Go语言开篇介绍
Go语言 是Google公司 在2007开发一种静态强类型、编译型语言,并在 2009 年正式对外发布。
Go语言以其近C的执行性能和近解析型语言的开发效率,以及近乎于完美的编译速度,已经风靡全球。很多人将Go语言称为21世纪的C语言,因为Go不仅拥有C的简洁和性能,而且针对多处理器系统应用程序的编程进行了优化,很好的提供了21世纪互联网环境下服务端开发的各种实用特性。

Go语言的诞生
事件起源于2007年9月,当时 C++委员会正在 Google 对 C++ 语言新增加的35个新的特性进行一场分享演讲。
Google 的技术大神们也在认真听讲座,其中就有Go语言的三个创作者,分别是: Robert Griesemer(罗伯特.格利茨默),Rob Pike(罗伯.派克),Ken Thompson(肯.汤普森)。

-
Rob Pike(罗伯.派克)
罗布·派克是Unix的先驱,是贝尔实验室最早和Ken Thompson以及 Dennis M. Ritche(C语言之父) 开发Unix的猛人,UTF-8的设计人。让人佩服不已的是,罗伯伯还是1980年奥运会射箭的银牌得主。
-
Ken Thompson(肯.汤普森)
Ken Thompson,C语言前身B语言的作者,与Dennis Ritchie是Unix的原创者。1983年图灵奖得主以及1998年美国国家技术奖(National Medal of Technology)得主。
-
Robert Griesemer(罗伯特.格利茨默)
参与制作了Java的HotSpot编译器以及Chrome浏览器的javascript的搜索引擎V8。
随着会议的中场休息,大家开始了对这些 C++ 语言新特性是否带来更多的价值进行吐槽。Rob Pike他们认为:简化语言的成就远大于添加功能。于是,一门新的语言,Go,在这个思路下应运而生。
2007 年 9 月 25 号,Rob Pike在回家的路上得到关于新语言名字的灵感,于是给另外两人发了邮件:
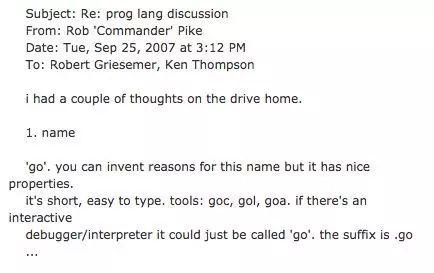
邮件正文大意为:
在开车回家的路上我得到了些灵感。
1.给这门编程语言取名为“go”,它很简短,易书写。工具类可以命名为:goc、 gol、goa。
交互式的调试工具也可以直接命名为“go”。语言文件后缀名为 .go 等等
这就是 Go 语言名字的来源,自此之后 Robert、Rob 和 Ken 三个人开始在 Google 内部进行了研发,一直到了 2009 年,Go 正式开源了,Go 项目团队将 2009 年 11 月 10 日,即该语言正式对外开源的日字作为其官方生日。源代码最初托管在 http://code.google.com 上,之后几年才逐步的迁移到 GitHub 上。

Go语言的版本
Go 1.0 — 2012 年 3 月:Go 的第一个版本,带着一份兼容性说明文档来保证与未来发布版本的兼容性,进而不会破坏已有的程序。
Go 1.1 — 2013 年 5 月:这个 Go 版本专注于优化语言(编译器,gc,map,go 调度器)和提升它的性能。
Go 1.3 — 2014 年 6 月:这个版本对栈管理做了重要的改进。栈可以申请[连续的内存片段,提高了分配的效率
Go 1.4 — 2014 年 12 月:此版本带来了官方对 Android 的支持,让我们可以只用 Go 代码就能写出简单的 Android 程序。
Go 1.7 — 2016 年 8 月: 这个版本发布了context 包,为用户提供了处理超时和任务取消的方法。
Go 1.11 — 2018 年 8 月: Go 1.11 带来了一个重要的新功能:Go modules。
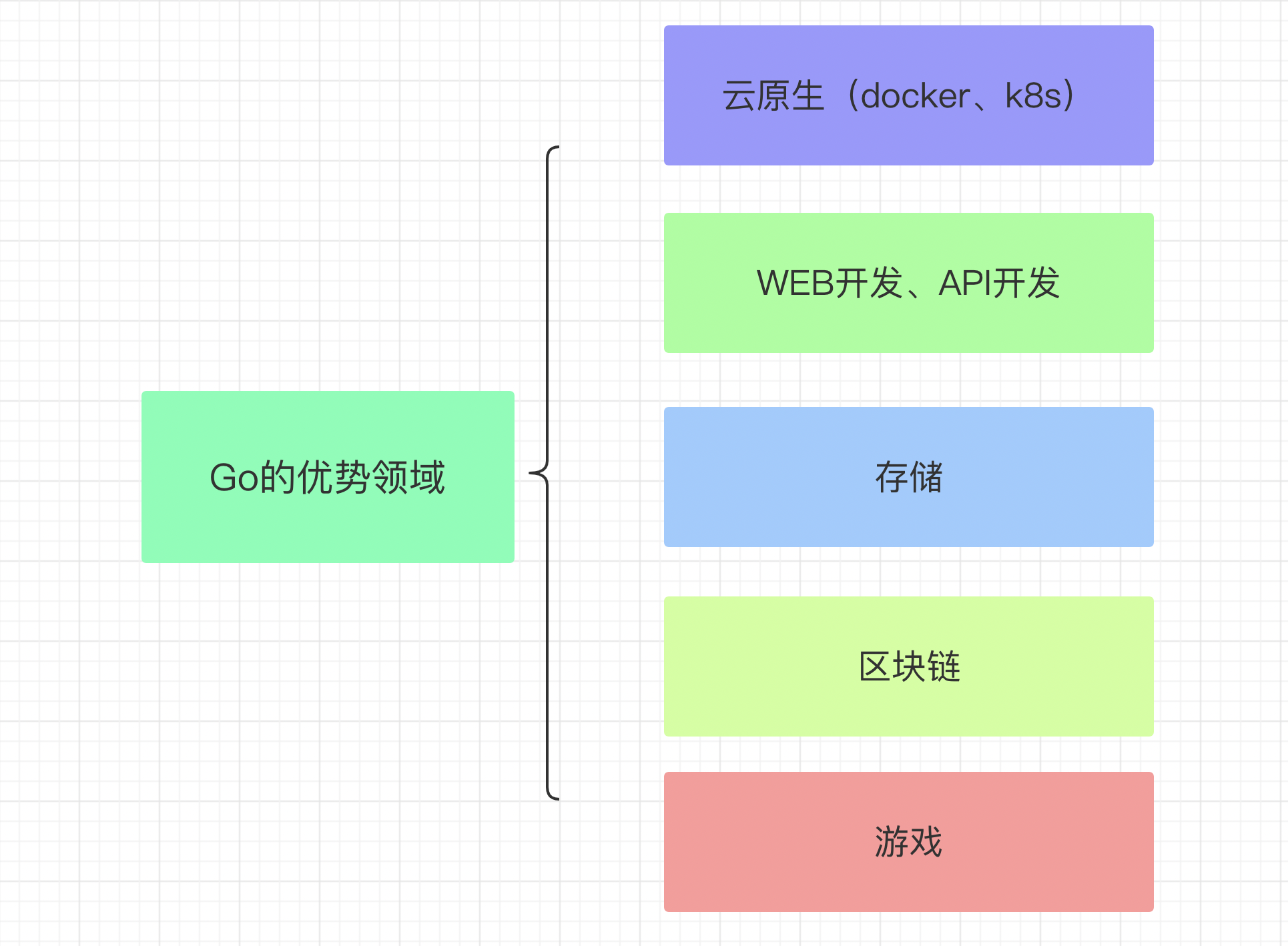
Go语言的优势
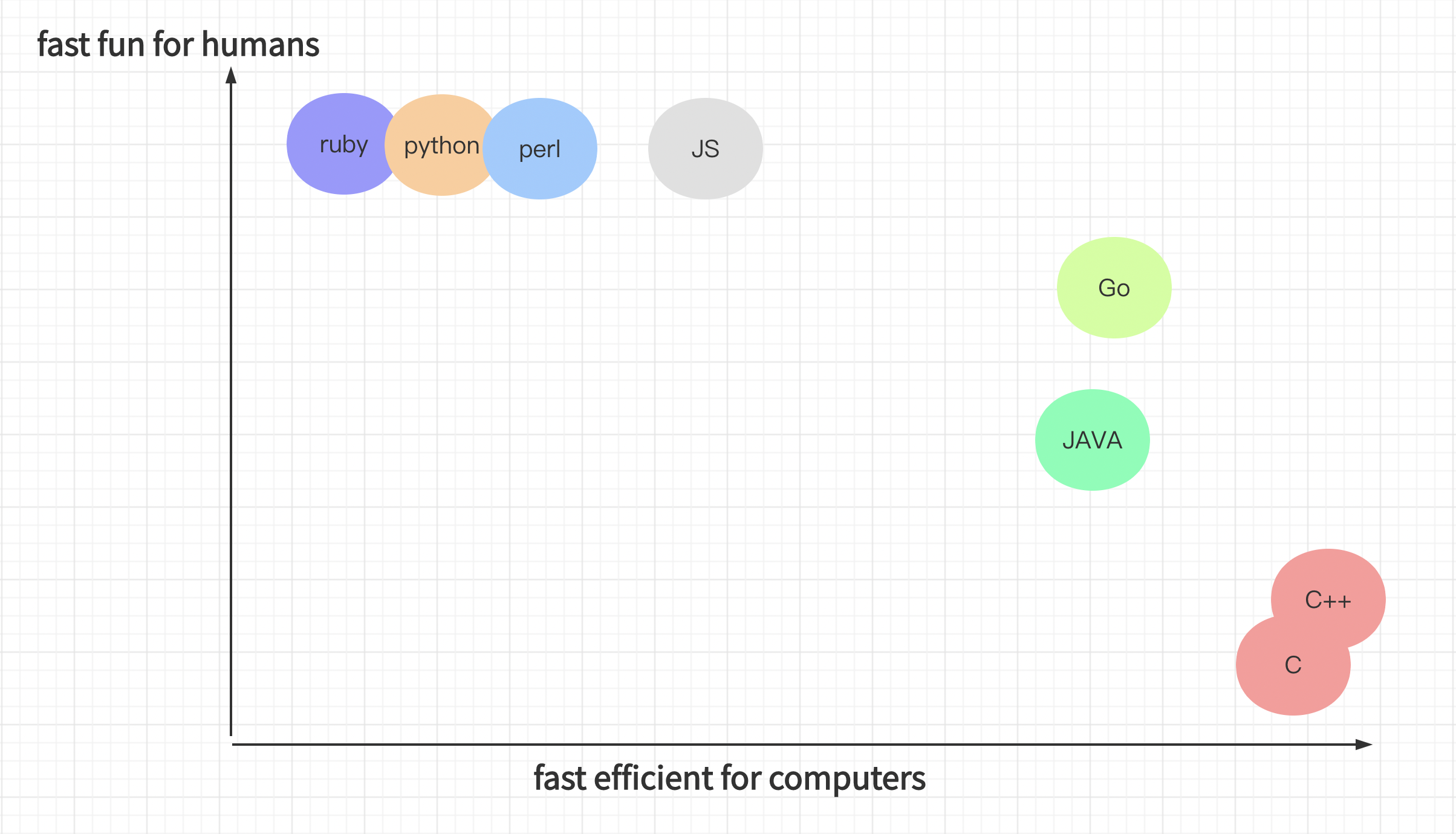
Go语言的应用领域
使用Go的大型互联网公司
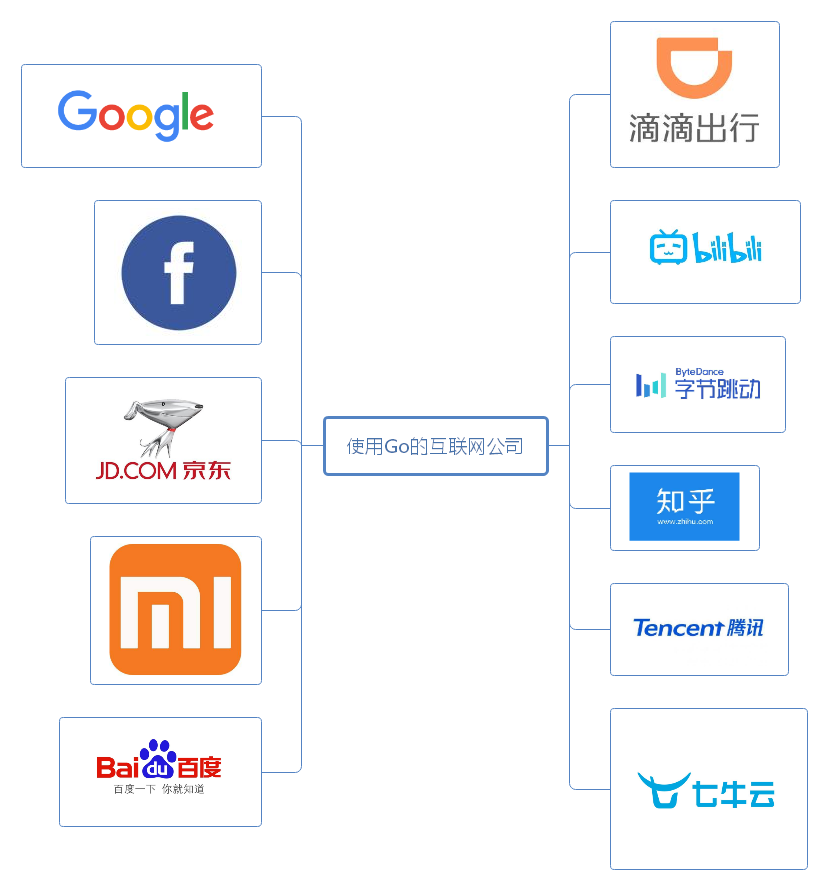
Go语言的强项在于它适合用来开发网络并发方面的服务,比如消息推送、监控、容器等,所以在高并发的项目上大多数公司会优先选择 Golang 作为开发语言。另外一个应用就是对一些python,php或者java项目进行重构。
介绍完Go语言,那么接下来我们就可以正式进入Golang的学习了。
一、计算机基础
计算机(computer)俗称电脑,是现代一种用于高速计算的电子计算机器,可以进行数值计算,又可以进行逻辑计算,还具有存储记忆功能。是能够按照程序运行,自动、高速处理海量数据的现代化智能电子设备。
计算机是20世纪最先进的科学技术发明之一,对人类的生产活动和社会活动产生了极其重要的影响。它的应用领域从最初的军事科研应用扩展到社会的各个领域,已形成了规模巨大的计算机产业,带动了全球范围的技术进步,由此引发了深刻的社会变革。

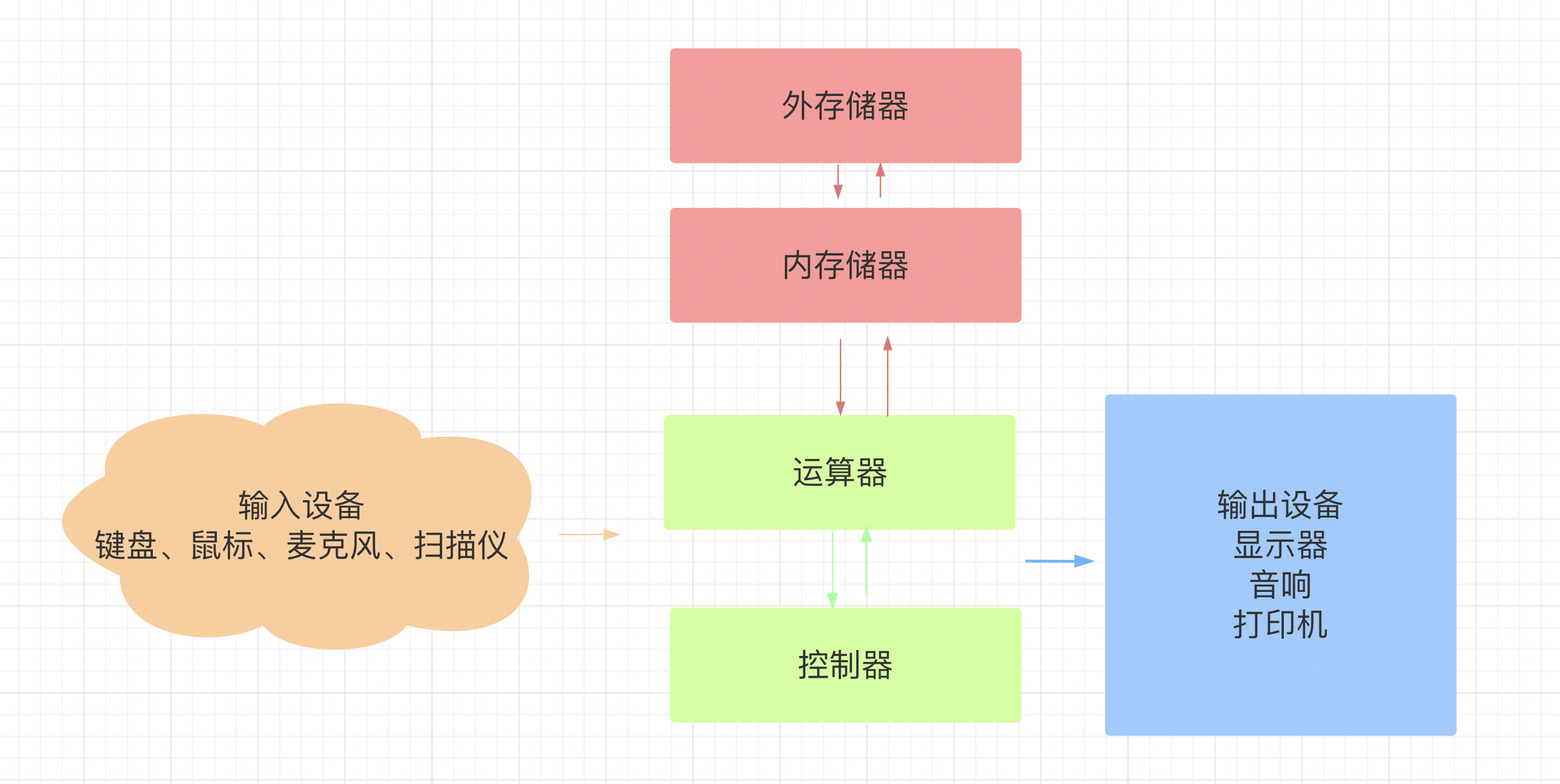
1.1、计算机硬件组成
其中,CPU包括运算器和控制器,相当于计算机的大脑,是计算机的运算核心和控制核心。

