogger([name])(返回一个logger对象,如果没有指定名字将返回root logger)。
(1) logging日志模块四大组件
在介绍logging模块的日志流处理流程之前,我们先来介绍下logging模块的四大组件:
| 组件名称 |
对应类名 |
功能描述 |
| 日志器 |
Logger |
提供了应用程序可一直使用的接口 |
| 处理器 |
Handler |
将logger创建的日志记录发送到合适的目的输出 |
| 过滤器 |
Filter |
提供了更细粒度的控制工具来决定输出哪条日志记录,丢弃哪条日志记录 |
| 格式器 |
Formatter |
决定日志记录的最终输出格式 |
logging模块就是通过这些组件来完成日志处理的,上面所使用的logging模块级别的函数也是通过这些组件对应的类来实现的。
这些组件之间的关系描述:
- 日志器(logger)需要通过处理器(handler)将日志信息输出到目标位置,如:文件、sys.stdout、网络等;
- 不同的处理器(handler)可以将日志输出到不同的位置;
- 日志器(logger)可以设置多个处理器(handler)将同一条日志记录输出到不同的位置;
- 每个处理器(handler)都可以设置自己的过滤器(filter)实现日志过滤,从而只保留感兴趣的日志;
- 每个处理器(handler)都可以设置自己的格式器(formatter)实现同一条日志以不同的格式输出到不同的地方。
简单点说就是:日志器(logger)是入口,真正干活儿的是处理器(handler),处理器(handler)还可以通过过滤器(filter)和格式器(formatter)对要输出的日志内容做过滤和格式化等处理操作。
(2) Handler类
Handler对象的作用是(基于日志消息的level)将消息分发到handler指定的位置(文件、网络、邮件等)。Logger对象可以通过addHandler()方法为自己添加0个或者更多个handler对象。比如,一个应用程序可能想要实现以下几个日志需求:
- 把所有日志都发送到一个日志文件中;
- 把所有严重级别大于等于error的日志发送到stdout(标准输出);
- 把所有严重级别为critical的日志发送到一个email邮件地址。这种场景就需要3个不同的handlers,每个handler复杂发送一个特定严重级别的日志到一个特定的位置。
1
2
3
|
Handler.setLevel(lel): # 指定被处理的信息级别,低于lel级别的信息将被忽略
Handler.setFormatter():# 给这个handler选择一个格式
Handler.addFilter(filt):# Handler.removeFilter(filt):新增或删除一个filter对象
|
需要说明的是,应用程序代码不应该直接实例化和使用Handler实例。因为Handler是一个基类,它只定义了素有handlers都应该有的接口,同时提供了一些子类可以直接使用或覆盖的默认行为。下面是一些常用的Handler:
| Handler |
描述 |
| logging.StreamHandler |
将日志消息发送到输出到Stream,如std.out, std.err或任何file-like对象。 |
| logging.FileHandler |
将日志消息发送到磁盘文件,默认情况下文件大小会无限增长 |
| logging.handlers.RotatingFileHandler |
将日志消息发送到磁盘文件,并支持日志文件按大小切割 |
| logging.hanlders.TimedRotatingFileHandler |
将日志消息发送到磁盘文件,并支持日志文件按时间切割 |
| logging.handlers.HTTPHandler |
将日志消息以GET或POST的方式发送给一个HTTP服务器 |
| logging.handlers.SMTPHandler |
将日志消息发送给一个指定的email地址 |
| logging.NullHandler |
该Handler实例会忽略error messages,通常被想使用logging的library开发者使用来避免’No handlers could be found for logger XXX’信息的出现。 |
Formater对象用于配置日志信息的最终顺序、结构和内容。与logging.Handler基类不同的是,应用代码可以直接实例化Formatter类。另外,如果你的应用程序需要一些特殊的处理行为,也可以实现一个Formatter的子类来完成。
Formatter类的构造方法定义如下:
1
|
logging.Formatter.__init__(fmt=None, datefmt=None, style='%')
|
可见,该构造方法接收3个可选参数:
- fmt:指定消息格式化字符串,如果不指定该参数则默认使用message的原始值
- datefmt:指定日期格式字符串,如果不指定该参数则默认使用”%Y-%m-%d %H:%M:%S"
- style:Python 3.2新增的参数,可取值为 ‘%’, ‘{‘和 ‘$’,如果不指定该参数则默认使用’%’
一般直接用logging.Formatter(fmt, datefmt)
(4) Filter类
Filter可以被Handler和Logger用来做比level更细粒度的、更复杂的过滤功能。Filter是一个过滤器基类,它只允许某个logger层级下的日志事件通过过滤。该类定义如下:
1
2
|
class logging.Filter(name='')
filter(record)
|
比如,一个filter实例化时传递的name参数值为’A.B’,那么该filter实例将只允许名称为类似如下规则的loggers产生的日志记录通过过滤:‘A.B’,‘A.B,C’,‘A.B.C.D’,‘A.B.D’,而名称为’A.BB’, ‘B.A.B’的loggers产生的日志则会被过滤掉。如果name的值为空字符串,则允许所有的日志事件通过过滤。
filter方法用于具体控制传递的record记录是否能通过过滤,如果该方法返回值为0表示不能通过过滤,返回值为非0表示可以通过过滤。
说明:
- 如果有需要,也可以在filter(record)方法内部改变该record,比如添加、删除或修改一些属性
- 我们还可以通过filter做一些统计工作,比如可以计算下被一个特殊的logger或handler所处理的record数量等。
(5) 日志流处理简要流程
1
2
3
4
5
6
7
8
9
10
|
/*
1、创建一个logger
2、设置下logger的日志的等级
3、创建合适的Handler(FileHandler要有路径)
4、设置下每个Handler的日志等级
5、创建下日志的格式
6、向Handler中添加上面创建的格式
7、将上面创建的Handler添加到logger中
8、打印输出logger.debug\logger.info\logger.warning\logger.error\logger.critical
*/
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import logging
def log():
#创建logger,如果参数为空则返回root logger
logger = logging.getLogger("nick")
logger.setLevel(logging.DEBUG) #设置logger日志等级
#这里进行判断,如果logger.handlers列表为空,则添加,否则,多次调用函数会重复添加
if not logger.handlers:
#创建handler
fh = logging.FileHandler("test.log",encoding="utf-8")
ch = logging.StreamHandler()
#设置输出日志格式
formatter = logging.Formatter(
fmt="%(asctime)s %(name)s %(filename)s %(message)s",
datefmt="%Y/%m/%d %X"
)
#为handler指定输出格式
fh.setFormatter(formatter)
ch.setFormatter(formatter)
#为logger添加的日志处理器
logger.addHandler(fh)
logger.addHandler(ch)
return logger #直接返回logger
logger = log()
logger.warning("泰拳警告")
logger.info("提示")
logger.error("错误")
logger.debug("查错")
|
注意:因为logging模块是基于单例模式线程安全的,所以get_logger()如果名字参数相同则返回的是同一个对象,所以
添加handler的时候一定要判断,不要重复添加造成重复打印日志的bug!
9.1.6、os模块
os模块是与操作系统交互的一个接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import os
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd
os.curdir # 返回当前目录: ('.')
os.pardir # 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') # 可生成多层递归目录
os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') # # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() # 删除一个文件
os.rename("oldname","newname") # 重命名文件/目录
os.stat('path/filename') # 获取文件/目录信息
os.sep # 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep # 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep # 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name # 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") # 运行shell命令,直接显示
os.environ # 获取系统环境变量
os.path.abspath(path) # 返回path规范化的绝对路径
os.path.split(path) # 将path分割成目录和文件名二元组返回
os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) # 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) # 如果path是绝对路径,返回True
os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) # 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) # 返回path的大小
|
9.1.7、sys模块
sys是与解释器相关信息的模块
1
2
3
4
5
6
|
sys.argv # 命令行参数List,第一个元素是程序本身路径
sys.exit(n) # 退出程序,正常退出时exit(0)
sys.version # 获取Python解释程序的版本信息
sys.maxint # 最大的Int值
sys.path # 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform # 返回操作系统平台名称
|
9.1.8、序列化模块
序列化: 通过某种方式把数据结构或对象写入到磁盘文件中或通过网络传到其他节点的过程。
反序列化:把磁盘中对象或者把网络节点中传输的数据恢复为python的数据对象的过程。
序列化最重要的就是json序列化。
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
|

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import json
i=10
s='hello'
t=(1,4,6)
l=[3,5,7]
d={'name':"yuan"}
json_str1=json.dumps(i)
json_str2=json.dumps(s)
json_str3=json.dumps(t)
json_str4=json.dumps(l)
json_str5=json.dumps(d)
print(repr(json_str1))
print(repr(json_str2))
print(repr(json_str3))
print(repr(json_str4))
print(repr(json_str5))
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import json
dic={'name':'yuan','age':23,'is_married':0}
data=json.dumps(dic) # 序列化,将python的字典转换为json格式的字符串
print("type",type(data)) # <class 'str'>
with open('json.txt','w') as f:
f.write(data) # 等价于json.dump(dic,f)
with open('json.txt') as f:
data = f.read()
dic = json.loads(data) # 反序列化成为python的字典,等价于data=json.load(f)
print(type(dic))
# 思考: json.loads('{"name": "yuan", "age": 23, "is_married": 0}') 可以吗?
|
1
2
3
4
5
6
7
8
9
10
|
<script>
// 序列化
data = {user:"yuan",pwd:123}
console.log(JSON.stringify(data)) // '{"user":"yuan","pwd":123}'
// 反序列化
res_json = '{"name": "yuan", "age": 23, "is_married": 0}'
let res = JSON.parse(res_json)
console.log(res)
</script>
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import json
# 反序列化
data = '{"user":"yuan","pwd":123}'
data_dict = json.loads(data)
print(type(data_dict))
# 序列化
res = {'name':'yuan','age':23,'is_married':0}
res_json = json.dumps(res) # 序列化,将python的字典转换为json格式的字符串
print(repr(res_json)) # '{"name": "yuan", "age": 23, "is_married": 0}'
|
9.1.9、正则模块
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
(1)元字符
. :除换行符以外的任意符号,re.S模式也可以使 . 匹配包括换行在内的所有字符
^:匹配字符串的开头
$:匹配字符串的末尾。
*:匹配0个或多个的表达式。默认贪婪模式
+:匹配1个或多个的表达式。默认贪婪模式
?:匹配0个或1个由前面的正则表达式,默认非贪婪模式
{ n,m}:匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
[ ]:字符集,多个字符选其一,[^...]取反
|:匹配做正则表达式或右边正则表达式
( ):G匹配括号内的表达式,也表示一个组
\:转移符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
import re
# (1) . ^ $
ret = re.findall("hello world","hello world")
print(ret)
ret = re.findall("^hello world$","hello python,hello world,hello re")
print(ret)
ret = re.findall("^hello .....$","hello world")
print(ret)
# (2) * + ?
ret = re.findall("^hello .*","hello ")
ret = re.findall("^hello .+","hello ")
ret = re.findall("^hello .?","hello abc")
# (3) {} ()
ret = re.findall("hello .{5}","hello python,hello world,hello re,hello yuan")
print(ret)
ret = re.findall("hello .{2,5}","hello python,hello world,hello re")
print(ret)
ret = re.findall("hello .{5},","hello python,hello world,hello re")
print(ret)
ret = re.findall("hello (.*?),","hello python,hello world,hello re,hello yuan,")
print(ret)
# ret = re.findall("hello (.*?)(?:,|$)","hello python,hello world,hello re,hello yuan")
# print(ret)
# (4) [] |
ret = re.findall("a[bcd]e","abeabaeacdeace")
print(ret)
ret = re.findall("[a-z]","123a45bcd678")
print(ret)
ret = re.findall("[^a-z]","123a45bcd678")
print(ret)
ret = re.findall("www\.([a-z]+)\.(?:com|cn)","www.baidu.com,www.jd.com")
print(ret)
# (5) \
'''
1、反斜杠后边跟元字符去除特殊功能,比如\.