(1) 运算器是用来进行数据运算加工的。
(2) 控制器是是计算机的指挥中心,负责决定执行程序的顺序,给出执行指令时机器各部件所需要的操作控制命令,用于协调和控制计算机的运行。
储存器可分为内储存器和外储存器两部分:内存属于内储存器,内存是CPU与硬盘之间的桥梁,只负责在CPU与硬盘之间做数据预存加速的功能。断电后即会被清除。输入设备的数据是从设备接口进去到端口缓冲器的,再经主板的输入输出总线(I/O总线)直接到CPU的,不经过内存。

外储存器是指除计算机内存及CPU缓存以外的储存器,此类储存器一般断电后仍然能保存数据。常见的外存储器有硬盘、软盘、光盘、U盘等。

输入设备就是键盘、鼠标、麦克风、扫描仪等等,向电脑输入信息。输入设备则相反,电脑向外部输出信息,如显示器、打印、音像、写入外存等。
1.2、冯-诺伊曼计算机

提到计算机,就不得不提及在计算机的发展史上做出杰出贡献的著名应用数学家冯诺依曼(Von Neumann,是他带领专家提出了一个全新的存储程序的通用电子计算机方案。这个方案规定了新机器由5个部分组成:运算器、逻辑控制装置、存储器、输入和输出。并描述了这5个部分的职能和相互关系。
早期的ENIAC有一个致命的缺点就是程序与计算两分离。在埃历阿克ENIAC尚未投入运行前,冯·诺依曼就已开始着手起草一份新的设计报告,要对这台电子计算机进行脱胎换骨的改造。他把新机器的方案命名为“离散变量自动电子计算机”,英文缩写译音是“埃德瓦克”(EDVAC)。1945年6月,冯·诺依曼与戈德斯坦、勃克斯等人,为埃德瓦克方案联名发表了一篇长达101页纸洋洋万言的报告,即计算机史上著名的“101页报告”。这份报告奠定了现代电脑体系结构坚实的根基,直到今天,仍然被认为是现代电脑科学发展里程碑式的文献。报告明确规定出计算机的五大部件**(输入系统、输出系统、存储器、运算器、控制器),并用二进制替代十进制运算**,大大方便了机器的电路设计。埃德瓦克方案的革命意义在于**“存储程序”**──程序也被当作数据存进了机器内部,以便电脑能自动依次执行指令,再也不必去接通什么线路。
人们后来把根据这一方案思想设计的机器统称为“诺依曼机”。自冯·诺依曼设计的埃德瓦克始,直到今天我们用“奔腾”芯片制作的多媒体计算机为止,电脑一代又一代的“传人”,大大小小千千万万台计算机,都没能够跳出诺依曼机的掌心。在这个意义上,冯·诺依曼是当之无愧的“计算机之父”。而
总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,它是由导线组成的传输线束, 按照计算机所传输的信息种类,计算机的总线可以划分为数据总线、地址总线和控制总线,分别用来传输数据、数据地址和控制信号。总线是一种内部结构,它是cpu、内存、输入、输出设备传递信息的公用通道,主机的各个部件通过总线相连接,外部设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统。
二、编程语言介绍
2.1、什么是编程语言
编程语言是用来控制计算机的一系列指令(Instruction),它有固定的格式和词汇(不同编程语言的格式和词汇不一样)。就像我们中国人之间沟通需要汉语,英国人沟通需要英语一样,人与计算机之间进行沟通需要一门语言作为介质,即编程语言。
编程语言的发展经历了机器语言(指令系统)=>汇编语言=>高级语言(C、java、Go等)。
010010101001-》ADD
- 计算机在设计中规定了一组指令(二级制代码),这组指令的集和就是所谓的机器指令系统,用机器指令形式编写的程序称为机器语言。
- 但由于机器语言的千上万条指令难以记忆,并且维护性和移植性都很差,所以在机器语言的基础上,人们提出了采用字符和十进制数代替二进制代码,于是产生了将机器语言符号化的汇编语言。
- 虽然汇编语言相较于机器语言简单了很多,但是汇编语言是机器指令的符号化,与机器指令存在着直接的对应关系,无论是学习还是开发,难度依然很大。所以更加接近人类语言,也更容易理解和修改的高级语言就应运而生了,高级语言的一条语法往往可以代替几条、几十条甚至几百条汇编语言的指令。因此,高级语言易学易用,通用性强,应用广泛。
2.2、编译型语言与解释性语言
计算机是不能理解高级语言的,更不能直接执行高级语言,它只能直接理解机器语言,所以使用任何高级语言编写的程序若想被计算机运行,都必须将其转换成计算机语言,也就是机器码。而这种转换的方式分为编译和解释两种。由此高级语言也分为编译型语言和解释型语言。
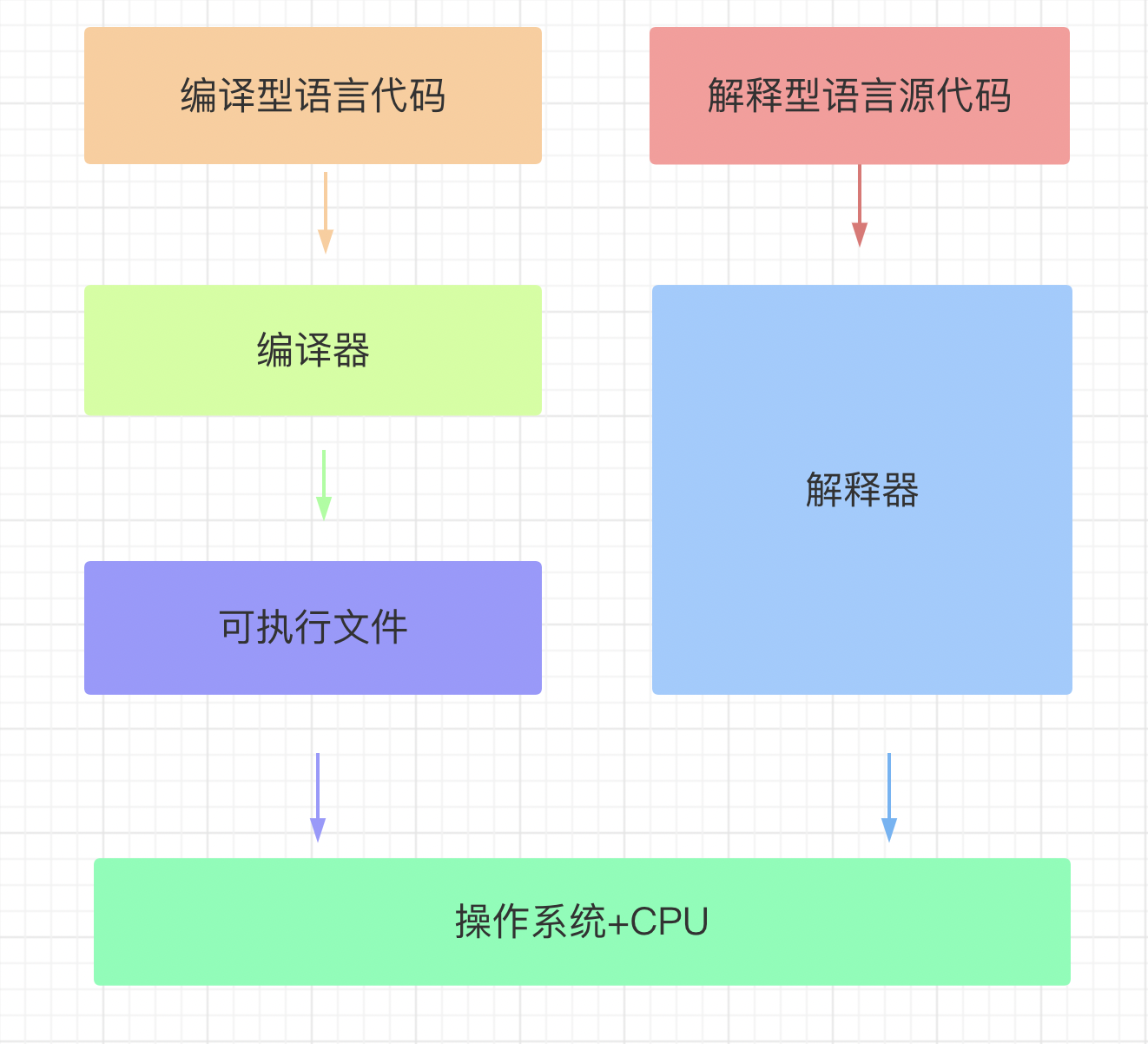
使用专门的编译器,针对特定的平台,将高级语言源代码一次性的编译成可被该平台硬件执行的机器码,并包装成该平台所能识别的可执行性程序的格式。
编译型语言写的程序执行之前,需要一个专门的编译过程,把源代码编译成机器语言的文件,如exe格式的文件,以后要再运行时,直接使用编译结果即可,如直接运行exe文件。因为只需编译一次,以后运行时不需要编译,所以编译型语言执行效率高。
1、一次性的编译成平台相关的机器语言文件,运行时脱离开发环境,运行效率高;
2、与特定平台相关,一般无法移植到其他平台;
使用专门的解释器对源程序逐行解释成特定平台的机器码并立即执行。是代码在执行时才被解释器一行行动态翻译和执行,而不是在执行之前就完成翻译。
1.解释型语言每次运行都需要将源代码解释称机器码并执行,执行效率低;
2.只要平台提供相应的解释器,就可以运行源代码,所以可以方便源程序移植;
三、Go环境安装
3.1、Go编译器的下载
1
2
|
-- 官网:https://golang.google.cn/
-- go中文网:https://studygolang.com/dl
|

3.2、安装 for Mac
3.2.1、 mac系统下安装SDK
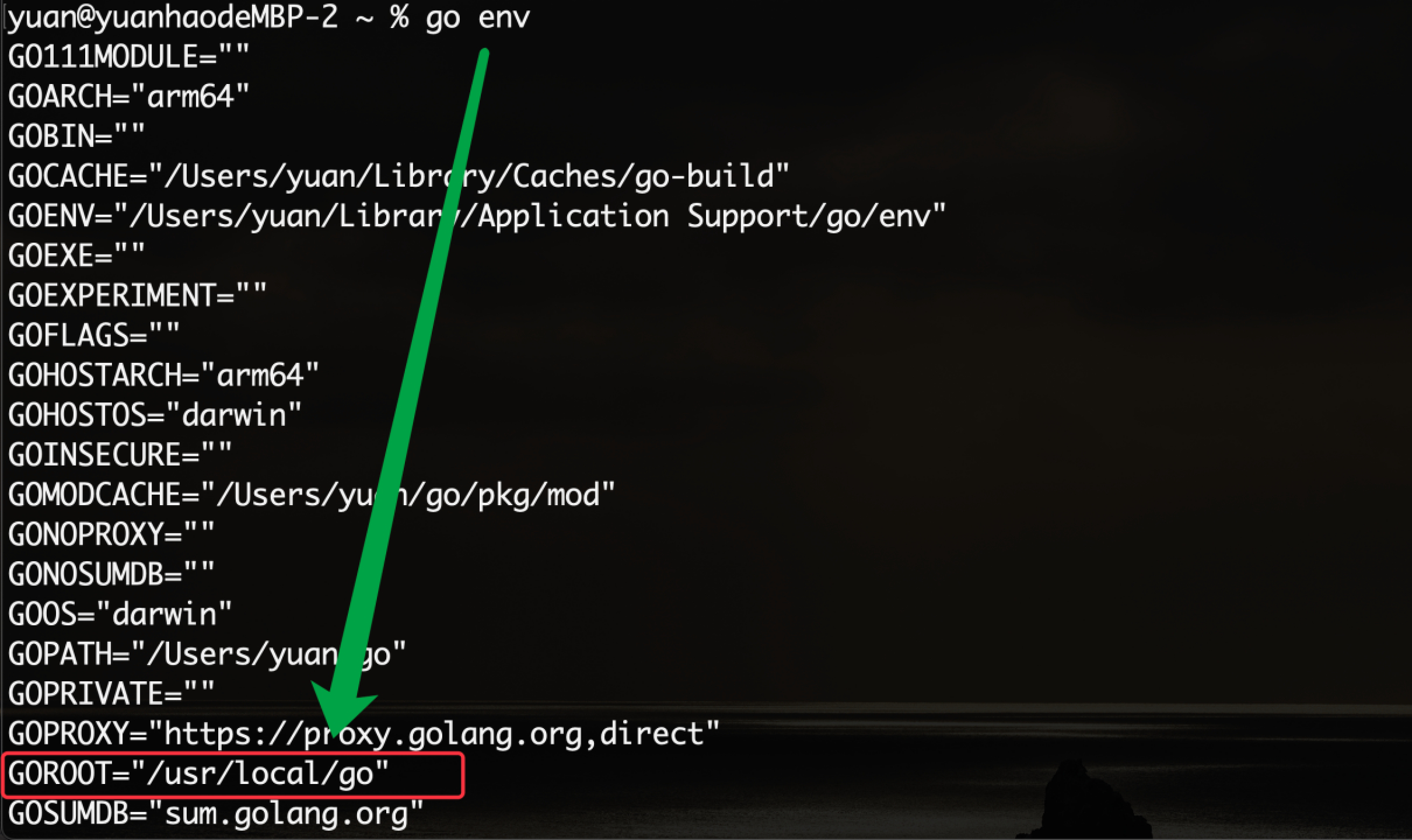
安装完成以后可以使用终端软件(例如iTerm)中输入go version查看Go编译器的版本信息

mac系统下会默认安装到GOROOT="/usr/local/go"中,通过go env可以查看
3.2.2、 mac系统下配置GOPATH
开发包安装完成后,我们还需要配置一下GOPATH 环境变量,之后才可以使用Go语言进行开发。GOPATH是开发人员编写Go程序的工作空间路径,也就是存放Go代码的地方
在终端中运行 vi ~/.bash_profile 添加下面这行代码
1
|
export GOPATH=$HOME/goWork
|
保存然后退出你的编辑器。然后在终端中运行下面命令
提示:$HOME 是每个电脑下的用户主目录,每个电脑可能不同,可以在终端运行 echo $HOME 获取
然后保存并退出编辑器,运行 source ~/.bash_profile 命令即可。
3.3 安装 for Window
3.3.1、window系统下安装SDK
双击我们下载好的Go语言开发包即可启动安装程序,如下图所示,这是Go语言的用户许可协议,无需管它,直接勾选“I accept …”然后点击“Next”即可。
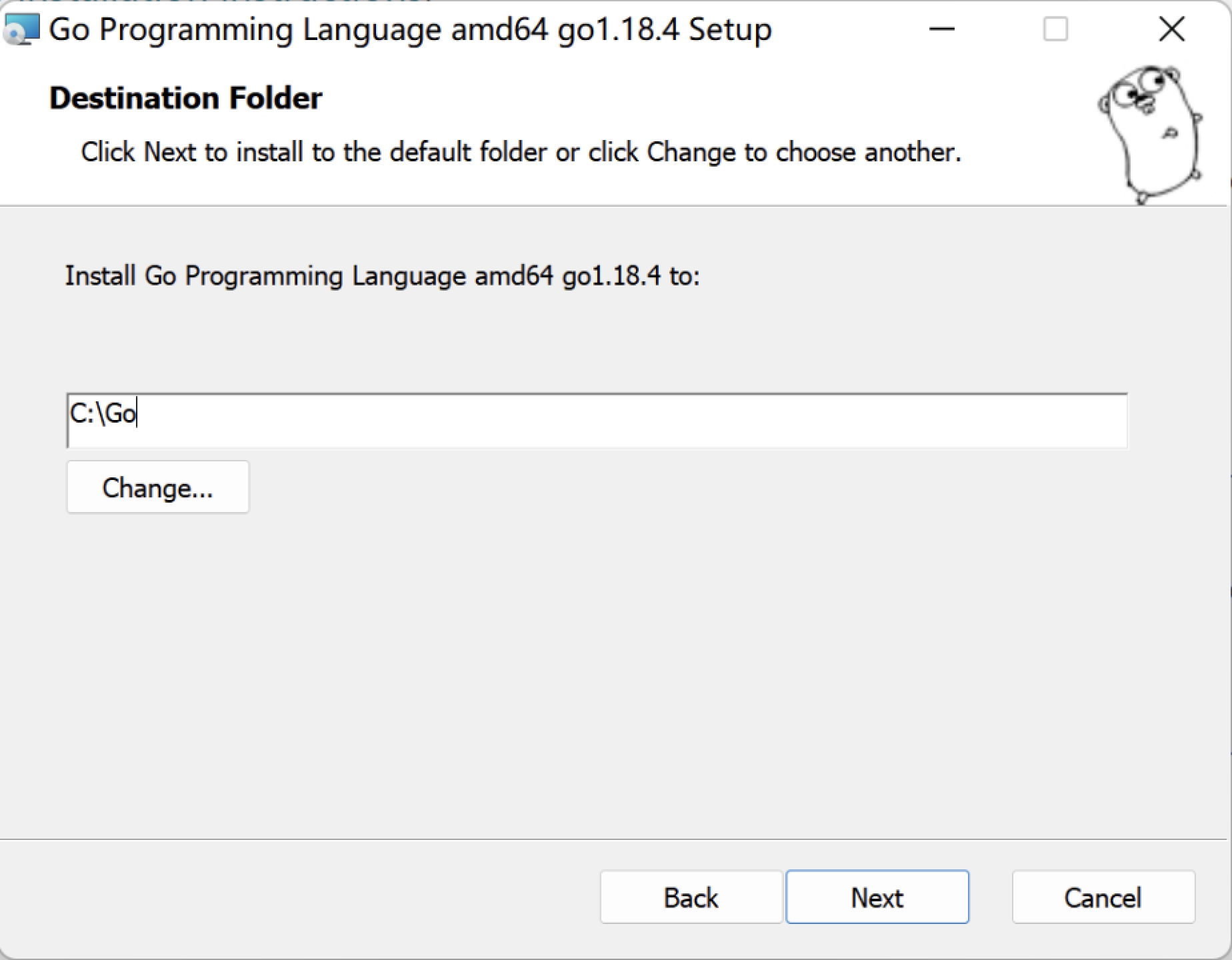
在 Windows 系统下Go语言开发包会默认安装到 C 盘的 Go 目录下,推荐在这个目录下安装,使用起来较为方便。当然,你也可以选择其他的安装目录,确认无误后点击“Next”,如下图所示:
Go语言开发包的安装没有其他需要设置的选项,点击“Install”即可开始安装,如下图所示:
等待程序完成安装,然后点击“Finish”退出安装程序。
安装完成后,在我们所设置的安装目录下将生成一些目录和文件,如下图所示:
在默认情况下,win系统下Go 将会被安装在目录 c:\go 下,但如果你在安装过程中修改安装目录,则需要手动修改所有的环境变量的值。
通过go env命令可以查看环境变量的所有情况。值得一提的是,GOROOT 表示 Go 开发包的安装目录。
国内Go语言库镜像:https://github.com/goproxy/goproxy.cn 在终端输入:go env -w GOPROXY=https://goproxy.cn,direct对代理进行修改。
GOPROXY https://proxy.golang.org,direct
阿里云: export GOPROXY=https://mirrors.aliyun.com/goproxy/
七牛云: export GOPROXY= https://goproxy.cn
go env -w “GO111MODULE=off” // 关闭go mod
3.3.2、window系统下配置GOPATH
GOPATH 是 Go语言中使用的一个环境变量,它使用绝对路径提供项目的工作目录(workspace)。
GOPATH下创建src文件夹,即存放Go项目代码的位置。
开发包安装完成后,我们还需要配置一下GOPATH 环境变量,之后才可以使用Go语言进行开发。GOPATH是开发人员编写Go程序的工作空间路径,也就是存放Go代码的地方。
在桌面或者资源管理器右键“此电脑”(或者“我的电脑”)→“属性”→“高级系统设置”→“环境变量”,如下图所示。
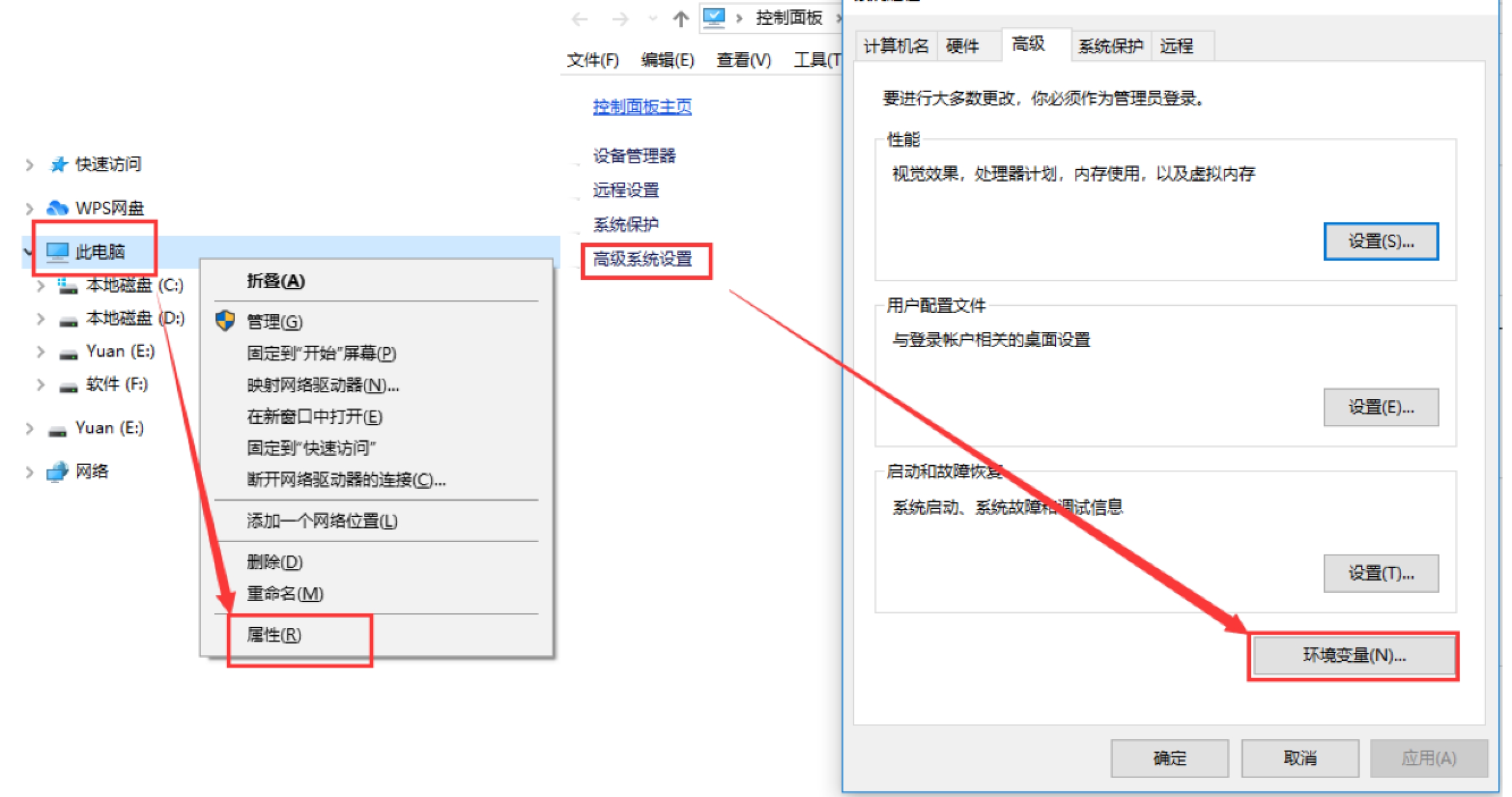
在弹出的菜单里找到 GOPATH 对应的选项点击编辑之后就可以修改了,没有的话可以选择新建,并将变量名填写为 GOPATH,变量值设置为任意目录均可(尽量选择空目录),例如 F:\GoWork。
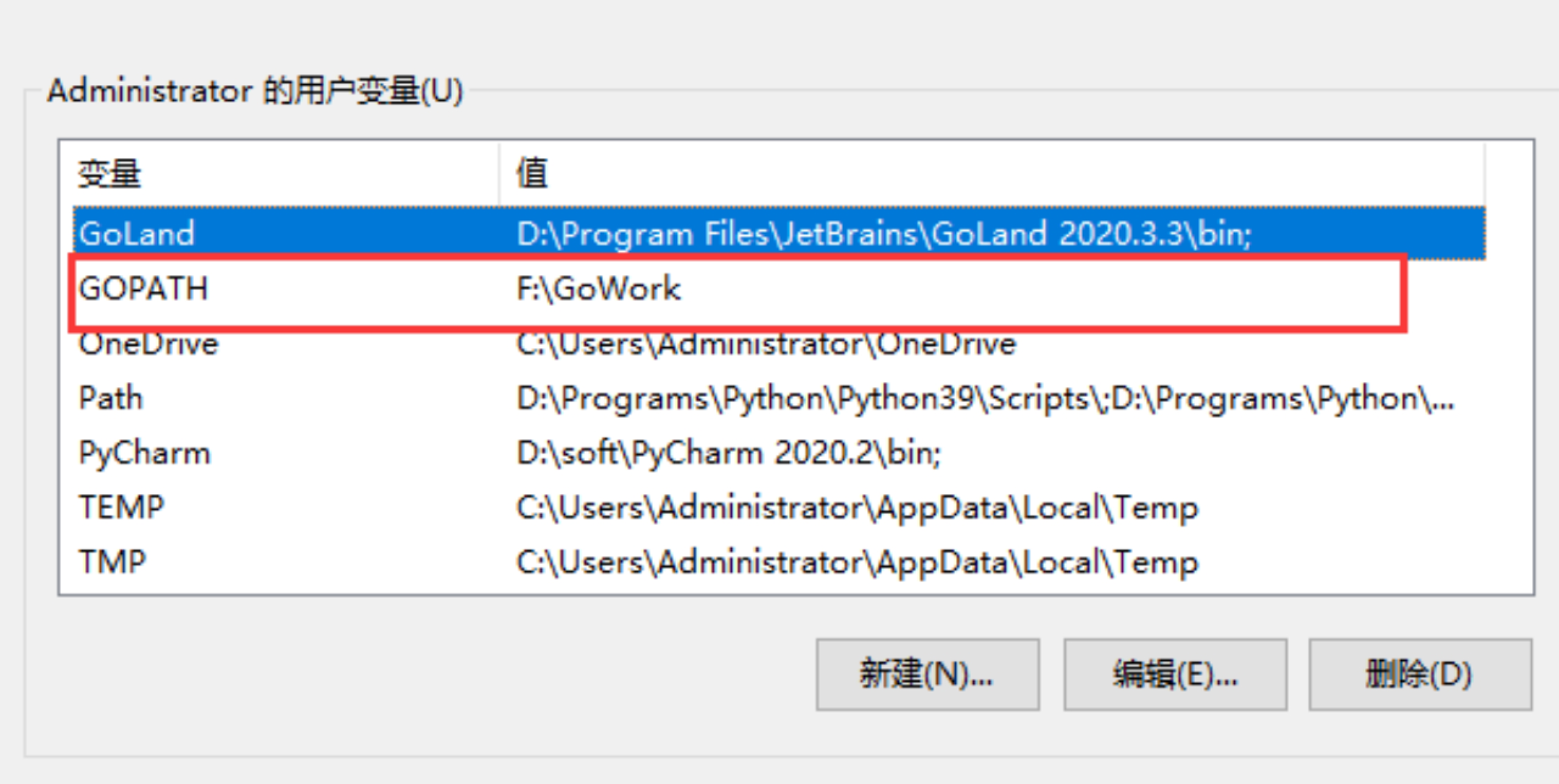
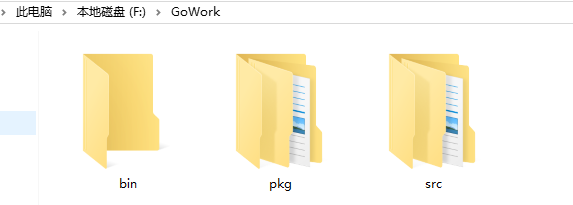
GOPATH对应创建的文件夹中里面,手动创建如下3个目录
1
2
3
|
src 存储go的源代码(需要我们自己手动创建)
pkg 存储编译后生成的包文件 (自动生成)
bin 存储生成的可执行文件(自动生成)
|
3.4、第一个Go程序
1
2
3
4
5
6
7
8
|
package main
import "fmt"
func main() {
fmt.Println("Hello Yuan!")