2、反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数; 它相当于类 [0-9]。
\D 匹配任何非数字字符; 它相当于类 [^0-9]。
\s 匹配任何空白字符; 它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符; 它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符; 它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符; 它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
'''
ret = re.findall("\d+","123a45bcd678")
print(ret)
ret = re.findall("(?:\d+)|(?:[a-z]+)","123a45bcd678")
print(ret)
|
(2)正则方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
import re
# 查找所有符合条件的对象
# re.findall() # 返回列表
# 查找第一个符合条件的匹配对象
s = re.search("\d+","a45bcd678")
print(s)
print(s.group())
# match同search,不过只在字符串开始处进行匹配
s = re.match("\d+","a45bcd678")
# print(s)
# print(s.group())
# 正则分割split
ret = re.split('[ab]', 'abcd')
print(ret)
# 正则替换
def func(match):
name = match.group()
print("name",name)
return "xxx"
# \1代指第一个组匹配的内容 \2第二个组匹配的内容,思考如何能将所有的名字转大写替换
ret = re.sub("(hello )(.*?)(,)","\\1yuan\\3","hello python,hello world,hello re,")
print("ccc",ret)
# 编译再执行
obj=re.compile('\d{3}')
ret=obj.search('abc123ee45ff')
print(ret.group()) # 123
|
练习:爬虫豆瓣网
1
2
3
4
5
6
|
com=re.compile(
'<div class="item">.*?<div class="pic">.*?<em .*?>(?P<id>\d+).*?<span class="title">(?P<title>.*?)</span>'
'.*?<span class="rating_num" .*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)评价</span>',
re.S)
com.findall(s)
|
9.2、模块
9.2.1、模块介绍
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。而这样的一个py文件在Python中称为模块(Module)。
模块是组织代码的更高级形式,大大提高了代码的阅读性和可维护性。
模块一共四种:
- 解释器内建模块
- python标准库
- 第三方模块
- 应用程序自定义模块
另外,使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。
9.2.2、模块导入
1
2
3
4
5
6
7
8
9
10
11
12
|
'''
# 方式1:导入一个模块
import 模块名
import 模块名 as 别名
# 方式2:导入多个模块
import 模块1,模块2
# 方式3:导入成员变量
from 模块名 import 成员变量
from 模块名 import *
'''
|
- 导入模块时会执行模块,多次导入只执行一次。
- 导入模块本质是:解释器依赖
sys.path的路径进行查找,而需要格外注意的是python解释器运行某个程序时会将该程序的启动文件的目录加入到sysy.path中。
案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
# 模块本质上就是一个具有某类功能函数的.py文件
# 查找模块的顺序: 1. 解释器自带 2. sys.path # [执行程序所在目录路径,python标准库路径]
# 注意:自定义模块不要和标准库中的模块重名
import random # python标准库的模块
import time # 解释器自带的模块
import requests
# import cal # 自定义模块
from cal import add as cal_add, mul # 从cal模块中导入add,mul函数
# from cal import * # # 从cal模块中导入所有变量
# 变量冲突问题
def add(x, y):
print(":::add", x, y)
def main():
num1 = random.randint(1, 100)
num2 = random.randint(1, 100)
print("num1和num2分别是:", num1, num2)
ret1 = cal_add(num1, num2)
# ret1 = cal.add(num1, num2)
print(ret1)
print(time.time())
main()
|
9.2.3、__name__
__name__是python内置变量,存储的是当前模块名称。
对于很多编程语言来说,程序都必须要有一个入口。像C,C++都有一个main函数作为程序的入口,而Python作为解释性脚本语言,没有一个统一的入口,因为Python程序运行时是从模块顶行开始,逐行进行翻译执行,所以,最顶层(没有被缩进)的代码都会被执行,所以Python中并不需要一个统一的main()作为程序的入口。
在刚才的案例中2个模块都打印一次__name__
1
2
|
print("cal.py",__name__)
print("main.py",__name__)
|
结果为:
1
2
|
cal.py cal
main.py __main__
|
通过结果发现__name__只有在执行模块中打印__main__,在其他导入模块中打印各自模块的名称。
所以,__name__可以有以下作用:
- 利用
__name__=="__main__"声明程序入口。
- 可以对导入的模块进行功能测试
9.3、包
9.3.1、什么是包
当一个项目中模块越来越多,维护和开发不是那么高效的时候,我们可以引入一种比模块更高级语法:包。
包是对相关功能的模块py文件的组织方式。
包可以理解为文件夹,更确切的说,是一个包含__init__文件的文件夹。
9.3.2、导入包语法
1
2
3
|
1. import 包名[.模块名 [as 别名]]
2. from 包名 import 模块名 [as 别名]
3. from 包名.模块名 import 成员名 [as 别名]
|
案例:将上面案例中的cal .py文件放到utils包中管理,logger.py放到logger包中管理。
1
2
3
4
5
6
|
-- demo
main.py
-- utils
cal.py
-- logger
logger.py
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# 方式1
from utils import cal
ret = cal.add(2,5)
print(ret)
# 方式2
import utils.cal
ret = utils.cal.add(4,6)
print(ret)
# 方式3
from utils.cal import add
ret = add(3,5)
print(ret)
|
如果将main.py放在一个main包下,运行会报错。根本原因是无论导包还是调用模块都是解释器依赖sys.path的路径进行查找,而python解释器运行某个程序时会将该程序的启动文件的目录加入到sysy.path中.所以启动文件的同级目录或者文件才可以调用。
所以这种目录结构下需要构建模块路径:
1
2
3
|
import sys,os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
|
思考:
1、如何在cal.py中导入同级目录模块?
2、导入模块的执行顺序?
9.3.3、__init__文件
__init__.py该文件的作用就是相当于把自身整个文件夹当作一个包来管理,每当有外部导入的时候会自动执行里面的代码。
主要功能:
- 标识该目录是一个python的模块包(module package)
- 简化模块导入操作
- 控制模块导入
- 偷懒的导入方法
__all__ 关联了一个模块列表,当执行 from xx import * 时,就会导入列表中的模块。
- 配置模块的初始化操作
在了解了__init__.py的工作原理后,应该能理解该文件就是一个正常的python代码文件,因此可以将初始化代码放入该文件中。
9.4、章节作业
将学生成绩管理系统改版为多目录结构
预备知识点
1
2
3
4
5
6
7
8
9
10
11
12
13
|
x = {}
print("全局:", id(x))
def foo():
# global x
data = {"name": "yuan"}
x = data
# x.update(data)
print("局部:", id(x))
foo()
print(x)
|
参考代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
│ bin.py
│ student_scores.json
│
├─conf
│ │ settings.py
│ │ __init__.py
│ │
│
├─core
│ │ main.py
│ │ scores_handler.py
│ │ __init__.py
│ │
│
└─db_handler
│ serializer.py
│ __init__.py
│
|
1
2
3
4
5
6
|
# bin.py
from core import main
if __name__ == '__main__':
main.main()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
# core.main.py
import sys
from core.scores_handler import show_students, add_student, update_student, delete_student
from db_handler.serializer import save, init
def exit():
sys.exit()
def main():
# 初始化读取student_scores文件获取学生成绩字典students_dict
init()
while 1:
print('''
1. 查看所有学生成绩
2. 添加一个学生成绩
3. 修改一个学生成绩
4. 删除一个学生成绩
5. 保存
6. 退出程序
''')
choice = input("请输入您的选择:")
# if-elif 版本
# if choice == "1":
# show_students()
#
# elif choice == "2":
# add_student()
#
# elif choice == "3":
# update_student()
#
# elif choice == "4":
# delete_student()
#
# elif choice == "5":
# save()
#
# elif choice == "6":
# break
# else:
# print("输入有误!")
# 基于字典的switch版本
choice_func = {"1": show_students, "2": add_student, "3": update_student, "4": delete_student, "5": save,
"6": exit}
func = choice_func.get(choice)
if func:
func()
else:
print("输入有误!")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
# core.scores_handler
students_dict = {}
print("在stu_scores_handler的students_dict", id(students_dict))
def show_students():
'''
查看所有学生信息
'''
print("students_dict", students_dict)
print("*"*60)
for sid, stu_dic in students_dict.items():
# print(sid,stu_dic)
name = stu_dic.get("name")
chinese = stu_dic.get("scores").get("chinese")
math = stu_dic.get("scores").get("math")
english = stu_dic.get("scores").get("english")
print("学号:%4s 姓名:%4s 语文成绩:%4s 数学成绩%4s 英文成绩:%4s" % (sid, name, chinese, math, english))
print("*"*60)
def add_student():
'''
添加一个学生和对应成绩
'''
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if sid in students_dict: # 该学号已经存在!
print("该学号已经存在!")
else: # # 该学号不存在!
break
name = input("请输入学生姓名>>>")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 构建学生字典
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
stu_dic = {
"name": name,
"scores": scores_dict
}
print("stu_dic", stu_dic)
students_dict[sid] = stu_dic
print("students_dict", students_dict)
def update_student():
'''
更新一个学生成绩
'''
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if sid in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
chinese_score = input("请输入学生语文成绩>>>")
math_score = input("请输入学生数学成绩>>>")
english_score = input("请输入学生英语成绩>>>")
# 修改学生成绩
scores_dict = {
"chinese": chinese_score,
"math": math_score,
"english": english_score,
}
students_dict.get(sid).update({"scores": scores_dict})
print("修改成功")
print("students_dict", students_dict)
def delete_student():
'''
删除一个学生和对应成绩
'''
while 1:
sid = input("请输入学生学号>>>")
# 判断该学号是否存在
if sid in students_dict: # 该学号已经存在!
break
else: # # 该学号不存在!
print("该修改学号不存在!")
students_dict.pop(sid)
print("删除成功")
print("students_dict", students_dict)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# db_handler.serializer
import json
from core.scores_handler import students_dict
from conf.settings import student_scores_path
print("在serilizer中从core.scores_handler引入的students_dict", id(students_dict))
def init():
# 打开student_scores.json文件,读取json数据
try:
with open(student_scores_path, "r") as f:
student_scores_json = f.read()
# 反序列化
# students_dict = json.loads(student_scores_json) # 思考为什么不能这样写?
students_dict.update(json.loads(student_scores_json))
except FileNotFoundError:
print("这是第一次初始化...")