}
|
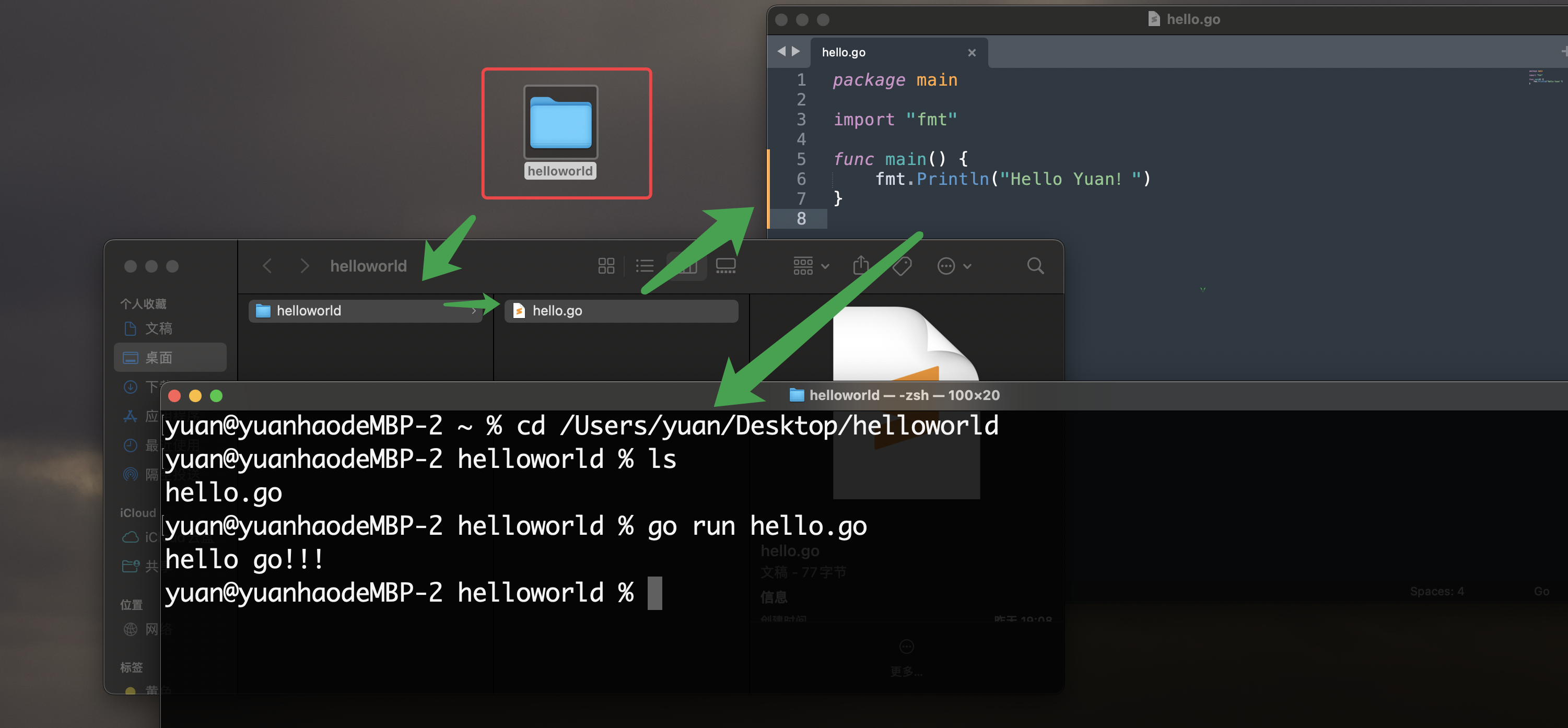
- 程序没有涉及到自定义包调用时可以放在电脑任何位置
- 为了以后方便管理,我们暂时统一放在gopath的src下
- 后面会学习go mod更好进行包管理
3.4.1、程序语法解析
(1) main包和main函数
Go语言以“包”作为管理单位,每个 Go 源文件必须先声明它所属的包,所以我们会看到每个 Go 源文件的开头都是一个 package 声明。Go语言的包与文件夹是一一对应的。一个Go语言程序必须有且仅有一个 main 包。main 包是Go语言程序的入口包,如果一个程序没有 main 包,那么编译时将会出错,无法生成可执行文件。
(2) import
在包声明之后,是 import 语句,用于导入程序中所依赖的包,导入的包名使用双引号""包围,格式如下:
其中 import 是导入包的关键字,name 为所导入包的名字。
导入的包中不能含有代码中没有使用到的包,否则Go编译器会报编译错误
也可以使用一个 import 关键字导入多个包,此时需要用括号( )将包的名字包围起来,并且每个包名占用一行
1
2
3
4
|
import(
"p1"
"p2"
)
|
3.4.2、程序编译执行
我们上面给大家介绍过,Go语言是像C语言一样的编译型的静态语言,所以在运行Go语言程序之前,先要将其编译成二进制的可执行文件。
可以通过Go语言提供的go build或者go run命令对Go语言程序进行编译:
(1) go build命令可以将Go语言程序代码编译成二进制的可执行文件,但是需要我们手动运行该二进制文件;
1、如果是普通包,当你执行go build之后,它不会产生任何文件。【非main包】
2、如果是main包,当你执行go build之后,它就会在当前目录下生成一个可执行文件,比如win系统的exe文件
3、你也可以指定编译输出的文件名。我们可以指定go build -o 可执行文件.exe
(2)除了使用go build命令外,Go语言还为我们提供了go run命令,go run命令将编译和执行指令合二为一,会在编译之后立即执行Go语言程序,但是不会生成可执行文件。
1
|
go run go文件名称 // go文件名称不能为空
|
3.5、IDE的安装与使用
3.5.1、安装Goland
GoLand是Jetbrains公司推出专为Go开发人员构建的跨平台IDE,可以运行在Windows,Linux,macOS系统之上,
下载地址:https://www.jetbrains.com/go/download/#section=windows
下载完成之后便可以进行安装了
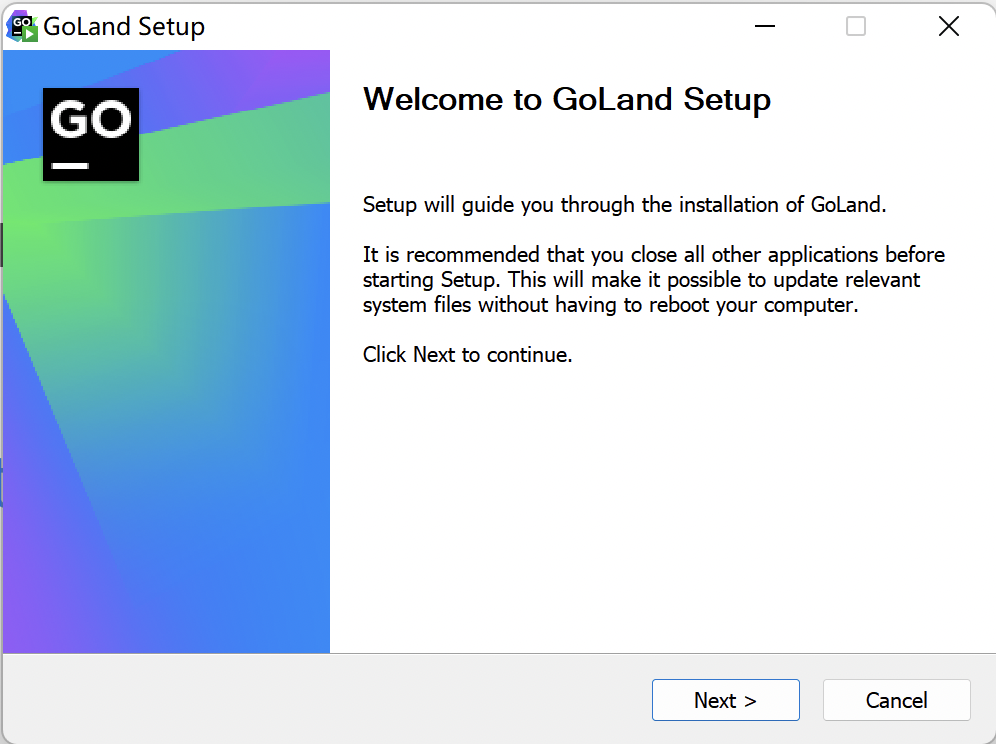
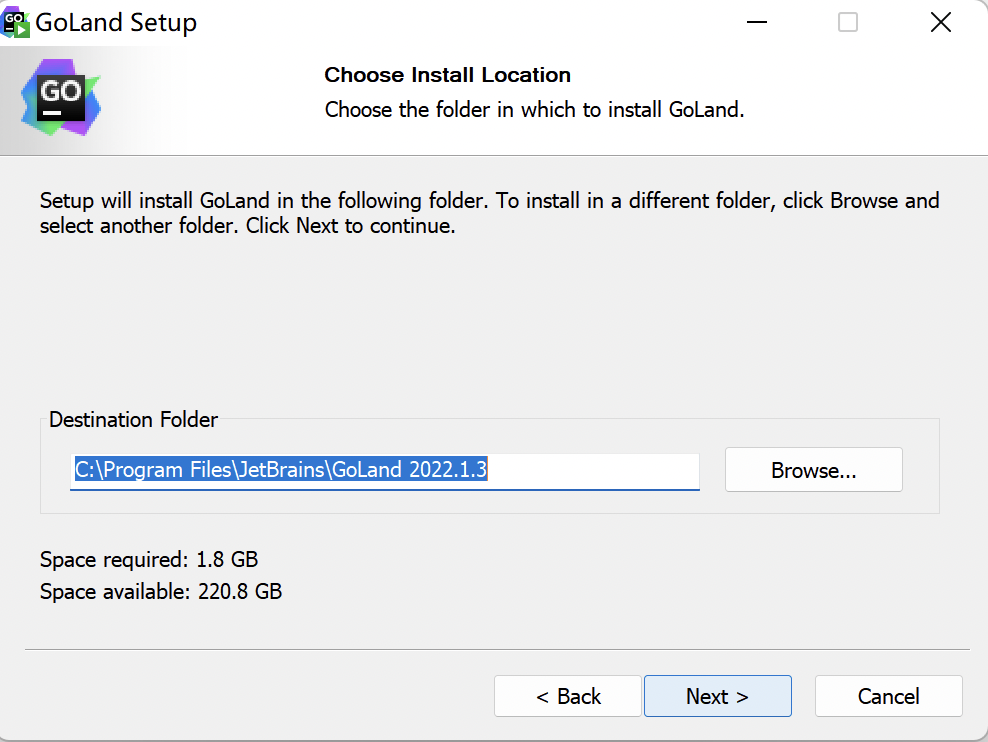
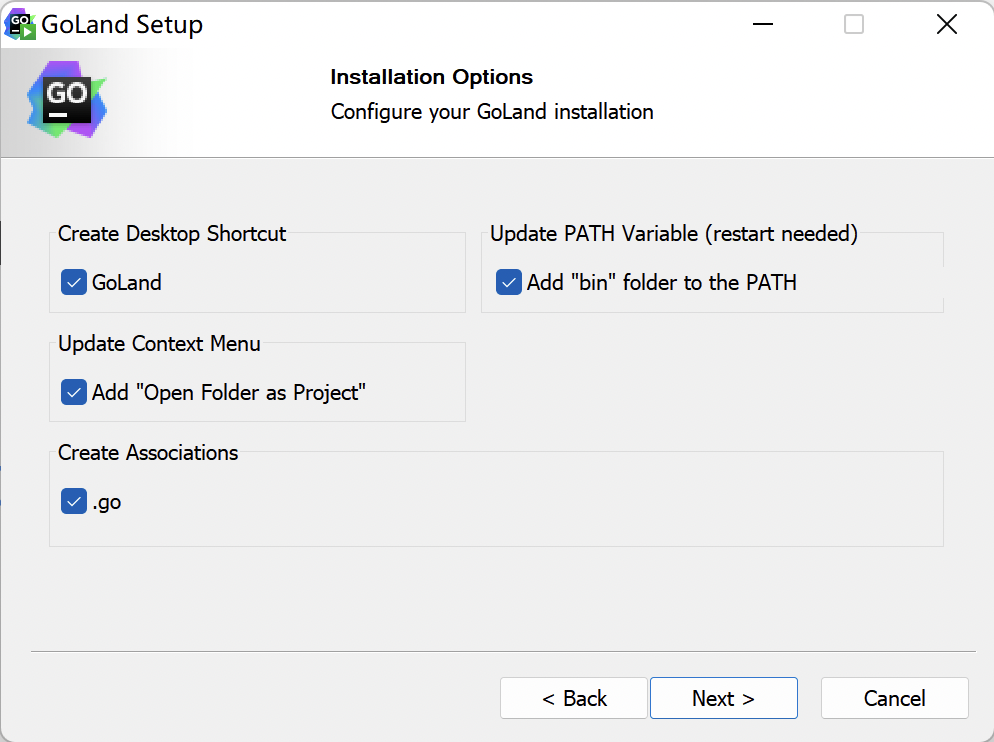
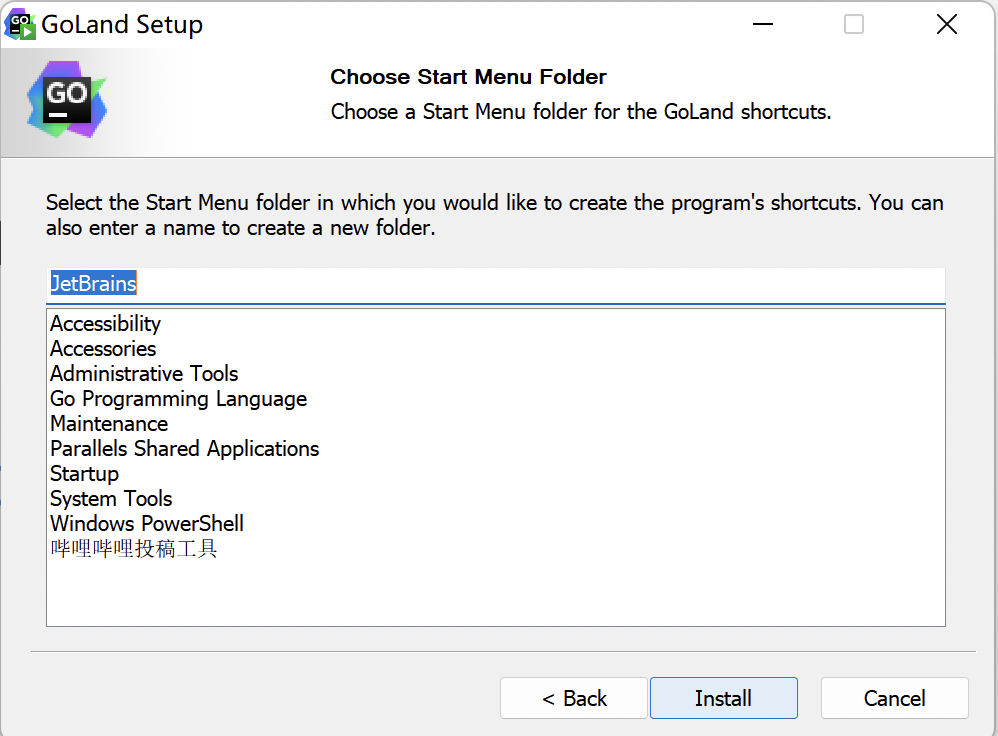
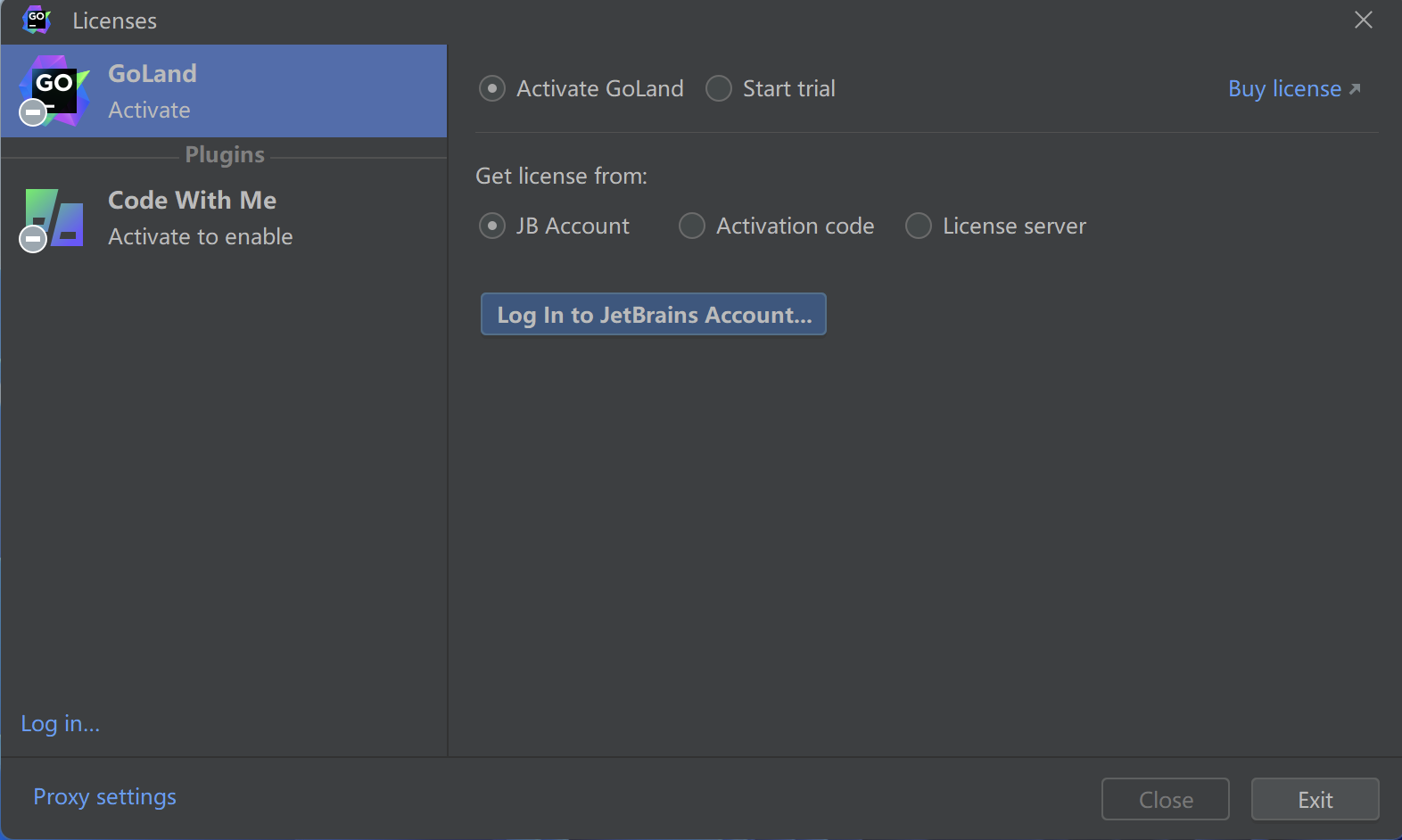
因为GoLand是收费的IDE,同时也提供了30天免费试用的方式。如果经济能力允许的话,可以从指定渠道购买正版GoLand.
GoLand提供了Jetbrains Account,Activition Code和License Server三种激活方式,使用前必须激活或者选择免费试用
当激活或者选择免费试用之后便会启动GoLand。
免费试用需要点击log in,进行账户注册(在PC端完成),然后登陆,即可试用30天
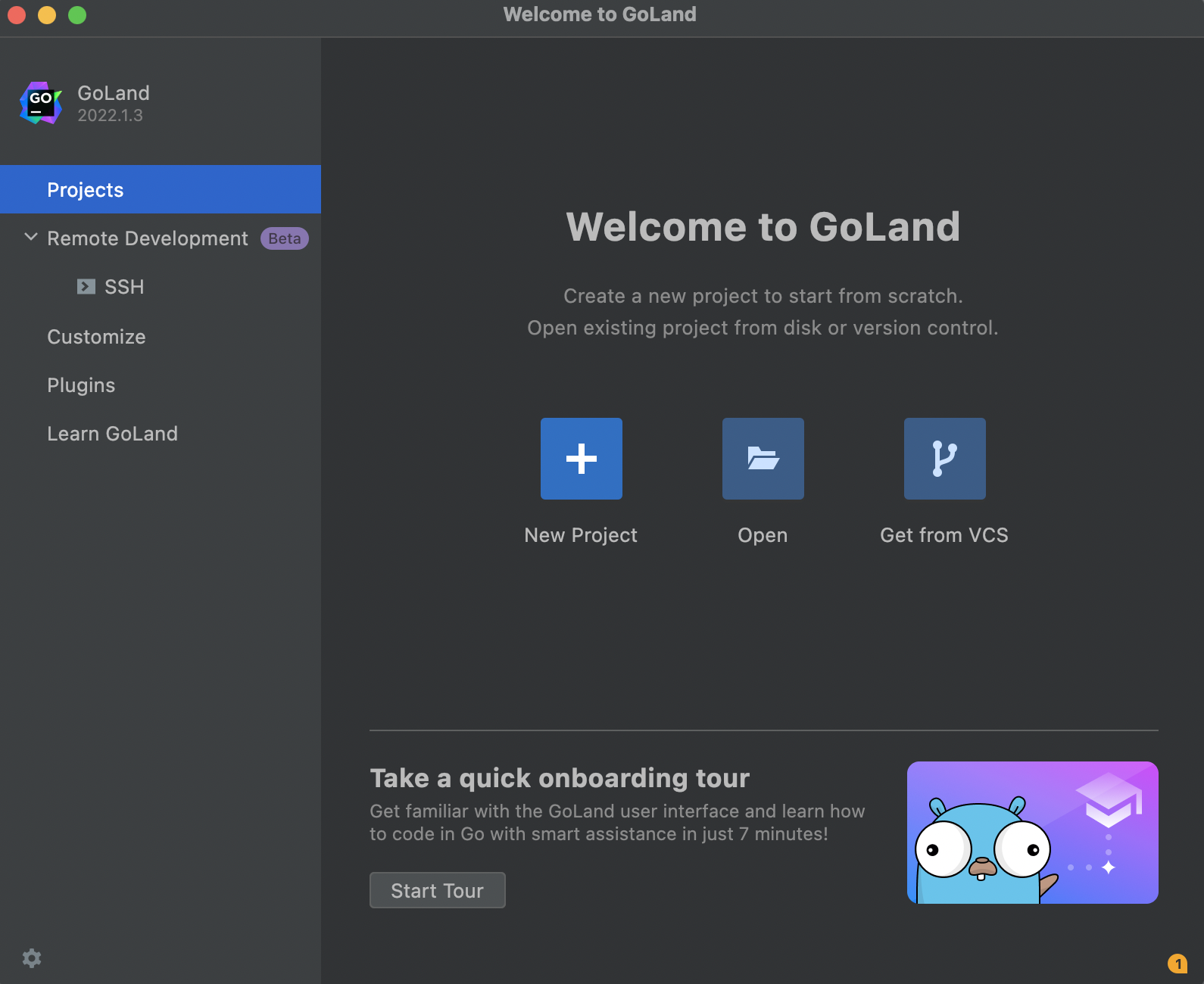
此时可以选择New Project在指定的路径创建新的项目目录或者选择Open打开已经存在的项目目录,进行编辑。
3.5.2、GoLand下编写Go程序
当GoLand启动后,便可以使用它来编写Go程序了。首先选择New Project创建一个项目。然后设置项目路径和GOROOT
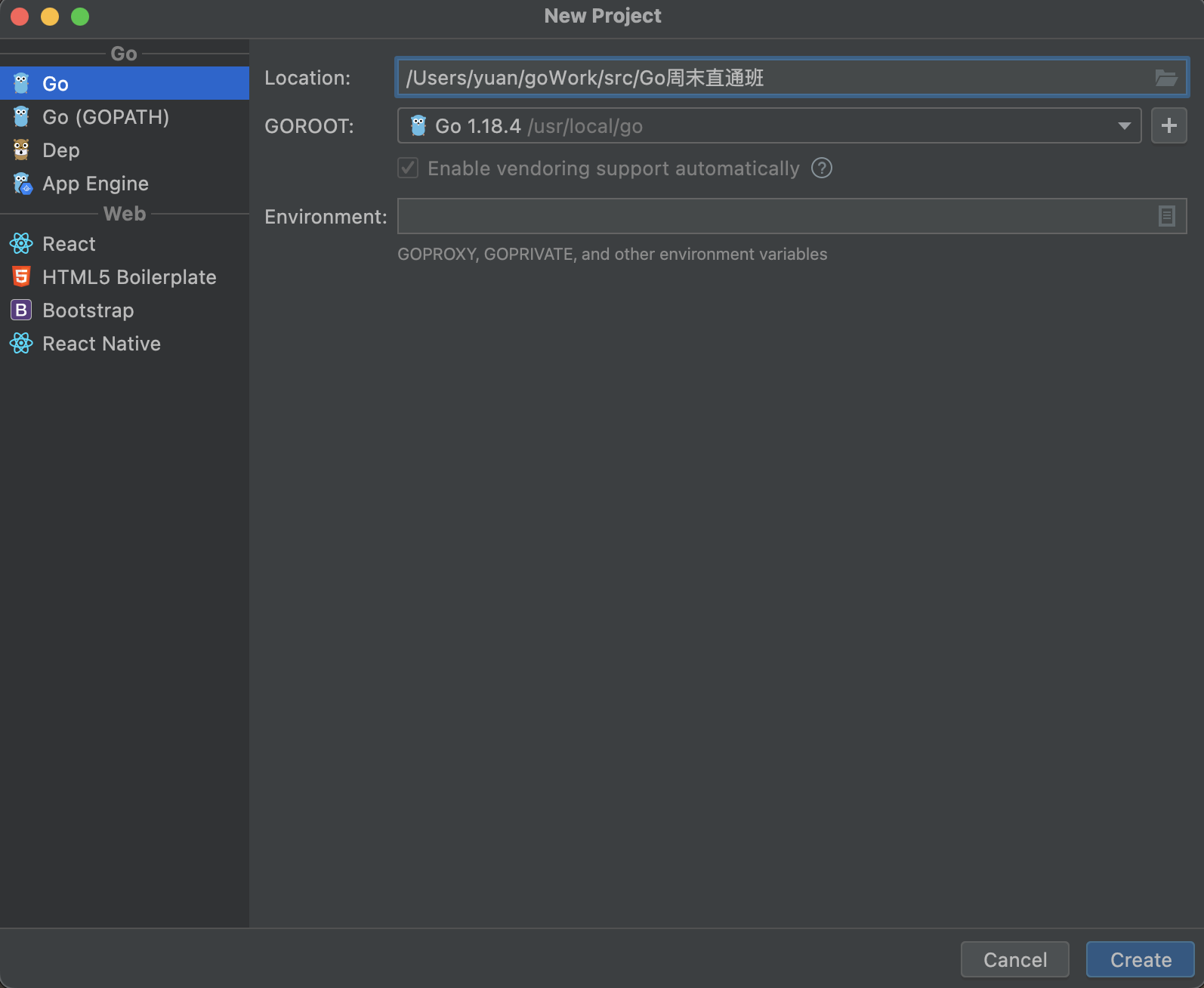
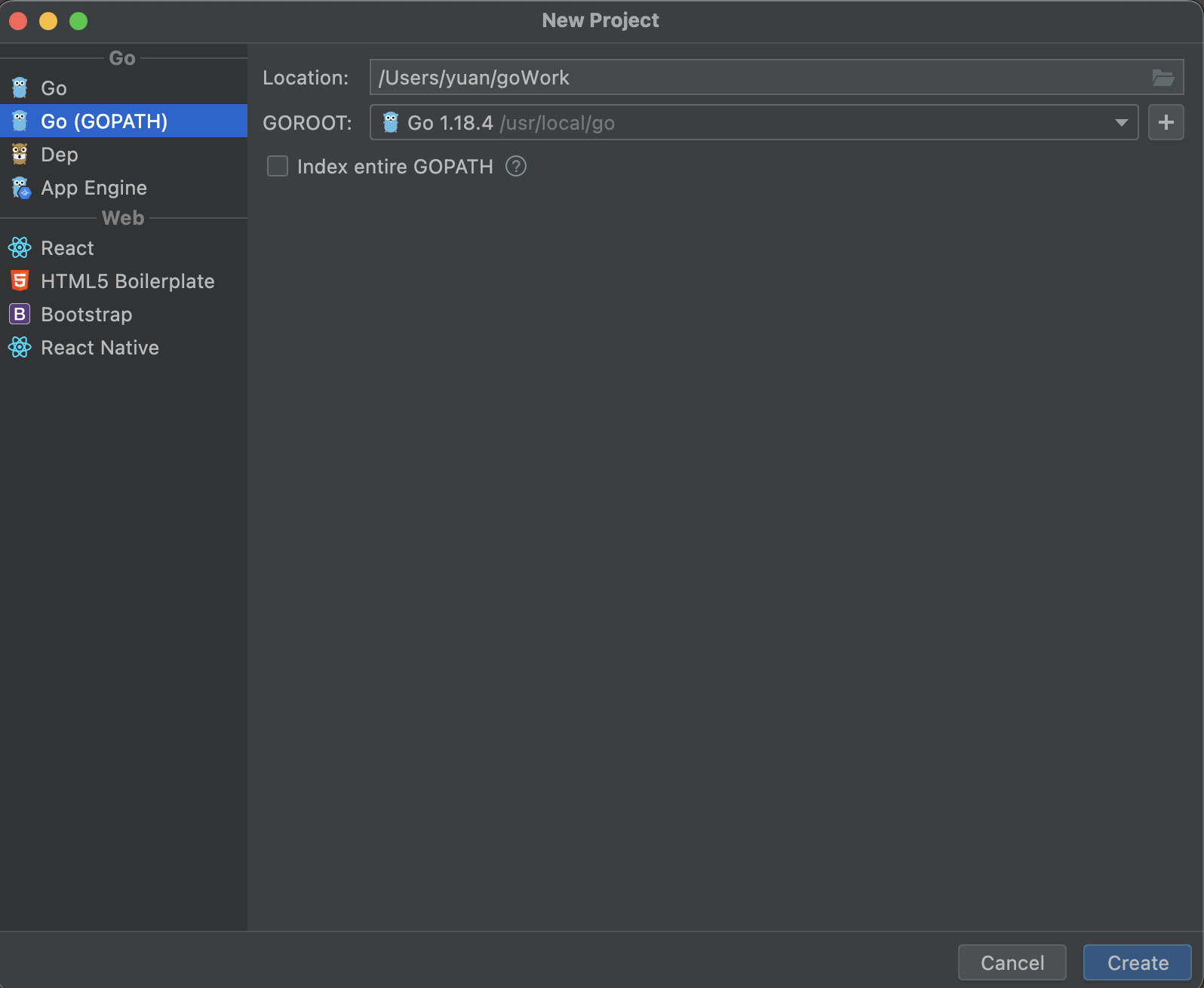
然后点击create创建。
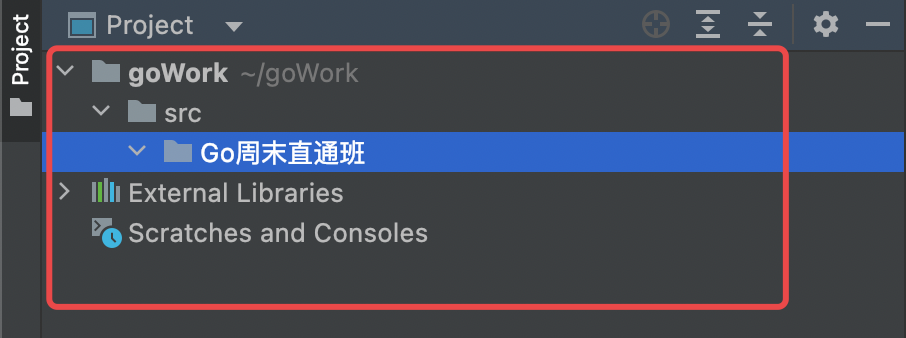
创建文件和文件夹:
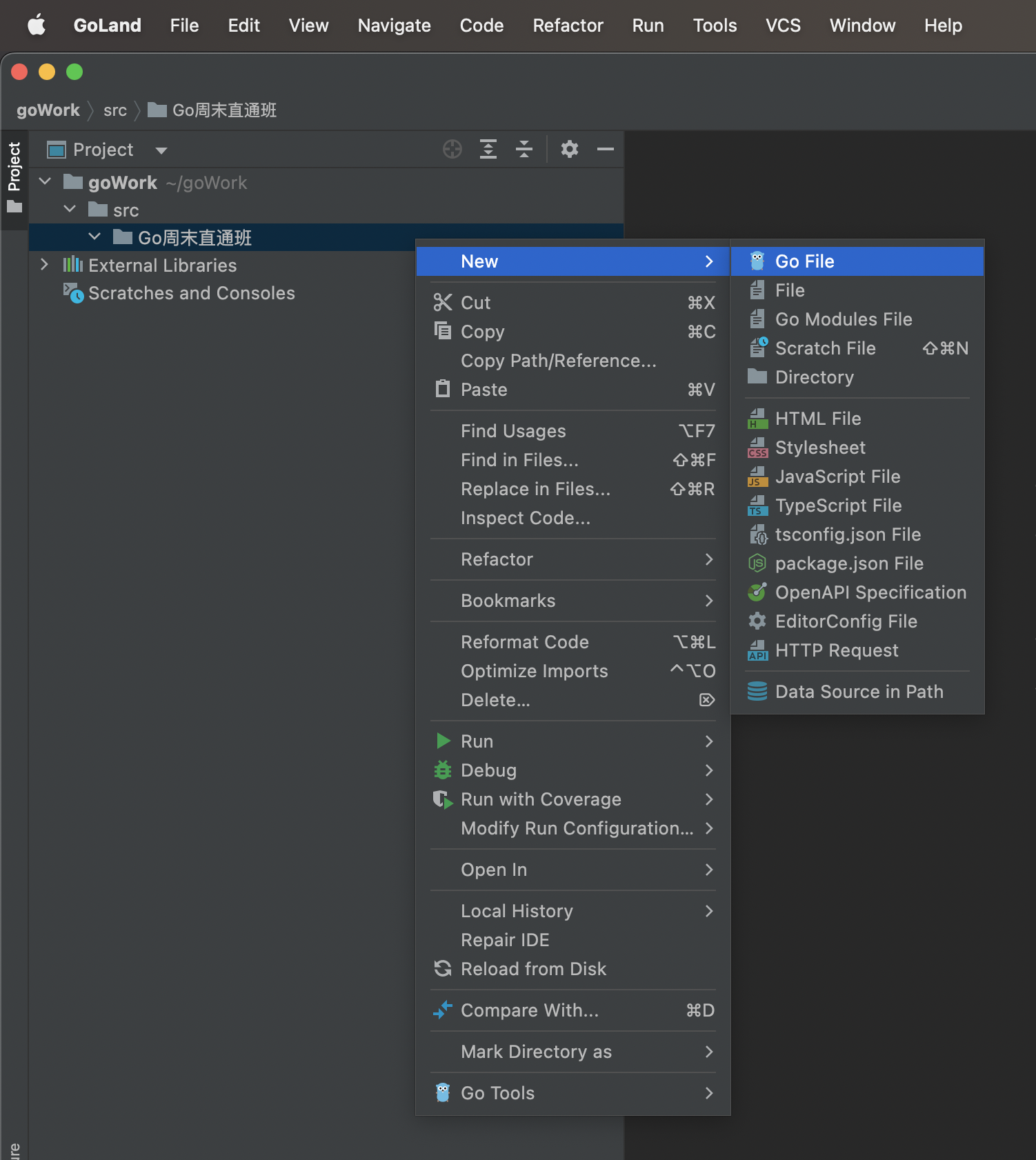
goland安装好后没有编译器的单独配置go编译器路径:
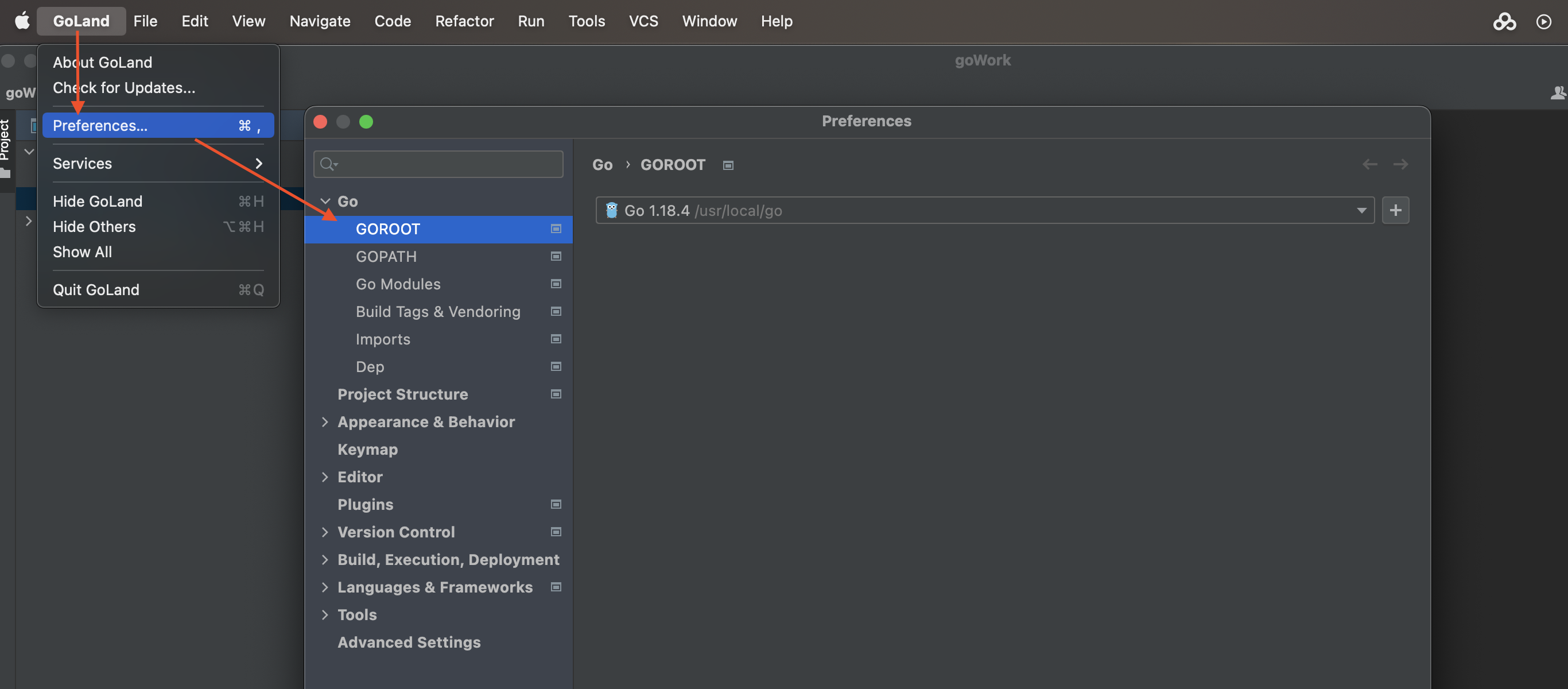
3.5.3、IDE的快捷键
| 快捷键 |
作用 |
| Ctrl + / |
单行注释 |
| Ctrl + Shift + / |
多行注释 |
| Ctrl + D |
复制当前光标所在行 |
| Ctrl + X |
删除当前光标所在行 |
| Ctrl + Alt + L |
格式化代码 |
| Ctrl + Shift + 方向键上或下 |
将光标所在的行进行上下移动(也可以使用 Alt+Shift+方向键上或下) |
| Ctrl + Alt + left/right |
返回至上次浏览的位置 |
| Ctrl + R |
替换 |
| Ctrl + F |
查找文本 |