def save():
# 生成一个students_scores.json
# print(":::2", id(students_dict))
file = open(student_scores_path, "w")
students_json = json.dumps(students_dict)
file.write(students_json)
file.close()
|
1
2
3
4
5
6
7
8
9
|
# conf.settings
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
student_scores_path = os.path.join(BASE_DIR, "student_scores.json")
|
十一、面向对象

11.1、OOP编程思想
面向对象编程是在面向过程编程的基础上发展来的,它比面向过程编程具有更强的灵活性和扩展性。面向对象编程是程序员发展的分水岭,很多初学者会因无法理解面向对象而放弃学习编程。
面向对象编程(Object-oriented Programming,简称 OOP),是一种封装代码的方法。其实,在前面章节的学习中,我们已经接触了封装,比如说,将数据放进列表和字典中中,这就是一种简单的封装,是数据层面的封装;把常用的代码块打包成一个函数,这也是一种封装,是语句层面的封装。
代码封装,其实就是隐藏实现功能的具体代码,仅留给用户使用的接口,就好像使用计算机,用户只需要使用键盘、鼠标就可以实现一些功能,而根本不需要知道其内部是如何工作的。
本节所讲的面向对象编程,也是一种封装的思想,不过显然比以上两种封装更先进,它可以更好地模拟真实世界里的事物,并把描述特征的数据和代码块(函数)封装到一起。
11.2、类与实例对象
11.2.1、类和对象的概念
类是人们抽象出来的一个概念,所有拥有相同属性和功能的事物称为一个类;而拥有相同属性和功能的具体事物则成为这个类的实例对象。
11.2.2、声明类和实例化对象
面向对象最重要的概念就是类(Class)和实例(Instance),必须牢记类是抽象的模板,比如Person类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
案例演示:
1
2
3
4
5
|
class Person(object):
pass
p1=Person()
p2=Person()
|
每一个人的实例对象都应该有自己的属性,比如姓名和年龄,实例变量的赋值如下:
1
2
3
4
5
6
7
8
9
|
# 实例变量的增删改查
p1.name="alvin"
p1.age=18
p2.name="yuan"
p2.age=22
print(p1.gender)
del p2.age
|
11.2.3、对象的属性初始化
在创建类时,我们可以手动添加一个 __init__() 方法,该方法是一个特殊的类实例方法,称为构造方法(或构造函数)。
__init__() 方法可以包含多个参数,但必须包含一个名为 self 的参数,且必须作为第一个参数。
在 __init__() 构造方法中,除了 self 参数外,还可以自定义一些参数,参数之间使用逗号“,”进行分割,从而完成初始化的工作。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 定义Person类
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
print(id(self))
# 实例化Person类的实例对象: 类实例对象=类名(实例化参数)
alvin=Person("alvin",18)
yuan=Person("yuan",22)
print(id(alvin))
|
注意到__init__方法的第一个参数永远是self,表示创建的实例本身,因此,在__init__方法内部,就可以把各种属性绑定到self,因为self就指向创建的实例本身。
11.2.4、实例方法
实例方法或者叫对象方法,指的是我们在类中定义的普通方法。只有实例化对象之后才可以使用的方法,该方法的第一个形参接收的一定是对象本身。
1
2
3
4
5
6
7
8
9
10
11
12
|
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def print_info(self):
print("姓名:%s,年龄:%s"%(self.name,self.age))
yuan = Person("yuan",18)
yuan.print_info()
|
11.2.5、一切皆对象
在python语言中,一切皆对象!
我们之前学习过的字符串,列表,字典等等数据都是一个个的类,我们用的所有数据都是一个个具体的实例对象。
区别就是,那些类是在解释器级别注册好的,而现在我们学习的是自定义类,但语法使用都是相同的。所以,我们自定义的类实例对象也可以和其他数据对象一样可以进行传参、赋值等操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class Weapon:
def __init__(self, name, av, color):
self.name = name
self.av = av
self.color = color
jiguangqiang = Weapon("激光枪", 100, "red")
class Hero:
def __init__(self, name, sex, hp, ce, weapon, level=2, exp=2000, money=10000): # 类必不可少的方法,用于实例化
self.name = name # 英雄的名字
self.sex = sex # 英雄的性别
self.hp = hp # 英雄生命值
self.level = level # 英雄的等级
self.exp = exp # 英雄的经验值
self.money = money # 英雄的金币
self.weapon = weapon # 英雄的武器
yuan = Hero("yuan", "male", 100, 80, jiguangqiang)
print(yuan.weapon.color)
|
11.2.6、类对象和类属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class Person:
# 类属性
legs_num = 2
has_emotion = True
def __init__(self, name, age):
self.name = name
self.age = age
def play_fire(self):
print("%s玩火"%self.name)
# 实例对象和类对象可以获取类属性,但是只有类对象才能修改类属性
yuan = Person("yuan", 18)
alvin = Person("alvin", 18)
print(yuan.legs_num)
print(yuan.name)
# Person:一个类对象
print(Person.legs_num)
|
11.2.7、静态方法和类方法
静态方法
定义:使用装饰器@staticmethod。参数随意,没有self和cls参数,但是方法体中不能使用类或实例的任何属性和方法;
调用:类对象或实例对象都可以调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
class Cal():
@staticmethod
def add(x,y):
return x+y
@staticmethod
def mul(x,y):
return x*y
cal=Cal()
print(cal.add(1, 4))
or
print(Cal.add(3,4))
|
类方法
定义:使用装饰器@classmethod。第一个参数必须是当前类对象,该参数名一般约定为cls,通过它来传递类的属性和方法(不能传实例的属性和方法);
调用:类对象或实例对象都可以调用。
1
2
3
4
5
6
7
8
9
10
11
|
class Student:
# 类属性
cls_number = 68
@classmethod
def add_cls_number(cls):
cls.cls_number+=1
print(cls.cls_number)
Student.add_cls_number()
|
思考:
11.3、面向对象之继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
11.3.1、继承的基本使用
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码,能够大大的提高开发的效率。
实际上继承者是被继承者的特殊化,它除了拥有被继承者的特性外,还拥有自己独有得特性。例如猫有抓老鼠、爬树等其他动物没有的特性。同时在继承关系中,继承者完全可以替换被继承者,反之则不可以,例如我们可以说猫是动物,但不能说动物是猫就是这个道理,其实对于这个我们将其称之为“向上转型”。
诚然,继承定义了类如何相互关联,共享特性。对于若干个相同或者相识的类,我们可以抽象出他们共有的行为或者属相并将其定义成一个父类或者超类,然后用这些类继承该父类,他们不仅可以拥有父类的属性、方法还可以定义自己独有的属性或者方法。
同时在使用继承时需要记住三句话:
1、子类拥有父类非私有化的属性和方法。
2、子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
3、子类可以用自己的方式实现父类的方法。(下面会介绍)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
# 无继承方式
class Dog:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
def swimming(self):
print("swimming...")
class Cat:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
def climb_tree(self):
print("climb_tree...")
# 继承方式
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Dog(Animal):
def swimming(self):
print("toshetou...")
class Cat(Animal):
def climb_tree(self):
print("climb_tree...")
alex = Dog()
alex.run()
|
11.3.2、 重写父类方法和调用父类方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
class Person(object):
def __init__(self,name,age):
self.name=name
self.age=age
def sleep(self):
print("基类sleep...")
class Emp(Person):
# def __init__(self,name,age,dep):
# self.name = name
# self.age = age
# self.dep = dep
def __init__(self, name, age, dep):
# Person.__init__(self,name,age)
super().__init__(name,age)
self.dep = dep
def sleep(self):
if "不在公司":
# print("子类sleep...")
# 调用父类方法
# 方式1 :父类对象调用 父类对象.方法(self,其他参数)
# Person.sleep(self)
# 方式2: super关键字 super(子类对象,self).方法(参数)or super().方法(参数)
super().sleep()
yuan = Emp("yuan",18,"教学部")
yuan.sleep()
print(yuan.dep)
# 测试题:
class Base:
def __init__(self):
self.func()
def func(self):
print('in base')
class Son(Base):
def func(self):
print('in son')
s = Son()
|
11.3.3、 多重继承
如果在继承元组中列了一个以上的类,那么它就被称作"多重继承" 。派生类的声明,与他们的父类类似,继承的基类列表跟在类名之后,如下所示:
1
2
|
class SubClassName (ParentClass1[, ParentClass2, ...]):
...
|
多继承有什么意义呢?还拿上面的例子来说,蝙蝠和鹰都可以飞,飞的功能就重复定义了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Eagle(Animal):
def fly(self):
print("fly...")
class Bat(Animal):
def fly(self):
print("fly...")
|
有同学肯定想那就放到父类Animal中,可是那样的话其他不会飞的动物还怎么继承Animal呢?所以,这时候多重继承就发挥功能了:
1
2
3
4
5
6
7
8
9
|
class Fly:
def fly(self):
print("fly...")
class Eagle(Animal,Fly):
pass
class Bat(Animal,Fly):
pass
|
11.3.4、 type 和isinstance方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class Animal:
def eat(self):
print("eating...")
def sleep(self):
print("sleep...")
class Dog(Animal):
def swim(self):
print("swimming...")
alex = Dog()
mjj = Dog()
print(isinstance(alex,Dog))
print(isinstance(alex,Animal))
print(type(alex))
|
11.3.5、dir()方法和__dict__属性
dir(obj)可以获得对象的所有属性(包含方法)列表, 而obj.__dict__对象的自定义属性字典
注意事项:
dir(obj)获取的属性列表中,方法也认为属性的一种。返回的是listobj.__dict__只能获取自己自定义的属性,系统内置属性无法获取。返回是dict
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Student:
def __init__(self, name, score):
self.name = name
self.score = score
def test(self):
pass
yuan = Student("yuan", 100)
print("获取所有的属性列表")
print(dir(yuan))
print("获取自定义属性字段")
print(yuan.__dict__)
|
其中,类似__xx__的属性和方法都是有特殊用途的。如果调用len()函数视图获取一个对象的长度,其实在len()函数内部会自动去调用该对象的__len__()方法
11.4、面向对象之封装
封装是指隐藏对象的属性和实现细节,仅对外提供公共访问方式。
我们程序设计追求“高内聚,低耦合”
- 高内聚:类的内部数据操作细节自己完成,不允许外部干涉
- 低耦合:仅对外暴露少量的方法用于使用。
隐藏对象内部的复杂性,只对外公开简单的接口。便于外界调用,从而提高系统的可扩展性、可维护性。通俗的说,把该隐藏的隐藏起来,该暴露的暴露岀来。这就是封装性的设计思想。
11.4.1、私有属性
在class内部,可以有属性和方法,而外部代码可以通过直接调用实例变量的方法来操作数据,这样,就隐藏了内部的复杂逻辑。但是,从前面Student类的定义来看,外部代码还是可以自由地修改一个实例的name、score属性:
1
2
3
4
5
6
7
8
9
10
11
|
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
alvin=Student("alvin",66)
yuan=Student("yuan",88)
alvin.score=100
print(alvin.score)
|
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,所以,我们把Student类改一改:
1
2
3
4
5
6
7
8
9
10
11
|
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
alvin = Student("alvin",66)
yuan = Student("yuan",88)
print(alvin.__score)
|
改完后,对于外部代码来说,没什么变动,但是已经无法从外部访问实例变量.__name和实例变量.__score。
这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。
但是如果外部代码要获取name和score怎么办?可以给Student类增加get_score这样的方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
alvin=Student("alvin",66)
yuan=Student("yuan",88)
print(alvin.get_score())
|
如果又要允许外部代码修改age怎么办?可以再给Student类增加set_score方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
def set_score(self,score):
self.__score = score
alvin=Student("alvin",12)
print(alvin.get_score())
alvin.set_score(100)
print(alvin.get_score())
|
你也许会问,原先那种直接通过alvin.score = 100也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以设置值时做其他操作,比如记录操作日志,对参数做检查,避免传入无效的参数等等:
1
2
3
4
5
6
7
|
class Student(object):
...