| Ctrl + Shift + F |
全局查找 |
3.5.4、控制台折叠多余信息

四、基础语法
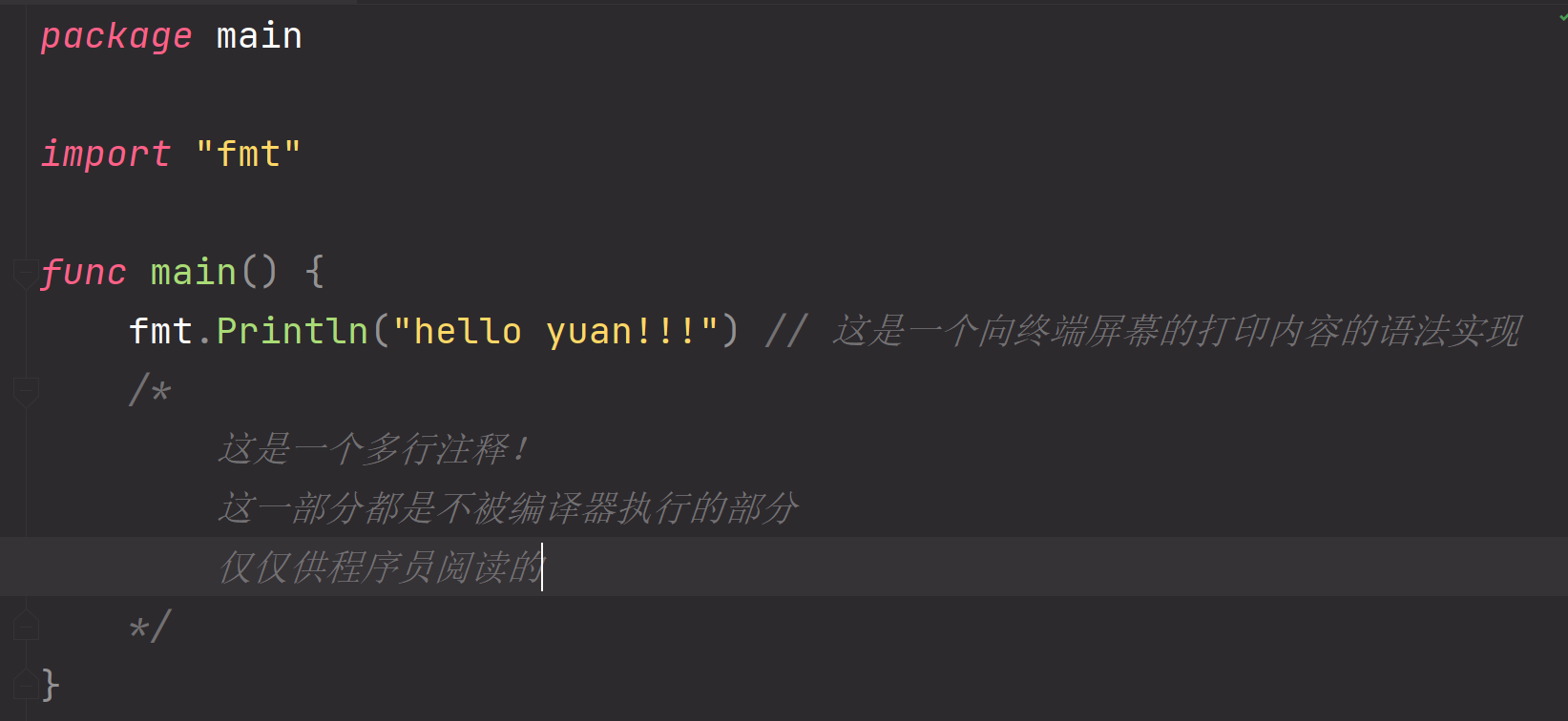
4.1、注释
注释就是对代码的解释和说明,其目的是让人们能够更加轻松地了解代码。注释是开发人员一个非常重要的习惯,也是专业的一种表现。单行注释是最常见的注释形式,你可以在任何地方使用以 // 开头的单行注释。多行注释也叫块注释,均已以 /* 开头,并以 */ 结尾。
注释只是为了提高可读性,不会被计算机编译。
4.2、变量
在计算机编程中,我们用变量来保存并管理很多数据,并用变量名来区分、识别和处理这些数据。
变量本质上是一种对内存地址的引用,让你能够把程序中准备使用的每一段数据都赋给一个简短、易于记忆的名字进行操作。
4.2.1、声明变量
和C语言一样,Go语言也是通过var关键字进行声明,不同的是变量名放在类型前,具体格式如下
1
2
3
4
5
6
7
|
var x int
var s string
var b bool
fmt.Println(x) // 0
fmt.Println(s) // ""
fmt.Println(b) // false
|
声明未赋值,系统默认赋这些类型零值
如果声明多个变量,可以进行简写
1
2
3
4
5
6
7
8
|
// 声明多个相同类型变量
var x,y int
// 声明多个不同类型变量
var (
name string
age int
isMarried bool
)
|
4.2.2、变量赋值
变量赋值的3种方法
(1)变量名=值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// 先声明再赋值
var x int
x = 10 // 不要 重复声明 : var x = 10
fmt.Println(x)
x = 20. // 重新赋值
// 直接声明赋值
// var y string= "hello yuan!"
var y = "hello yuan!"
fmt.Println(y)
// 声明赋值精简版
s := "hi,yuan!" // 1、编译器会自动根据右值类型推断出左值的对应类型,等同于var s = "hi,yuan!"。2、该变量之前不能声明,否则重复声明
fmt.Println(s)
// 一行声明赋值多个变量
var name,age = "yuan",22
|
(2)变量名=变量名
1
2
3
4
5
|
var a = 100
var b = a // 变量之间的赋值是值拷贝
fmt.Println(a, b)
a = 200
fmt.Println(b)
|
(3)变量名=值 + 值 (变量名)
1
2
3
4
5
|
var a, b = 10, 20
var c = a + b
fmt.Println(c)
var d = c + 100
fmt.Println(d)
|
练习题:
- 将x,y两个变量的值进行交换
4.2.3、匿名变量
匿名变量即没有命名的变量,在使用多重赋值时,如果想要忽略某个值,可以使用匿名变量(anonymous variable)。 匿名变量用一个下划线_表示。
1
2
3
4
5
|
a,b,c :=4,5,6
fmt.Println(a,b,c)
// 如果只想接受第个变量,可以对前两个变量匿名
_,_,x := 4,5,6
fmt.Println(x)
|
匿名变量不占用命名空间,不会分配内存
让代码非常清晰,基本上屏蔽掉了可能混淆代码阅读者视线的内容,从而大幅降低沟通的复杂度和代码维护的难度。
4.2.4、变量命名规则
变量命名是需要遵循一定的语法规范的,否则编译器不会通过。
1、变量名称必须由数字、字母、下划线组成。
2、标识符开头不能是数字。
3、标识符不能是保留字和关键字。
4、建议使用驼峰式命名,当名字有几个单词组成的时优先使用大小写分隔
5、变量名尽量做到见名知意。
6、变量命名区分大小写
go语言中有25个关键字,不能用于自定义变量名
1
2
3
4
5
|
break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var
|
还有30多个预定义的名字,用于内建的常量、类型和函数
1
2
3
4
5
6
7
8
9
10
11
|
// 内建常量:
true false iota nil
// 内建类型:
int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
// 内建函数:
make len cap new append copy close delete
complex real imag
panic recover
|
4.3、语句分隔符
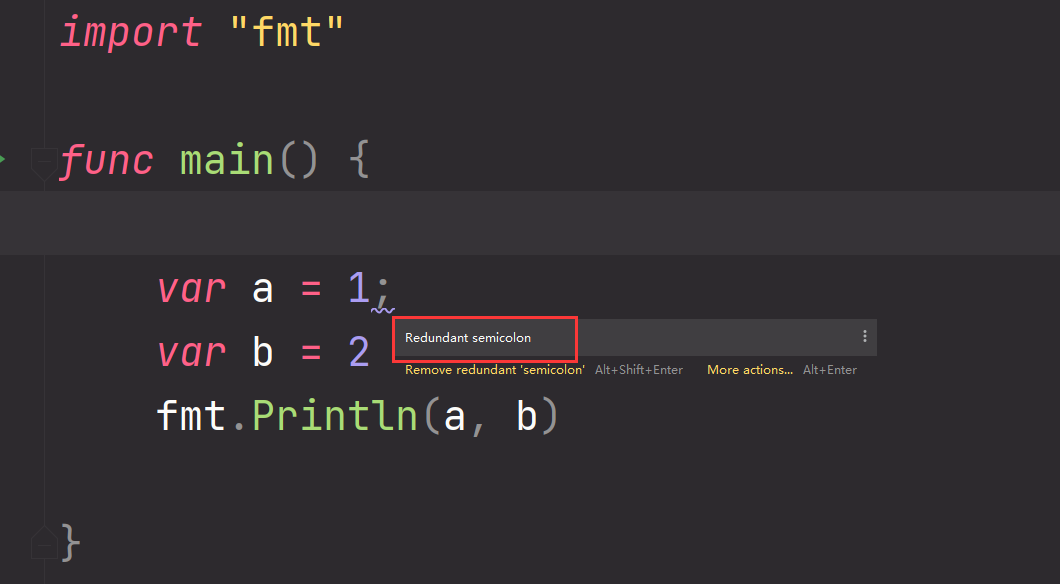
就像我们写作文一样,一定要有像逗号或者句号这样的语句分隔符,否则无法断句根本不能理解,编程语言也一样,需要给解释器或者编译器一个语句分割,让它知道哪里到哪里是一个语句,才能再去解析语句。
在 Go 程序中,一行代表一个语句结束。每个语句不需要像 C 家族中的其它语言一样以分号 ; 结尾,因为这些工作都将由 Go 编译器自动完成。如果你打算将多个语句写在同一行,它们则必须使用 ; 人为区分(不建议这样写)。
1
2
3
4
5
6
7
8
9
|
//var name = "yuan";var age = 18 // 不推荐
//fmt.Println(name)
//fmt.Println(age) // 不报错但是不推荐
// 推荐写法
var name = "yuan" // 换行即分隔符
var age = 18
fmt.Println(name)
fmt.Println(age)
|
4.4、基本数据类型
基本数据类型包含整型和浮点型,布尔类型以及字符串,这几种数据类型在几乎所有编程语言中都支持。
4.4.1、整形
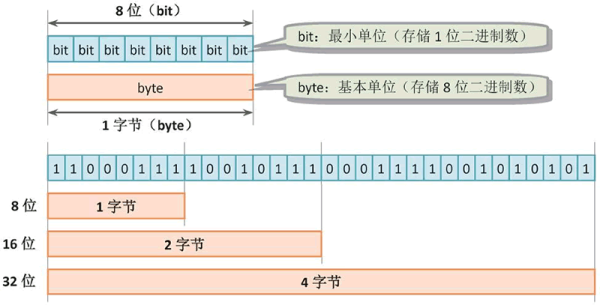
字节了解:
字节(Byte):计算机中数据储存的单位。
位(bit):也叫作“比特”,计算机中数据储存的最小单位,因为在计算机中是以二进制的形式数据储存,所以每个位以“0”或“1”表示。
位和字节的关系是:8个位组成一个字节。
字节与位的关系:1Byte=8bit。
| 具体类型 |
取值范围 |
| int8 |
-128到127 |
| uint8 |
0到255 |
| int16 |
-32768到32767 |
| uint16 |
0到65535 |
| int32 |
-2147483648到2147483647 |
| uint32 |
0到4294967295 |
| int64 |
-9223372036854775808到9223372036854775807 |
| uint64 |
0到18446744073709551615 |
| uint |
与平台相关,32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int |
与平台相关,32位操作系统上就是int32,64位操作系统上就是int64 |
1
2
3
|
var x int
x = 9223372036854775809
fmt.Print(x) // overflows int
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
// 十进制转化
var a int = 10
fmt.Printf("%d \n", a) // 10 占位符%d表示十进制
fmt.Printf("%b \n", a) // 1010 占位符%b表示二进制
fmt.Printf("%o \n", a) // 12 占位符%o表示八进制
fmt.Printf("%x \n", a) // a 占位符%x表示十六进制
// 八进制转化
var b int = 020
fmt.Printf("%o \n", b) // 20
fmt.Printf("%d \n", b) // 16
fmt.Printf("%x \n", b) // 10
fmt.Printf("%b \n", b) // 10000
// 十六进制转化
var c = 0x12
fmt.Printf("%d \n", c) // 18
fmt.Printf("%o \n", c) // 22
fmt.Printf("%x \n", c) // 12
fmt.Printf("%b \n", c) // 10010
|
4.4.2、浮点型
float类型分为float32和float64两种类型,这两种浮点型数据格式遵循 IEEE 754 标准。
单精度浮点数占用4个字节(32位)存储空间来存储一个浮点数。而双精度浮点数使用 8个字节(64位)存储空间来存储一个浮点数。
单精度浮点数最多有7位十进制有效数字,如果某个数的有效数字位数超过7位,当把它定义为单精度变量时,超出的部分会自动四舍五入。双精度浮点数可以表示十进制的15或16位有效数字,超出的部分也会自动四舍五入。
浮点类型默认声明为float64。
1
2
3
4
5
6
7
8
9
10
|
var f1 float32 // float32: 单精度浮点型
f1 = 3.1234567890123456789
fmt.Println(f1, reflect.TypeOf(f1))
var f2 float64 // 双精度浮点型
f2 = 3.1234567890123456789
fmt.Println(f2, reflect.TypeOf(f2))
var f3 = 3.1234567890123456789
fmt.Println(f3, reflect.TypeOf(f2)) // 默认64
|
1
2
3
4
5
|
var f1 = 2e10 // 即使是整数用科学技术表示也是浮点型
fmt.Println(f1,reflect.TypeOf(f1))
var f2 = 2e-2
fmt.Println(f2,reflect.TypeOf(f2))
|
4.4.3、布尔类型
布尔类型是最基本数据类型之一,只有两个值:true和false,分别代表逻辑判断中的真和假,主要应用在条件判断中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
package main
import (
"fmt"
"reflect"
)
func main() {
var b bool // 声明b是一个布尔类型
b = true
b = false // 该类型只有true和false两个值,分别代表真假两种状态
fmt.Println(b, reflect.TypeOf(b))
fmt.Println(1 == 1) // 比较运算符的结果是一个布尔值
// fmt.Println(1 == "1") // 报错,mismatched types不能比较
fmt.Println(3 > 1)
var name = "yuan"
var b2 = name == "rain"
fmt.Println(b2)
}
|
4.4.4、字符串
字符串是最基本也是最常用的数据类型,是通过双引号将多个字符按串联起来的一种数据,用于展示文本。
1
2
|
var s = "hello yuan"
fmt.Println(s)
|
单引号只能标识字符
字符串的基本操作
字符串在内存中是一段连续存储空间
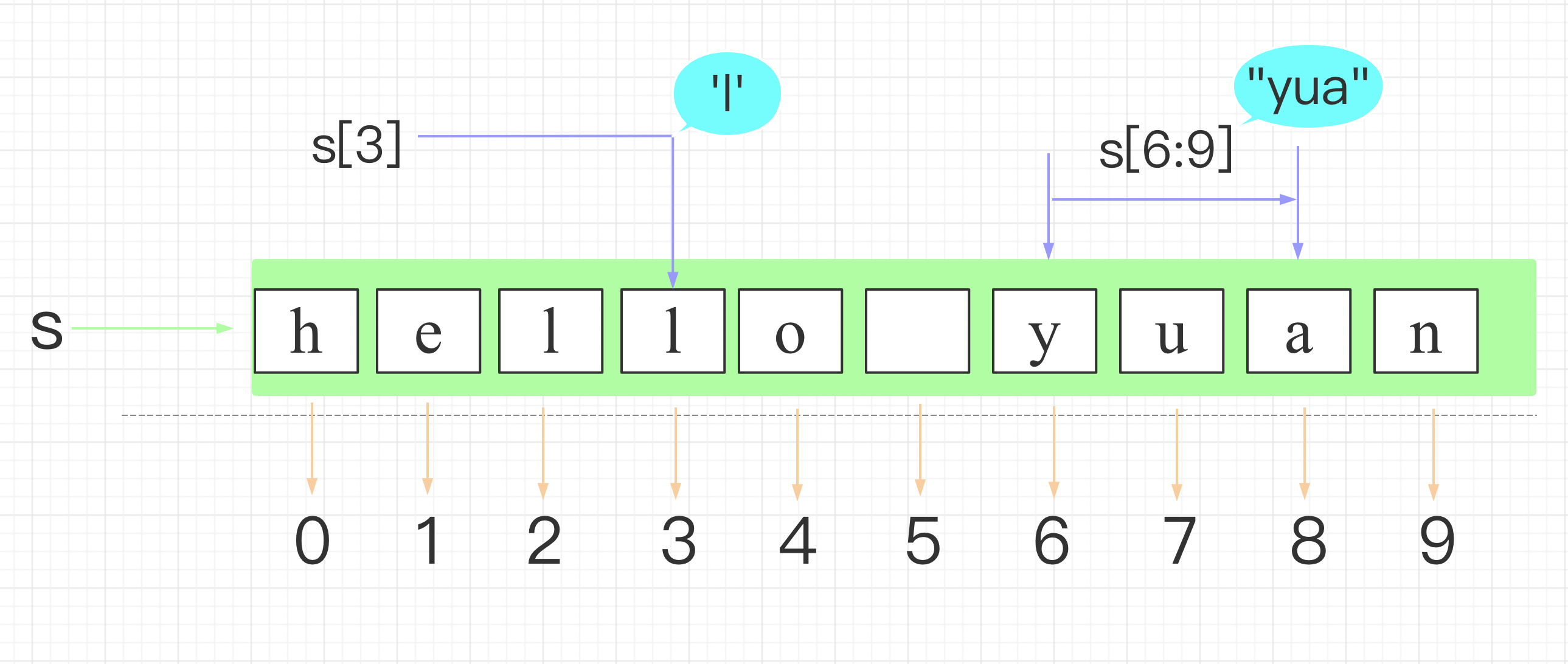
注意:
- 索引从零开始计数
- go语言不支持负索引
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
var s = "hello yuan"
fmt.Println(s)
// (1)索引取值 slice[index]
a:= s[2]
fmt.Println(string(a))
// (2)切片取值slice[start:end], 取出的元素数量为:结束位置 - 开始位置;
b1:=s[2:5] //
fmt.Println(b1)
b2:=s[0:] // 当缺省结束位置时,表示从开始位置到整个连续区域末尾;
fmt.Println(b2)
b3:=s[:8] // 当缺省开始位置时,表示从连续区域开头到结束位置;
fmt.Println(b3)
// (3)字符串拼接
var s1 = "hello"
var s2 = "yuan"
var s3 = s1 + s2 // 生成一个新的字符串
fmt.Println(s3)
|
转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
| 转义符 |
含义 |
\r |
回车符(返回行首) |
\n |
换行符(直接跳到下一行的同列位置) |
\t |
制表符 |
\' |
单引号 |
\" |
双引号 |
\\ |
反斜杠 |
举个例子,我们要打印一个Windows平台下的一个文件路径:
1
2
3
4
5
6
7
8
9
10
11
12
|
package main
import "fmt"
func main() {
var s1 = "hi yuan\nhi,alvin"
fmt.Println(s1)
var s2 = "his name is \"rain\""
fmt.Println(s2)
var s3 = "D:\\next\\go.exe"
fmt.Println(s3)
}
|
多行字符串
Go语言中要定义一个多行字符串时,就必须使用反引号字符:
1
2
3
4
5
|
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
|
反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
字符串的常用方法
| 方法 |
介绍 |
len(str) |
求长度 |
strings.ToUpper,strings.ToLower |
生成一个新的全部大写的字符串,生成一个新的全部小写的字符串 |
strings.ReplaceAll |
生成一个新的原字符串被指定替换后的字符串 |
strings.Contains |
判断是否包含 |
strings.HasPrefix,strings.HasSuffix |
前缀/后缀判断 |
strings.Trim、 |
去除字符串两端匹配的内容 |
strings.Index(),strings.LastIndex() |
子串出现的位置 |
strings.Split |
分割,将字符串按指定的内容分割成数组 |
strings.Join(a[]string, sep string) |
join操作,将数组按指定的内容拼接成字符串 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
package main
import (
"fmt"
"reflect"
"strings"
)
func main() {
s := "hello world"
// fmt.Println(len(s))
// strings.ToUpper 和 strings.ToLower
s1 := strings.ToUpper("Yuan")
s2 := strings.ToLower("Rain")
fmt.Println(s1, s2)
// strings.Trim
user := " yuan "
fmt.Println(len(user))
fmt.Println(strings.TrimLeft(user, " "))
fmt.Println(strings.TrimSpace(user))
fmt.Println(strings.Trim(user, " "))
s := "alvin,yuan,eric"
// strings.Index,strings.LastIndex
var index = strings.Index(s, "yuan!")