def set_score(self,score):
if isinstance(score,int) and 0 <= score <= 100:
self.__score = score
else:
raise ValueError('error!')
|
注意
1、这种机制也并没有真正意义上限制我们从外部直接访问属性,知道了类名和属性名就可以拼出名字:
_类名__属性,然后就可以访问了,如a._A__N
2、变形的过程只在类的内部生效,在定义后的赋值操作,不会变形
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class Student(object):
def __init__(self, name, score):
self.name = name
self.__score = score
def get_score(self):
return self.__score
yuan=Student("yuan",66)
print(yuan.__dict__)
yuan.__age=18
print(yuan.__dict__)
|
4、单下划线、双下划线、头尾双下划线说明:
-
__foo__: 定义的是特殊方法,一般是系统定义名字 ,类似 __init__() 之类的。
-
_foo: 以单下划线开头的表示的是 protected 类型的变量,即保护类型只能允许其本身与子类进行访问。(约定成俗,不限语法)
-
__foo: 双下划线的表示的是私有类型(private)的变量, 只能是允许这个类本身进行访问了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Person(object):
def __init__(self, name, score):
self.name = name
self.__score = score
class Student(Person):
def get_score(self):
return self.__score
def set_score(self,score):
self.__score=score
yuan=Student("yuan",66)
print(yuan.__dict__)
print(yuan.get_score())
|
11.4.2、 私有方法
在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
class Base:
def foo(self):
print("foo from Base")
def test(self):
self.foo()
class Son(Base):
def foo(self):
print("foo from Son")
s=Son()
s.test()
class Base:
def __foo(self):
print("foo from Base")
def test(self):
self.__foo()
class Son(Base):
def __foo(self):
print("foo from Son")
s=Son()
s.test()
|
11.4.3、 property属性装饰器
使用接口函数获取修改数据 和 使用点方法设置数据相比, 点方法使用更方便,我们有什么方法达到 既能使用点方法,同时又能让点方法直接调用到我们的接口了,答案就是property属性装饰器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
class Student(object):
def __init__(self,name,score,sex):
self.__name = name
self.__score = score
self.__sex = sex
@property
def name(self):
return self.__name
@name.setter
def name(self,name):
if len(name) > 1 :
self.__name = name
else:
print("name的长度必须要大于1个长度")
@property
def score(self):
return self.__score
# @score.setter
# def score(self, score):
# if score > 0 and score < 100:
# self.__score = score
# else:
# print("输入错误!")
yuan = Student('yuan',18,'male')
yuan.name = '苑昊' # 调用了score(self, score)函数设置数据
print(yuan.name) # 调用了score(self)函数获取数据
yuan.score = 199
print(yuan.score)
|
注意,使用 @property 装饰器时,接口名不必与属性名相同。
python提供了更加人性化的操作,可以通过限制方式完成只读、只写、读写、删除等各种操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
class Person:
def __init__(self, name):
self.__name = name
def __get_name(self):
return self.__name
def __set_name(self, name):
self.__name = name
def __del_name(self):
del self.__name
# property()中定义了读取、赋值、删除的操作
# name = property(__get_name, __set_name, __del_name)
name = property(__get_name, __set_name)
yuan = Person("yuan")
print(yuan.name) # 合法:调用__get_name
yuan.name = "苑昊" # 合法:调用__set_name
print(yuan.name)
# property中没有添加__del_name函数,所以不能删除指定的属性
del p.name # 错误:AttributeError: can't delete Attribute
|
@property广泛应用在类的定义中,可以让调用者写出简短的代码,同时保证对参数进行必要的检查,这样,程序运行时就减少了出错的可能性。
11.5、面向对象之多态
11.5.1、java多态
在java里,多态是同一个行为具有不同表现形式或形态的能力,即对象多种表现形式的体现,就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
如下图所示:使用手机扫描二维码支付时,二维码并不知道客户是通过何种方式进行支付,只有通过二维码后才能判断是走哪种支付方式执行对应流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
// 支付抽象类或者接口
public class Pay {
public String pay() {
System.out.println("do nothing!")
return "success"
}
}
// 支付宝支付
public class AliPay extends Pay {
@Override
public String pay() {
System.out.println("支付宝pay");
return "success";
}
}
// 微信支付
public class WeixinPay extends Pay {
@Override
public String pay() {
System.out.println("微信Pay");
return "success";
}
}
// 银联支付
public class YinlianPay extends Pay {
@Override
public String pay() {
System.out.println("银联支付");
return "success";
}
}
// 测试支付
public static void main(String[] args) {
// 测试支付宝支付多态应用
Pay pay = new AliPay();
pay.pay();
// 测试微信支付多态应用
pay = new WeixinPay();
pay.pay();
// 测试银联支付多态应用
pay = new YinlianPay();
pay.pay();
}
// 输出结果如下:
支付宝pay
微信Pay
银联支付
|
多态存在的三个必要条件:
比如:
1
|
Pay pay = new AliPay();
|
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
11.5.2、java的抽象类与接口类
这样实现当然是可行的,但其实有一个小小的问题,就是Pay类当中的pay方法多余了。因为我们使用的只会是它的子类,并不会用到Pay这个父类。所以我们没必要实现父类Pay中的pay方法,做一个标记,表示有这么一个方法**,子类实现的时候需要实现它就可以了。
这就是抽象类和抽象方法的来源,我们可以把Pay做成一个抽象类,声明pay是一个抽象方法。抽象类是不能直接创建实例的,只能创建子类的实例,并且抽象方法也不用实现,只需要标记好参数和返回就行了。具体的实现都在子类当中进行。说白了抽象方法就是一个标记,告诉编译器凡是继承了这个类的子类必须要实现抽象方法,父类当中的方法不能调用。那抽象类就是含有抽象方法的类。
我们写出Pay变成抽象类之后的代码:
1
2
3
|
public abstract class Pay {
abstract public String pay();
}
|
很简单,因为我们只需要定义方法的参数就可以了,不需要实现方法的功能,方法的功能在子类当中实现。由于我们标记了pay这个方法是一个抽象方法,凡是继承了Pay的子类都必须要实现这个方法,否则一定会报错。
抽象类其实是一个擦边球,我们可以在抽象类中定义抽象的方法也就是只声明不实现,也可以在抽象类中实现具体的方法。在抽象类当中非抽象的方法,子类的实例是可以直接调用的,和子类调用父类的普通方法一样。但假如我们不需要父类实现方法,我们提出提取出来的父类中的所有方法都是抽象的呢?针对这一种情况,Java当中还有一个概念叫做接口,也就是interface,本质上来说interface就是抽象类,只不过是只有抽象方法的抽象类。
所以刚才的Pay通过接口实现如下:
1
2
3
|
interface Pay {
String pay();
}
|
把Pay变成了interface之后,子类的实现没什么太大的差别,只不过将extends关键字换成了implements。另外,子类只能继承一个抽象类,但是可以实现多个接口。早先的Java版本当中,interface只能够定义方法和常量,在Java8以后的版本当中,我们也可以在接口当中实现一些默认方法和静态方法。
接口的好处是很明显的,我们可以用接口的实例来调用所有实现了这个接口的类。也就是说接口和它的实现是一种要宽泛许多的继承关系,大大增加了灵活性。
以上虽然全是Java的内容,但是讲的其实是面向对象的内容,如果没有学过Java的小伙伴可能看起来稍稍有一点点吃力,但总体来说问题不大,没必要细扣当中的语法细节,get到核心精髓就可以了。
11.5.3、Python的抽象类和接口类
在Python中定义一个接口类,我们需要abc模块(抽象类基类,Abstract Base Classes)中的两个工具abstractmethod, ABCMeta,详情如下:
| 工具 |
说明 |
| abstractmethod |
抽象类的装饰器,接口类中的接口需要使用此装饰器 |
| ABCMeta |
抽象类元类 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
from abc import ABCMeta, abstractmethod # (抽象方法)
class Payment(metaclass=ABCMeta): # metaclass 元类 metaclass = ABCMeta表示Payment类是一个规范类
def __init__(self, name, money):
self.money = money
self.name = name
@abstractmethod # @abstractmethod表示下面一行中的pay方法是一个必须在子类中实现的方法
def pay(self, *args, **kwargs):
pass
class AliPay(Payment):
def pay(self):
# 支付宝提供了一个网络上的联系渠道
print('%s通过支付宝消费了%s元' % (self.name, self.money))
class WeChatPay(Payment):
def pay(self):
# 微信提供了一个网络上的联系渠道
print('%s通过微信消费了%s元' % (self.name, self.money))
class Order(object):
@staticmethod
def account(pay_obj):
pay_obj.pay()
pay1 = WeChatPay("yuan", 100)
pay2 = AliPay("alvin", 200)
order = Order()
order.account(pay1)
order.account(pay1)
|
11.6、反射
反射这个术语在很多语言中都存在,并且存在大量的运用,今天我们说说什么是反射,反射主要是指程序可以访问、检测和修改它本身状态或行为的一种能力,在python中一切皆对象(类,实例,模块等等都是对象),那么我们就可以通过反射的形式操作对象相关的属性。
Python中的反射主要有下面几个方法:
1
2
3
4
5
6
7
|
# 1.hasattr(object,name): 判断对象中有没有一个name字符串对应的方法或属性
# 2.getattr(object, name, default=None): 获取对象name字符串属性的值,如果不存在返回default的值
# 3.setattr(object, key, value): 设置对象的key属性为value值,等同于object.key = value
# 4.delattr(object, name): 删除对象的name字符串属性
|
应用1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
class Person:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
yuan=Person("yuan",22,"male")
print(yuan.name)
print(yuan.age)
print(yuan.gender)
while 1:
# 由用户选择查看yuan的哪一个信息
attr = input(">>>")
if hasattr(yuan, attr):
val = getattr(yuan, attr)
print(val)
else:
val=input("yuan 没有你该属性信息!,请设置该属性值>>>")
setattr(yuan,attr,val)
|
应用2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
class FTP(object):
def __init__(self):
self.run()
def run(self):
print('''
提示:
上传: put 路径/文件名称
下载: get 路径/文件名称
'''
)
while 1:
input_str=input(">>>")
action,params=input_str.split(" ")
if hasattr(self,action):
getattr(self,action)()
else:
print("不存在该方法")
def put(self):
print("上传...")
def get(self):
print("下载...")
ftp=FTP()
|
11.7、魔法方法
Python 里有一种方法,叫做魔法方法。Python 的类里提供的,两个下划线开始,两个下划线结束的方法,就是魔法方法,魔法方法在恰当的时候就会被激活,自动执行。
1.7.1、__new__()方法
类名() 创建对象时,在自动执行 init()方法前,会先执行 object.__new__方法,在内存中开辟对象空间并返回
1
2
3
4
5
6
7
8
9
10
11
12
|
class Person(object):
def __new__(cls, *args, **kwargs):
print("__new__方法执行")
# return object.__new__(cls)
def __init__(self, name, age):
print("__init__方法执行")
self.name = name
self.age = age
yuan = Person("yuan", 23)
|
11.7.2、__str__方法
改变对象的字符串显示。可以理解为使用print函数打印一个对象时,会自动调用对象的__str__方法
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class Person(object):
def __init__(self, name, age):
print("__init__方法执行")
self.name = name
self.age = age
def __str__(self):
return self.name
yuan = Person("yuan", 23)
print(yuan)
|
11.7.3、__repr__方法
在python解释器环境下,会默认显示对象的repr表示。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
# __str__ 的返回结果可读性强。也就是说,__str__ 的意义是得到便于人们阅读的信息
# __repr__ 存在的目的在于调试,便于开发者使用
# 案例1:
class A():
... def __str__(self):
... return "str"
...
... def __repr__(self):
... return "repr"
... a = A()
a
repr
print(a)
str
# 案例2:
import datetime
date = datetime.datetime.now()
print(str(date)) # '2021-05-21 12:04:02.671735'
print(repr(date)) # 'datetime.datetime(2021, 5, 21, 12, 4, 2, 671735)'
# 案例3:
import json
dic = {"name":"yuan","age":23}
data = json.dumps(dic)
print(str(data))
print(repr(data))
|
11.7.4、__del__方法
析构方法,当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以析构函数的调用是由解释器在进行垃圾回收时自动触发执行的。
1
2
3
4
5
6
7
8
9
10
11
12
|
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __del__(self):
print("%s删除了" % self.name)
yuan = Person("yuan", 23)
# del yuan
|
11.7.5、__eq__ 方法
拥有__eq__方法的对象支持相等的比较操作
1
2
3
4
5
6
7
8
9
10
11
12
13
|
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __eq__(self, obj):
return self.name == obj.name
yuan = Person("yuan", 23)
alvin = Person("alvin", 23)
print(yuan == alvin)
|
11.7.6、__len__方法
1
2
3
4
5
6
|
class G(object):
def __len__(self):
return 100
g=G()
print(len(g))
|
11.7.7、item系列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __getitem__(self, item):
print('obj[key]取值时,执行__getitem__')
print("取值为:",self.__dict__[item])
def __setitem__(self, key, value):
print('obj[key]=value赋值时,执行__setitem__')
self.__dict__[key] = value
def __delitem__(self, key):
print('del obj[key]触发')
self.__dict__.pop(key)
# obj.["key"]的方式触发__xxxitem__魔法方法
yuan = Person("yuan", 23)
name = yuan["name"] # 触发__getitem__执行
yuan["age"] = 18 # 触发__setattr__执行
del yuan["age"] # 触发__delitem__
|
11.7.8、attr系列
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
class Person(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __getattr__(self, item):
print('获取 obj.attr时触发,属性不存在的时候才会触发')
def __setattr__(self, key, value):
print('obj.attr=value时触发,添加修改属性时可以使用')
# self.key=value #这就无限递归了,你好好想想
self.__dict__[key]=value #应该使用它
def __delattr__(self, item):
print('del obj.attr 时触发,删除属性的时候会触发')
# del self.item #无限递归了
self.__dict__.pop(item)
# obj.attr的方式触发__xxxattr__魔法方法
yuan = Person("yuan", 23)
print(yuan.name)
print(yuan.__dict__)
|
11.8、异常机制
首先我们要理解什么叫做**“异常”**?
- 在程序运行过程中,总会遇到各种各样的问题和错误。
- 有些错误是我们编写代码时自己造成的:比如语法错误、调用错误,甚至逻辑错误。
- 还有一些错误,则是不可预料的错误,但是完全有可能发生的:比如文件不存在、磁盘空间不足、网络堵塞、系统错误等等。
这些导致程序在运行过程中出现异常中断和退出的错误,我们统称为异常。大多数的异常都不会被程序处理,而是以错误信息的形式展现出来。
异常的分类:
- 异常有很多种类型,Python内置了几十种常见的异常,无需特别导入,直接就可使用。
- 需要注意的是,所有的异常都是异常类,首字母是大写的!
异常的危害:
11.8.1、基本语法
异常的基本结构:try except
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# (1)通用异常
try:
pass # 正常执行语句
except Exception as ex:
pass # 异常处理语句
# (2)指定异常
try:
pass # 正常执行语句
except <异常名>:
pass # 异常处理语句
#(3) 捕获多个异常
# 捕获多个异常有两种方式,第一种是一个except同时处理多个异常,不区分优先级:
try:
pass # 正常执行语句
except (<异常名1>, <异常名2>, ...):
pass # 异常处理语句
# 第二种是区分优先级的:
try:
pass # 正常执行语句
except <异常名1>:
pass # 异常处理语句1
except <异常名2>:
pass # 异常处理语句2
except <异常名3>:
pass # 异常处理语句3
# 异常嵌套
try:
try:
with open("abc") as f:
pass
except NameError as e:
print(e)
except OSError as e:
print("OSError:",e.strerror)
|
机制说明:
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常那么对应的except子句将被执行。
- 在Python的异常中,有一个通用异常:
Exception,它可以捕获任意异常。
11.8.2、finally
1
2
3
4
5
6
|
try:
pass # 正常执行语句
except Exception as e:
pass # 异常处理语句
finally:
pass # 无论是否发生异常一定要执行的语句,比如关闭文件,数据库或者socket
|
11.8.3、raise语句
很多时候,我们需要主动抛出一个异常。Python内置了一个关键字raise,可以主动触发异常。
raise可以抛出自定义异常,我们已将在前面看到了python内置的一些常见的异常类型。大多数情况下,内置异常已经够用了。但是有时候你还是需要自定义一些异常:自定义异常应该继承Exception类,直接继承或者间接继承都可以,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
# 1.用户自定义异常类型
class TooLongExceptin(Exception):
"this is user's Exception for check the length of name "
def __init__(self, len):
self.len = len
def __str__(self):
return "输入姓名长度是" + str(self.len) + ",超过长度了"
try:
name = input("enter your name:")
if len(name) > 5:
raise TooLongExceptin(len(name))
else:
print(name)
except TooLongExceptin as error: # 这里异常类型是用户自定义的
print("打印异常信息:", error)
|
十二、网络编程
网络编程:使用编程语言实现多台计算机的通信。
12.1、网络三要素
网络编程三要素:
(1)IP地址:网络中每一台计算机的唯一标识,通过IP地址找到指定的计算机。
(2)端口:用于标识进程的逻辑地址,通过端口找到指定进程。
(3)协议:定义通信规则,符合协议则可以通信,不符合不能通信。一般有TCP协议和UDP协议。
(1)IP地址
计算机分布在世界各地,要想和它们通信,必须要知道确切的位置。确定计算机位置的方式有多种,IP 地址是最常用的,例如,114.114.114.114 是国内第一个、全球第三个开放的 DNS 服务地址,127.0.0.1 是本机地址。
其实,我们的计算机并不知道 IP 地址对应的地理位置,当要通信时,只是将 IP 地址封装到要发送的数据包中,交给路由器去处理。路由器有非常智能和高效的算法,很快就会找到目标计算机,并将数据包传递给它,完成一次单向通信。
目前大部分软件使用 IPv4 地址,但 IPv6 也正在被人们接受,尤其是在教育网中,已经大量使用。
(2)端口
有了 IP 地址,虽然可以找到目标计算机,但仍然不能进行通信。一台计算机可以同时提供多种网络服务,例如Web服务、FTP服务(文件传输服务)、SMTP服务(邮箱服务)等,仅有 IP 地址,计算机虽然可以正确接收到数据包,但是却不知道要将数据包交给哪个网络程序来处理,所以通信失败。
为了区分不同的网络程序,计算机会为每个网络程序分配一个独一无二的端口号(Port Number),例如,Web服务的端口号是 80,FTP 服务的端口号是 21,SMTP 服务的端口号是 25。
端口(Port)是一个虚拟的、逻辑上的概念。可以将端口理解为一道门,数据通过这道门流入流出,每道门有不同的编号,就是端口号。如下图所示:

(3)协议
协议(Protocol)就是网络通信的约定,通信的双方必须都遵守才能正常收发数据。协议有很多种,例如 TCP、UDP、IP 等,通信的双方必须使用同一协议才能通信。协议是一种规范,由计算机组织制定,规定了很多细节,例如,如何建立连接,如何相互识别等。
协议仅仅是一种规范,必须由计算机软件来实现。例如 IP 协议规定了如何找到目标计算机,那么各个开发商在开发自己的软件时就必须遵守该协议,不能另起炉灶。
所谓协议族(Protocol Family),就是一组协议(多个协议)的统称。最常用的是 TCP/IP 协议族,它包含了 TCP、IP、UDP、Telnet、FTP、SMTP 等上百个互为关联的协议,由于 TCP、IP 是两种常用的底层协议,所以把它们统称为 TCP/IP 协议族。
(4)数据传输方式
计算机之间有很多数据传输方式,各有优缺点,常用的有两种:SOCK_STREAM 和 SOCK_DGRAM。
-
SOCK_STREAM 表示面向连接的数据传输方式。数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送,但效率相对较慢。常见的 http 协议就使用 SOCK_STREAM 传输数据,因为要确保数据的正确性,否则网页不能正常解析。
-
SOCK_DGRAM 表示无连接的数据传输方式。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。因为 SOCK_DGRAM 所做的校验工作少,所以效率比 SOCK_STREAM 高。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
注意:SOCK_DGRAM 没有想象中的糟糕,不会频繁的丢失数据,数据错误只是小概率事件。
有可能多种协议使用同一种数据传输方式,所以在 socket 编程中,需要同时指明数据传输方式和协议。
综上所述:IP地址和端口能够在广袤的互联网中定位到要通信的程序,协议和数据传输方式规定了如何传输数据,有了这些,两台计算机就可以通信了。
12.2、TCP协议
(1)OSI模型
如果你读过计算机专业,或者学习过网络通信,那你一定听说过 OSI 模型,它曾无数次让你头大。OSI 是 Open System Interconnection 的缩写,译为“开放式系统互联”。
OSI 模型把网络通信的工作分为 7 层,从下到上分别是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。
这个网络模型究竟是干什么呢?简而言之就是进行数据封装的。
当另一台计算机接收到数据包时,会从网络接口层再一层一层往上传输,每传输一层就拆开一层包装,直到最后的应用层,就得到了最原始的数据,这才是程序要使用的数据。
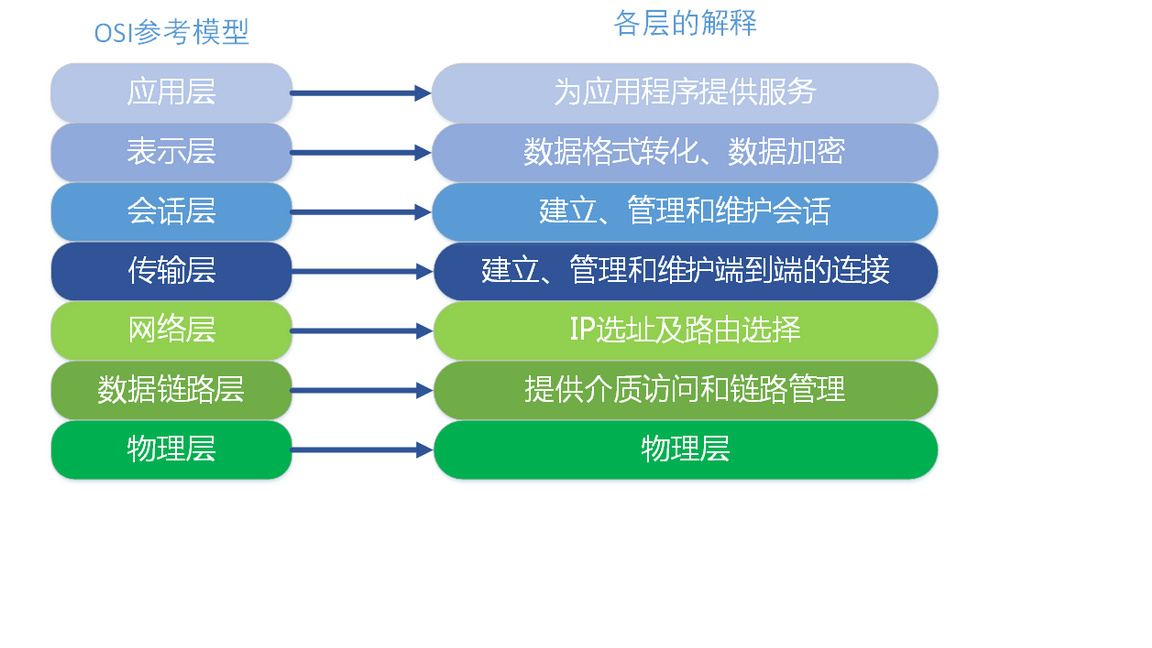
(2)TCP报文格式
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的通信协议,数据在传输前要建立连接,传输完毕后还要断开连接。
客户端在收发数据前要使用 connect() 函数和服务器建立连接。建立连接的目的是保证IP地址、端口、物理链路等正确无误,为数据的传输开辟通道。
TCP建立连接时要传输三个数据包,俗称三次握手(Three-way Handshaking)。可以形象的比喻为下面的对话:
- [Shake 1] 套接字A:“你好,套接字B,我这里有数据要传送给你,建立连接吧。”
- [Shake 2] 套接字B:“好的,我这边已准备就绪。”
- [Shake 3] 套接字A:“谢谢你受理我的请求。”
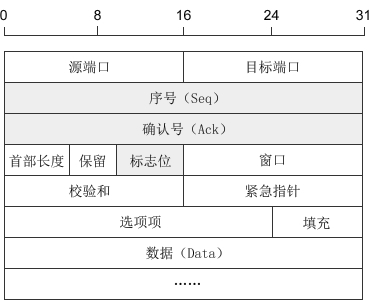
-
序号:Seq(Sequence Number)序号占32位,用来标识从计算机A发送到计算机B的数据包的序号,计算机发送数据时对此进行标记。
-
确认号:Ack(Acknowledge Number)确认号占32位,客户端和服务器端都可以发送,Ack = Seq + 1。
-
标志位:每个标志位占用1Bit,共有6个,分别为 URG、ACK、PSH、RST、SYN、FIN,具体含义如下:
1
2
3
4
5
6
|
// URG:紧急指针(urgent pointer)有效。
// ACK:确认序号有效。
// PSH:接收方应该尽快将这个报文交给应用层。
// RST:重置连接。
// SYN:建立一个新连接。
// FIN:断开一个连接。
|
(3)TCP/IP三次握手
使用 connect() 建立连接时,客户端和服务器端会相互发送三个数据包,请看下图:
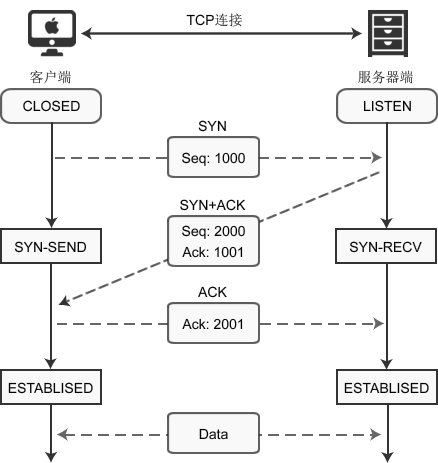
客户端调用 socket() 创建套接字后,因为没有建立连接,所以套接字处于CLOSED状态;服务器端调用 listen() 函数后,套接字进入LISTEN状态,开始监听客户端请求。这个时候,客户端开始发起请求:
-
当客户端调用 connect() 函数后,TCP协议会组建一个数据包,并设置 SYN 标志位,表示该数据包是用来建立同步连接的。同时生成一个随机数字 1000,填充“序号(Seq)”字段,表示该数据包的序号。完成这些工作,开始向服务器端发送数据包,客户端就进入了SYN-SEND状态。
-
服务器端收到数据包,检测到已经设置了 SYN 标志位,就知道这是客户端发来的建立连接的“请求包”。服务器端也会组建一个数据包,并设置 SYN 和 ACK 标志位,SYN 表示该数据包用来建立连接,ACK 用来确认收到了刚才客户端发送的数据包。 服务器生成一个随机数 2000,填充“序号(Seq)”字段。2000 和客户端数据包没有关系。服务器将客户端数据包序号(1000)加1,得到1001,并用这个数字填充“确认号(Ack)”字段。服务器将数据包发出,进入SYN-RECV状态。
-
客户端收到数据包,检测到已经设置了 SYN 和 ACK 标志位,就知道这是服务器发来的“确认包”。客户端会检测“确认号(Ack)”字段,看它的值是否为 1000+1,如果是就说明连接建立成功。接下来,客户端会继续组建数据包,并设置 ACK 标志位,表示客户端正确接收了服务器发来的“确认包”。同时,将刚才服务器发来的数据包序号(2000)加1,得到 2001,并用这个数字来填充“确认(Ack)”字段。客户端将数据包发出,进入ESTABLISED状态,表示连接已经成功建立。
-
服务器端收到数据包,检测到已经设置了 ACK 标志位,就知道这是客户端发来的“确认包”。服务器会检测“确认号(Ack)”字段,看它的值是否为 2000+1,如果是就说明连接建立成功,服务器进入ESTABLISED状态。至此,客户端和服务器都进入了ESTABLISED状态,连接建立成功,接下来就可以收发数据了。
注意:三次握手的关键是要确认对方收到了自己的数据包,这个目标就是通过“确认号(Ack)”字段实现的。计算机会记录下自己发送的数据包序号 Seq,待收到对方的数据包后,检测“确认号(Ack)”字段,看Ack = Seq + 1是否成立,如果成立说明对方正确收到了自己的数据包
(4)TCP/IP四次挥手
建立连接非常重要,它是数据正确传输的前提;断开连接同样重要,它让计算机释放不再使用的资源。如果连接不能正常断开,不仅会造成数据传输错误,还会导致套接字不能关闭,持续占用资源,如果并发量高,服务器压力堪忧。
建立连接需要三次握手,断开连接需要四次握手,可以形象的比喻为下面的对话:
- [Shake 1] 套接字A:“任务处理完毕,我希望断开连接。”
- [Shake 2] 套接字B:“哦,是吗?请稍等,我准备一下。”
- 等待片刻后……
- [Shake 3] 套接字B:“我准备好了,可以断开连接了。”
- [Shake 4] 套接字A:“好的,谢谢合作。”
下图演示了客户端主动断开连接的场景:

建立连接后,客户端和服务器都处于ESTABLISED状态。这时,客户端发起断开连接的请求:
-
客户端调用 close() 函数后,向服务器发送 FIN 数据包,进入FIN_WAIT_1状态。FIN 是 Finish 的缩写,表示完成任务需要断开连接。
-
服务器收到数据包后,检测到设置了 FIN 标志位,知道要断开连接,于是向客户端发送“确认包”,进入CLOSE_WAIT状态。注意:服务器收到请求后并不是立即断开连接,而是先向客户端发送“确认包”,告诉它我知道了,我需要准备一下才能断开连接。
-
客户端收到“确认包”后进入FIN_WAIT_2状态,等待服务器准备完毕后再次发送数据包。
-
等待片刻后,服务器准备完毕,可以断开连接,于是再主动向客户端发送 FIN 包,告诉它我准备好了,断开连接吧。然后进入LAST_ACK状态。
-
客户端收到服务器的 FIN 包后,再向服务器发送 ACK 包,告诉它你断开连接吧。然后进入TIME_WAIT状态。
-
服务器收到客户端的 ACK 包后,就断开连接,关闭套接字,进入CLOSED状态。
注意:关于 TIME_WAIT 状态的说明
客户端最后一次发送 ACK包后进入 TIME_WAIT 状态,而不是直接进入 CLOSED 状态关闭连接,这是为什么呢?
1
2
3
4
5
6
7
8
|
/*
TCP 是面向连接的传输方式,必须保证数据能够正确到达目标机器,不能丢失或出错,而网络是不稳定的,随时可能会毁坏数据,所以机器A每次向机器B发送数据包后,都要求机器B”确认“,回传ACK包,告诉机器A我收到了,这样机器A才能知道数据传送成功了。
如果机器B没有回传ACK包,机器A会重新发送,直到机器B回传ACK包。
客户端最后一次向服务器回传ACK包时,有可能会因为网络问题导致服务器收不到,服务器会再次发送 FIN 包,如果这时客户端完全关闭了连接,那么服务器无论如何也收不到ACK包了,所以客户端需要等待片刻、确认对方收到ACK包后才能进入CLOSED状态。
那么,要等待多久呢?数据包在网络中是有生存时间的,超过这个时间还未到达目标主机就会被丢弃,并通知源主机。
这称为报文最大生存时间(MSL,Maximum Segment Lifetime)。
TIME_WAIT 要等待 2MSL 才会进入 CLOSED 状态。ACK 包到达服务器需要 MSL 时间,服务器重传 FIN 包也需要 MSL 时间,2MSL 是数据包往返的最大时间,如果 2MSL 后还未收到服务器重传的 FIN 包,就说明服务器已经收到了 ACK 包。
*/
|
12.3、socket介绍
12.3.1、什么是 socket?
socket 的原意是“插座”,在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
我们把插头插到插座上就能从电网获得电力供应,同样,为了与远程计算机进行数据传输,需要连接到因特网,而 socket 就是用来连接到因特网的工具。

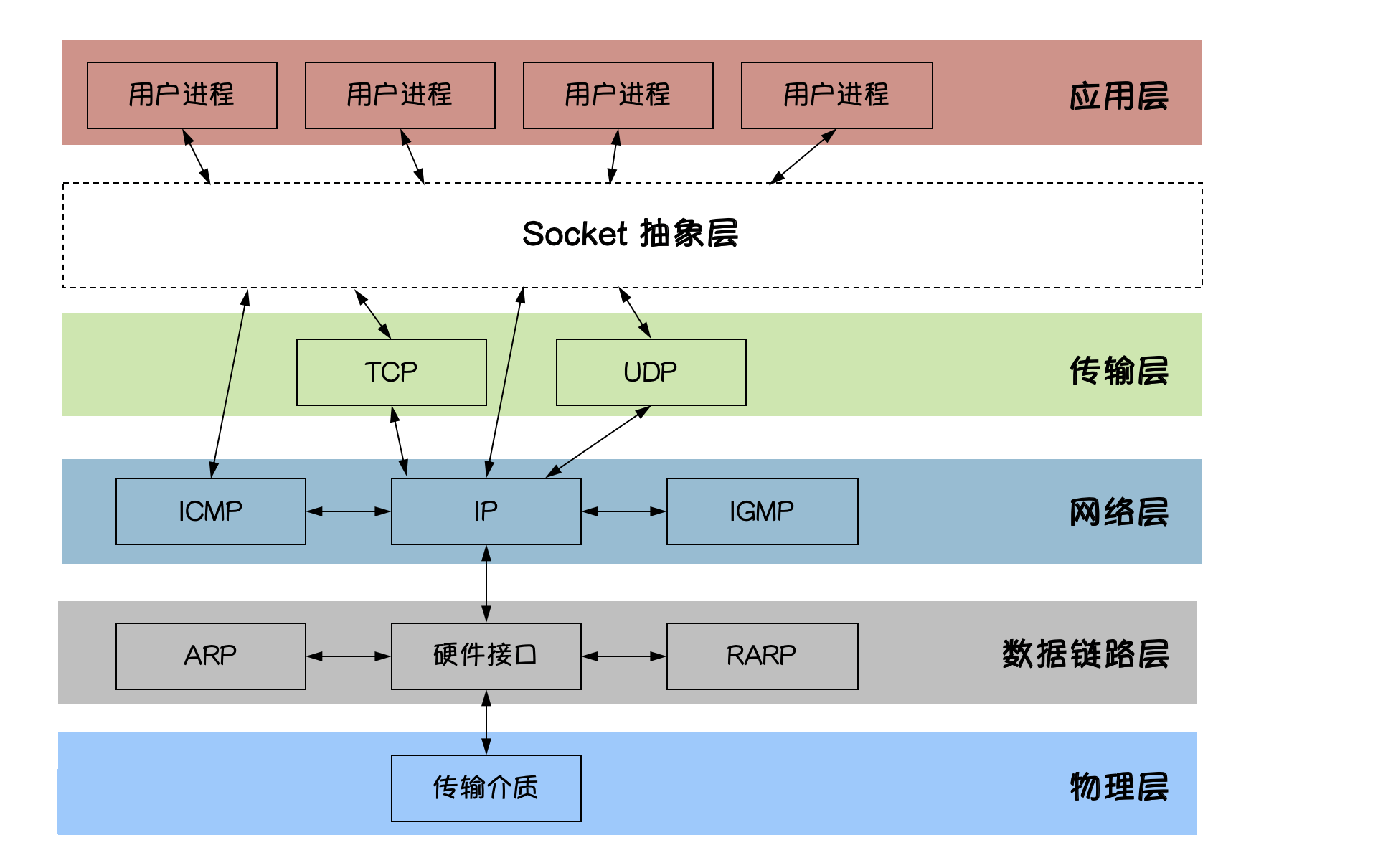
12.3.2、socket缓冲区与阻塞
1、socket缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
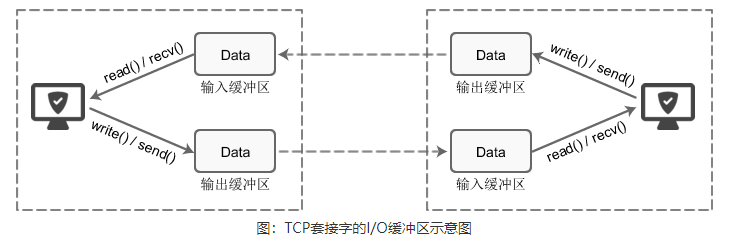
这些I/O缓冲区特性可整理如下:
- I/O缓冲区在每个TCP套接字中单独存在;
- I/O缓冲区在创建套接字时自动生成;
- 即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
- 关闭套接字将丢失输入缓冲区中的数据。
输入输出缓冲区的默认大小一般都是 8K!
2、阻塞模式
对于TCP套接字(默认情况下),当使用send() 发送数据时:
(1) 首先会检查缓冲区,如果缓冲区的可用空间长度小于要发送的数据,那么 send() 会被阻塞(暂停执行),直到缓冲区中的数据被发 送到目标机器,腾出足够的空间,才唤醒 send() 函数继续写入数据。
(2) 如果TCP协议正在向网络发送数据,那么输出缓冲区会被锁定,不允许写入,send() 也会被阻塞,直到数据发送完毕缓冲区解锁, send() 才会被唤醒。
(3) 如果要写入的数据大于缓冲区的最大长度,那么将分批写入。
(4) 直到所有数据被写入缓冲区 send() 才能返回。
当使用recv() 读取数据时:
(1) 首先会检查缓冲区,如果缓冲区中有数据,那么就读取,否则函数会被阻塞,直到网络上有数据到来。
(2) 如果要读取的数据长度小于缓冲区中的数据长度,那么就不能一次性将缓冲区中的所有数据读出,剩余数据将不断积压,直到有 recv() 函数再次读取。
(3) 直到读取到数据后 recv() 函数才会返回,否则就一直被阻塞。
TCP套接字默认情况下是阻塞模式,也是最常用的。当然你也可以更改为非阻塞模式,后续我们会讲解。
12.3.3、TCP的粘包问题
上节我们讲到了socket缓冲区和数据的传递过程,可以看到数据的接收和发送是无关的,read()/recv() 函数不管数据发送了多少次,都会尽可能多的接收数据。也就是说,read()/recv() 和 write()/send() 的执行次数可能不同。
例如,write()/send() 重复执行三次,每次都发送字符串"abc”,那么目标机器上的 read()/recv() 可能分三次接收,每次都接收"abc";也可能分两次接收,第一次接收"abcab",第二次接收"cabc";也可能一次就接收到字符串"abcabcabc"。
这就是数据的“粘包”问题,客户端发送的多个数据包被当做一个数据包接收。也称数据的无边界性,read()/recv() 函数不知道数据包的开始或结束标志(实际上也没有任何开始或结束标志),只把它们当做连续的数据流来处理。
12.4、Python的socket模块
12.4.1、创建套接字对象
Linux 中的一切都是文件,每个文件都有一个整数类型的文件描述符;socket 也可以视为一个文件对象,也有文件描述符。
1
2
3
4
|
import socket
sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# <socket.socket fd=496, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0>
print(sock)
|
1、AF 为地址族(Address Family),也就是 IP 地址类型,常用的有 AF_INET 和 AF_INET6。AF_INET 表示 IPv4 地址,AF_INET6 表示 IPv6 地址。大家需要记住127.0.0.1,它是一个特殊IP地址,表示本机地址。
2、 type 为数据传输方式/套接字类型,常用的有 SOCK_STREAM(流格式套接字/面向连接的套接字) 和 SOCK_DGRAM(数据报套接字/无连接的套接字)。
3、sock = socket.socket()默认创建TCP套接字。
12.4.2、 套接字对象方法
(1)服务端:bind方法
socket 用来创建套接字对象,确定套接字的各种属性,然后服务器端要用 bind() 方法将套接字与特定的 IP 地址和端口绑定起来,只有这样,流经该 IP 地址和端口的数据才能交给套接字处理。类似地,客户端也要用 connect() 方法建立连接。
1
2
3
4
|
import socket
sock = socket.socket()
sock.bind(("127.0.0.1",8899))
|
(2)服务端:listen方法
通过 listen() 方法可以让套接字进入被动监听状态,sock 为需要进入监听状态的套接字,backlog 为请求队列的最大长度。所谓被动监听,是指当没有客户端请求时,套接字处于“睡眠”状态,只有当接收到客户端请求时,套接字才会被“唤醒”来响应请求。当套接字正在处理客户端请求时,如果有新的请求进来,套接字是没法处理的,只能把它放进缓冲区,待当前请求处理完毕后,再从缓冲区中读取出来处理。如果不断有新的请求进来,它们就按照先后顺序在缓冲区中排队,直到缓冲区满。这个缓冲区,就称为请求队列(Request Queue)。
缓冲区的长度(能存放多少个客户端请求)可以通过 listen() 方法的 backlog 参数指定,但究竟为多少并没有什么标准,可以根据你的需求来定,并发量小的话可以是10或者20。
如果将 backlog 的值设置为SOMAXCONN ,就由系统来决定请求队列长度,这个值一般比较大,可能是几百,或者更多。当请求队列满时,就不再接收新的请求。
注意:listen() 只是让套接字处于监听状态,并没有接收请求。接收请求需要使用 accept() 函数。
(3)服务端:accept方法
当套接字处于监听状态时,可以通过 accept() 函数来接收客户端请求。accept() 返回一个新的套接字来和客户端通信,addr 保存了客户端的IP地址和端口号,而 sock 是服务器端的套接字,大家注意区分。后面和客户端通信时,要使用这个新生成的套接字,而不是原来服务器端的套接字。
最后需要说明的是:listen() 只是让套接字进入监听状态,并没有真正接收客户端请求,listen() 后面的代码会继续执行,直到遇到 accept()。accept() 会阻塞程序执行(后面代码不能被执行),直到有新的请求到来。
1
2
3
4
5
|
conn,addr=sock.accept()
print("conn:",conn) # conn: <socket.socket fd=560, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8899), raddr=('127.0.0.1', 64915)>
print("addr:",addr) # addr: ('127.0.0.1', 64915)
|
(4)客户端:connect方法
connect() 是客户端程序用来连接服务端的方法,:
1
2
3
4
|
import socket
ip_port=("127.0.0.1",8899)
sk=socket.socket()
sk.connect(ip_port)
|
注意:只有经过connect连接成功后的套接字对象才能调用发送和接受方法(send/recv),所以服务端的sock对象不能send or recv。
(5)收发数据方法:send和recv
| 方法 |
解析 |
| s.recv() |
接收 TCP 数据,数据以字符串形式返回,bufsize 指定要接收的最大数据量。flag 提供有关消息的其他信息,通常可以忽略。 |
| s.send() |
发送 TCP 数据,将 string 中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于 string 的字节大小。 |
12.4.3、聊天案例
服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import socket
sock = socket.socket()
sock.bind(("127.0.0.1",8899))
sock.listen(5)
while 1:
client_sock,addr = sock.accept()
print("客户端%s建立连接"%str(addr))
while 1:
try:
data = client_sock.recv(1024) # data字节串
except Exception:
client_sock.close()
print("客户端%s退出"%str(addr))
break
print(data.decode())
res = input(">>>")
client_sock.send(res.encode())
|
客户端:
1
2
3
4
5
6
7
8
9
10
11
|
import socket
ip_port=("127.0.0.1",8899)
sk=socket.socket()
sk.connect(ip_port)
while 1:
data = input(">>>")
sk.send(data.encode())
res = sk.recv(1024)
print("服务端:%s"%res.decode())
|
12.4.5、粘包案例
1
2
3
4
5
6
7
8
9
10
11
12
13
|
import socket
import time
s = socket.socket()
s.bind(("127.0.0.1",8888))
s.listen(5)
client,addr = s.accept()
time.sleep(10)
data = client.recv(1024)
print(data)
client.send(data)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
import socket
s = socket.socket()
s.connect(("127.0.0.1",8888))
data = input(">>>")
s.send(data.encode())
s.send(data.encode())
s.send(data.encode())
res = s.recv(1024)
print(res)
|
12.4.6、ssh案例
服务端程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import socket
import subprocess
import time
import struct
sock = socket.socket()
sock.bind(("127.0.0.1",8899))
sock.listen(5)
while 1:
client_sock,addr = sock.accept()
print("客户端%s建立连接"%str(addr))
while 1:
try:
cmd = client_sock.recv(1024) # data字节串
except Exception:
print("客户端%s退出"%str(addr))
client_sock.close()
break
print("执行命令:",cmd.decode("gbk"))
# 版本1:内存问题
# cmd_res_bytes = subprocess.getoutput(cmd.decode("gbk")).encode()
# client_sock.send(cmd_res_bytes)
# 版本2:粘包问题
# cmd_res_bytes = subprocess.getoutput(cmd.decode("gbk")).encode()
# cmd_res_bytes_len = bytes(str(len(cmd_res_bytes)),"utf8")
# client_sock.sendall(cmd_res_bytes_len)
# client_sock.sendall(cmd_res_bytes)
# 版本3:粘包解决方案
# result_str = subprocess.getoutput(cmd.decode("gbk"))
# result_bytes = bytes(result_str, encoding='utf8')
# res_len = struct.pack('i',len(result_bytes))
# client_sock.sendall(res_len)
# client_sock.sendall(result_bytes)
# cmd_res_bytes = subprocess.getoutput(cmd.decode("gbk")).encode()
# cmd_res_bytes_len = bytes(str(len(cmd_res_bytes)),"utf8")
# res_len = struct.pack('i', len(cmd_res_bytes))
# client_sock.sendall(res_len)
# client_sock.sendall(cmd_res_bytes)
|
客户端程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
import socket
import time
import struct
ip_port=("127.0.0.1",8899)
sk=socket.socket()
sk.connect(ip_port)
while 1:
data = input("输入执行命令>>>")
sk.send(data.encode())
# 版本1 内存问题
# res = sk.recv(1024)
# print("字节长度:",len(res))
# print("执行命令结果:%s"%(res.decode()))
# 版本2 粘包问题
# # time.sleep(5)
# res_len = sk.recv(1024)
# data = sk.recv(int(res_len.decode()))
# print(res_len)
# print(data.decode())
# 版本3:粘包解决方案
# length_msg = sk.recv(4)
# length = struct.unpack('i', length_msg)[0]
# msg = sk.recv(length).decode()
# print("执行命令结果:",msg)
|
测试命令:
12.4.7、案例之文件上传
服务端代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'mosson'
import socket
import struct
import json
import os
base_dir = os.path.dirname(os.path.abspath(__file__))
base_dir = os.path.join(base_dir, 'download')
class MYTCPServer:
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
allow_reuse_address = False
max_packet_size = 8192
coding='utf-8'
request_queue_size = 5
server_dir='file_upload'
def __init__(self, server_address, bind_and_activate=True):
"""Constructor. May be extended, do not override."""
self.server_address=server_address
self.socket = socket.socket(self.address_family,
self.socket_type)
if bind_and_activate:
try:
self.server_bind()
self.server_activate()
except:
self.server_close()
raise
def server_bind(self):
"""Called by constructor to bind the socket.
"""
if self.allow_reuse_address:
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.socket.bind(self.server_address)
self.server_address = self.socket.getsockname()
def server_activate(self):
"""Called by constructor to activate the server.
"""
self.socket.listen(self.request_queue_size)
def server_close(self):
"""Called to clean-up the server.
"""
self.socket.close()
def get_request(self):
"""Get the request and client address from the socket.
"""
return self.socket.accept()
def close_request(self, request):
"""Called to clean up an individual request."""
request.close()
def run(self):
print('server is running .......')
while True:
self.conn,self.client_addr=self.get_request()
print('from client ',self.client_addr)
while True:
try:
head_struct = self.conn.recv(4)
if not head_struct:break
head_len = struct.unpack('i', head_struct)[0]
head_json = self.conn.recv(head_len).decode(self.coding)
head_dic = json.loads(head_json)
print(head_dic)
cmd=head_dic['cmd']
if hasattr(self,cmd):
func=getattr(self,cmd)
func(head_dic)
except Exception:
break
def put(self,args):
"""
文件长传
:param args:
:return:
"""
file_path=os.path.normpath(os.path.join(
base_dir, args['filename']))
filesize=args['filesize']
recv_size=0
print('----->',file_path)
with open(file_path,'wb') as f:
while recv_size < filesize:
recv_data=self.conn.recv(2048)
f.write(recv_data)
recv_size += len(recv_data)
else:
print('recvsize:%s filesize:%s' %(recv_size,filesize))
def get(self, args):
""" 下载文件
1 检测服务端文件是不是存在
2 文件信息 打包发到客户端
3 发送文件
"""
filename = args['filename']
dic = {}
if os.path.isfile(base_dir + '/' + filename):
dic['filesize'] = os.path.getsize(base_dir + '/' + filename)
dic['isfile'] = True
else:
dic['isfile'] = False
str_dic = json.dumps(dic) # 字典转str
bdic = str_dic.encode(self.coding) # str转bytes
dic_len = len(bdic) # 计算bytes的长度
bytes_len = struct.pack('i', dic_len) #
self.conn.send(bytes_len) # 发送长度
self.conn.send(bdic) # 发送字典
# 文件存在发送真实文件
if dic['isfile']:
with open(base_dir + '/' + filename, 'rb') as f:
while dic['filesize'] > 2048:
content = f.read(2048)
self.conn.send(content)
dic['filesize'] -= len(content)
else:
content = f.read(2048)
self.conn.send(content)
dic['filesize'] -= len(content)
print('下载完成')
tcpserver1=MYTCPServer(('127.0.0.1',8083))
tcpserver1.run()
|
客户端代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
|
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'mosson'
import socket
import struct
import json
import os
import time
base_dir = os.path.dirname(os.path.abspath(__file__))
base_dir = os.path.join(base_dir, 'local_dir')
class MYTCPClient:
address_family = socket.AF_INET
socket_type = socket.SOCK_STREAM
allow_reuse_address = False
max_packet_size = 8192
coding = 'utf-8'
request_queue_size = 5
def __init__(self, server_address, connect=True):
self.server_address = server_address
self.socket = socket.socket(self.address_family,
self.socket_type)
if connect:
try:
self.client_connect()
except:
self.client_close()
raise
def client_connect(self):
self.socket.connect(self.server_address)
def client_close(self):
self.socket.close()
def run(self):
while True:
inp = input(">>: ").strip()
if not inp: continue
l = inp.split()
cmd = l[0]
if hasattr(self, cmd):
func = getattr(self, cmd)
func(l)
def put(self, args):
cmd = args[0]
filename = args[1]
filename = base_dir + '/' + filename
print(filename)
if not os.path.isfile(filename):
print('file:%s is not exists' % filename)
return
else:
filesize = os.path.getsize(filename)
head_dic = {'cmd': cmd, 'filename': os.path.basename(filename), 'filesize': filesize}
print(head_dic)
head_json = json.dumps(head_dic)
head_json_bytes = bytes(head_json, encoding=self.coding)
head_struct = struct.pack('i', len(head_json_bytes))
self.socket.send(head_struct)
self.socket.send(head_json_bytes)
send_size = 0
t1 = time.time()
# with open(filename,'rb') as f:
# for line in f:
# self.socket.send(line)
# send_size+=len(line)
# else:
# print('upload successful')
# t2 = time.time()
with open(filename, 'rb') as f:
while head_dic['filesize'] > 2048:
content = f.read(2048)
self.socket.send(content)
head_dic['filesize'] -= len(content)
else:
content = f.read(2048)
self.socket.send(content)
head_dic['filesize'] -= len(content)
t2 = time.time()
print(t2 - t1)
def get(self, args):
cmd = args[0]
filename = args[1]
dic = {'cmd': cmd, 'filename': filename}
"""发送dic的步骤
字典转str
str转bytes
计算bytes的长度
发送长度
发送字典
"""
str_dic = json.dumps(dic) # 字典转str
bdic = str_dic.encode(self.coding) # str转bytes
dic_len = len(bdic) # 计算bytes的长度
bytes_len = struct.pack('i', dic_len) #
self.socket.send(bytes_len) # 发送长度
self.socket.send(bdic) # 发送字典
# 接受 准备下载的文件信息
dic_len = self.socket.recv(4)
dic_len = struct.unpack('i', dic_len)[0]
dic = self.socket.recv(dic_len).decode(self.coding)
dic = json.loads(dic)
# 文件存在准备下载
if dic['isfile']:
t1 = time.time()
with open(base_dir + '/' + filename, 'wb') as f:
while dic['filesize'] > 2048:
content = self.socket.recv(2048)
f.write(content)
dic['filesize'] -= len(content)
else:
while dic['filesize']:
content = self.socket.recv(2048)
f.write(content)
dic['filesize'] -= len(content)
t2 = time.time()
print(t2 - t1)
else:
print('文件不存在!')
client = MYTCPClient(('127.0.0.1', 8083))
client.run()
|
作业:开发一个FTP程序
1
2
3
4
|
# 要求
# 1、允许上传和下载文件,保证文件一致性
# 2、文件传输过程中显示进度条
# 3、附加功能:支持文件的断点续传
|
十三、并发编程