fmt.Println(index) // 未找到返回-1
var index2 = strings.LastIndex(s, "l")
fmt.Println(index2)
// strings.HasPrefix,strings.HasSuffix,strings.Contains(实现的依赖的就是strings.Index)
fmt.Println(strings.HasPrefix(s, "alv"))
fmt.Println(strings.HasSuffix(s, "eric"))
fmt.Println(strings.Contains(s, "eric"))
// strings.Split: 将字符串分割成数组
var ret2 = strings.Split(s, ",")
fmt.Println(ret2, reflect.TypeOf(ret2))
// strings.Join:将数组拼接成字符串
var ret3 = strings.Join(ret2, "-")
fmt.Println(ret3, reflect.TypeOf(ret3))
}
|
练习:
- 基于字符串操作获取用户名和密码* s := “mysql … -u root -p 123”
4.4.6、类型转换
Go语言中只有强制类型转换,没有隐式类型转换。该语法只能在两个类型之间支持相互转换的时候使用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
// (1)整型之间的转换
var a int8
a = 99
fmt.Println(int64(a), reflect.TypeOf(int64(a)))
fmt.Println(float64(a), reflect.TypeOf(float64(a)))
// (2)string与int类型的转换
x := strconv.Itoa(98)
fmt.Println(x, reflect.TypeOf(x))
y, _ := strconv.Atoi("97")
fmt.Println(y, reflect.TypeOf(y))
// (3) Parse系列函数
// ParseInt
// 输入:1.数字的字符串形式 2.base,数字字符串的进制,比如:2进制、10进制。
// 3.bitSize的含义是⼤⼩限制,如果字符串转化的整形数据类型超过bitSize的最大值,那么输出的int64为bitSize的最大值,err就会显⽰数据超出范围。
i1, _ := strconv.ParseInt("1000", 10, 8)
println(i1)
i2, _ := strconv.ParseInt("1000", 10, 64)
println(i2)
f2, _ := strconv.ParseFloat("3.1415926", 64)
fmt.Println(f2, reflect.TypeOf(f2))
f1, _ := strconv.ParseFloat("3.1415926", 32)
fmt.Println(f1, reflect.TypeOf(f1))
// 返回字符串表示的bool值。它接受1、0、t、f、T、F、true、false、True、False、TRUE、FALSE;否则返回错误。
b1, _ := strconv.ParseBool("true")
fmt.Println(b1, reflect.TypeOf(b1))
b2, _ := strconv.ParseBool("T")
fmt.Println(b2, reflect.TypeOf(b2))
b3, _ := strconv.ParseBool("1")
fmt.Println(b3, reflect.TypeOf(b3))
b4, _ := strconv.ParseBool("100")
fmt.Println(b4, reflect.TypeOf(b4))
|
4.5、运算符
一个程序的最小单位是一条语句,一条语句最少包含一条指令,而指令就是对数据做运算,我们已经学完基本数据类型了,知道如何构建和使用一些最简单的数据,那么我们能对这些数据做什么运算呢,比如fmt.Println(1+1)这条语句包含两个指令,首先是计算1+1的指令,1就是数据,+就是算术运算符中的相加,这样计算机就可以帮我们执行这个指令计算出结果,然后执行第二个指令,即将计算结果2打印在终端,最终完成这条语句。
4.5.1、算数运算符
| 运算符 |
描述 |
| + |
相加 |
| - |
相减 |
| * |
相乘 |
| / |
相除 |
| % |
求余 |
如何判断一个整型数字是奇数还是偶数?
4.5.2、关系运算符
| 运算符 |
描述 |
| == |
检查两个值是否相等,如果相等返回 True 否则返回 False。 |
| != |
检查两个值是否不相等,如果不相等返回 True 否则返回 False。 |
| > |
检查左边值是否大于右边值,如果是返回 True 否则返回 False。 |
| < |
检查左边值是否小于右边值,如果是返回 True 否则返回 False。 |
| >= |
检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 |
| <= |
检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 |
4.5.3、逻辑运算符
| 运算符 |
描述 |
| && |
逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 |
| || |
逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 |
| ! |
逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 |
1
2
3
4
5
6
|
fmt.Println(2.1 > 1 || 3 == 2)
// 用户名为root或者年龄大于18岁
username := "root"
age := 16
ret := username == "root" || !(age < 18)
fmt.Println(ret)
|
4.5.4、赋值运算符
| 运算符 |
描述 |
| = |
简单的赋值运算符,将一个表达式的值赋给一个左值 |
| += |
相加后再赋值 |
| -= |
相减后再赋值 |
| *= |
相乘后再赋值 |
| /= |
相除后再赋值 |
| %= |
求余后再赋值 |
| «= |
左移后赋值 |
| »= |
右移后赋值 |
| &= |
按位与后赋值 |
| ^= |
按位异或后赋值 |
| |= |
按位或后赋值 |
1
2
3
4
5
6
7
8
9
10
11
12
|
var a = 10
// 使a自加1
ret := a + 1
a = ret
// 使a自加1
a = a + 1
// 使a自加1
a += 1 // 赋值元算符
// 使a自加1
a++ // 注意:不能写成 ++ a 或 -- a 必须放在右边使用
// b := a++ // 此处为错误的用法,不能写在一行,要单独作为语句使用
fmt.Println(a)
|
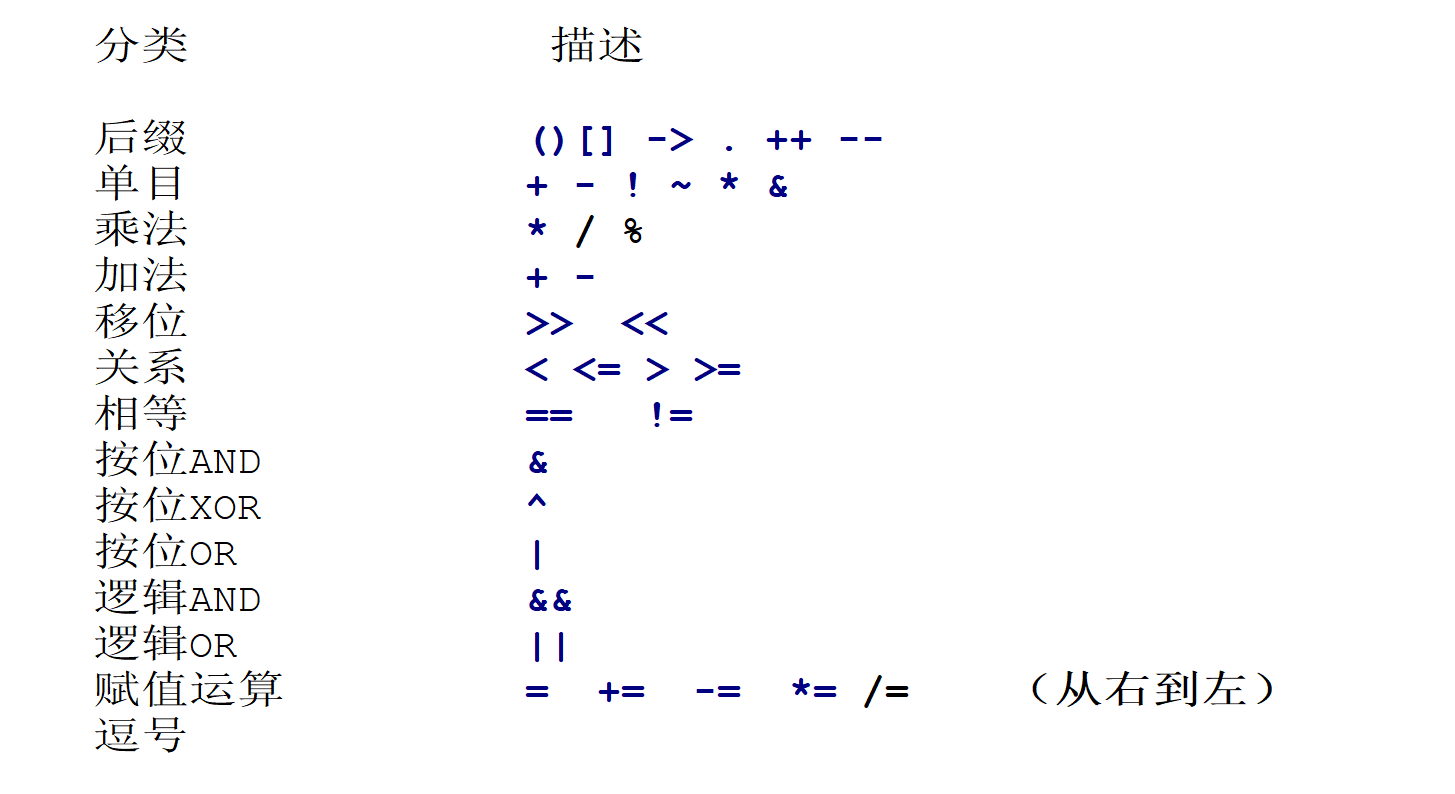
4.5.5、运算符优先级
1
2
3
4
5
6
7
8
9
10
11
12
|
// 案例1
var a, b, c, d = 8, 6, 4, 2
ret := a + b*c/d
fmt.Println(ret)
// 案例2
x := 10
y := 1
x += 5*(1+2) + y
fmt.Println(x)
z := 1+2 > 3 || 1 == 1*5
fmt.Println(z)
|
为什么x = 1+1, 为什么先计算后赋值:运算符的优先级
4.6、输入输出函数
4.6.1、输出函数
fmt.Print有几个变种:
Print: 输出到控制台,不接受任何格式化操作
Println: 输出到控制台并换行
Printf : 只可以打印出格式化的字符串,只可以直接输出字符串类型的变量(不可以输出别的类型)
Sprintf:格式化并返回一个字符串而不带任何输出
(1)Print 和Println
Print和Println()函数可以打印出字符串或变量的值。
1
2
3
4
5
6
7
8
9
10
|
name := "yuan"
age := 24
fmt.Print(name, age)
fmt.Println("hello world")
fmt.Println(name)
fmt.Println(age)
fmt.Println(name, age)
fmt.Println("姓名:", name, "年龄:", age)
|
(2)格式化输出(Printf)
Printf 根据格式说明符格式化并写入标准输出。Printf 只打印字符串
比如上面打印一个人的基本信息格式:
1
2
3
4
5
6
7
|
name := "yuan"
age := 24
isMarried := false
salary := 3000.549
fmt.Printf("姓名:%s 年龄:%d 婚否:%t 薪资:%.2f\n", name, age, isMarried, salary)
fmt.Printf("姓名:%v 年龄:%v 婚否:%v 薪资:%v\n", name, age, isMarried, salary)
fmt.Printf("姓名:%#v 年龄:%#v 婚否:%#v 薪资:%#v\n", name, age, isMarried, salary)
|
|
%v:以默认的方式打印变量的值 |
%#v:相应值的Go语法表示 |
%T:打印对应值的类型 |
%+d :带符号的整型,%d 不带符号的整型 |
%o :不带零的八进制,%#o 带零的八进制 |
%x :小写的十六进制,%X 大写的十六进制,%#x 带0x的十六进制 |
%b :打印整型的二进制 |
%t :打印true 或 false |
%s :输出字符串表示,%-5s 最小宽度为5(左对齐) |
%f 小数点而无指数,默认精度为6 |
%e 科学计数法,如-1234.456e+78 |
%p 带0x的指针,%#p 不带0x的指针 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
// 整形和浮点型
fmt.Printf("%b\n", 12) // 二进制表示:1100
fmt.Printf("%d\n", 12) // 十进制表示:12
fmt.Printf("%o\n", 12) // 八进制表示:14
fmt.Printf("%x\n", 12) // 十六进制表示:c
fmt.Printf("%X\n", 12) // 十六进制表示:c
fmt.Printf("%f\n", 3.1415) // 有小数点而无指数:3.141500
fmt.Printf("%.3f\n", 3.1415) // 3.142
fmt.Printf("%e\n", 1000.25) // 科学计数法: 1.000250e+03,默认精度为6
// 设置宽度
fmt.Printf("学号:%s 姓名:%-20s 平均成绩:%-4d\n", "1001", "alvin", 100)
fmt.Printf("学号:%s 姓名:%-20s 平均成绩:%-4d\n", "1002", "zuibangdeyuanlaoshi", 98)
fmt.Printf("学号:%s 姓名:%-20s 平均成绩:%-4d\n", "1003", "x", 78)
|
(3)Sprintf
Printf和Sprintf都是替换字符串,Printf是直接输出到终端,Sprintf是不直接输出到终端,而是返回该字符串
1
2
3
4
5
6
|
name := "yuan"
age := 24
isMarried := false
salary := 3000.549
info := fmt.Sprintf("姓名:%s 年龄:%d 婚否:%t 薪资:%.2f\n", name, age, isMarried, salary)
fmt.Println(info)
|
4.6.2、输入函数
go语言fmt包下有三个函数,可以在程序运行过程中从标准输入获取用户的输入:
(1)fmt.Scan
语法:
func Scan(a ...interface{}) (n int, err error)
- Scan 从标准输入扫描文本,读取由空白符分隔的值保存到传递给本函数的参数中,换行符视为空白符。
- 本函数返回成功扫描的数据个数和遇到的任何错误。如果读取的数据个数比提供的参数少,会返回一个错误报告原因。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
package main
import "fmt"
func main() {
var (
name string
age int
isMarried bool
)
fmt.Scan(&name, &age, &isMarried) // 输入类型不一致,按默认值
fmt.Printf("扫描结果 name:%s age:%d married:%t\t", name, age, isMarried)
}
|
将上述代码在终端运行,在终端依次输入 yuan 、26、false使用空格分隔。
go run main.go
yuan 26 false
扫描结果 name:yuan age:26 married:false
fmt.Scan从标准输入中扫描用户输入的数据,将以空白符分隔的数据分别存入指定的参数中。
(2)fmt.Scanf
语法
func Scanf(format string, a ...interface{})(n int, err error)
- Scanf从标准输入扫描文本,根据format参数指定的格式去读取由空白符分隔的值保存到传递给本函数的参数中。
- 本函数返回成功扫描的数据个数和遇到的任何错误。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// 案例1
var (
name string
age int
isMarried bool
)
fmt.Scanf("1:%s 2:%d 3:%t", &name,&age,&isMarried)
fmt.Printf("扫描结果 姓名:%s 年龄:%d 婚否:%t", name,age,isMarried)
// 案例2
var a, b int
fmt.Scanf("%d+%d", &a, &b)
fmt.Println(a + b)
|
(3)fmt.Scanln
语法
func Scanln(a ...interface{}) (n int, err error)
- Scanln类似于Scan,它遇到换行立即停止扫描。
- 本函数返回成功扫描的数据个数和遇到的任何错误。
Scanln和Scan的区别就是Scanln遇到换行立即结束输入,而Scan则会将换行符作为一个空白符继续下一个输入
4.7、常量与itoa
4.7.1 常量
常量是⼀个简单值的标识符,在程序运⾏时,不会被修改的量。
在Python、Java编程规范中,常量⼀般都是全⼤写字母,但是在Golang中,⼤⼩写是具有⼀定特殊含义的,所以不⼀定所有常量都得全⼤写。
声明赋值方式与变量接近,通过const实现
const 常量名[数据类型] = value
数据类型可以忽略不写,Golang编译器会⾃动推断出数据类型。
在使⽤时,要注意以下⼏点:
- 数据类型只可以是布尔型、数字型(整数型、浮点型和复数)和字符串型
- 满⾜多重赋值
- 常量只定义不使⽤,编译不会报错
- 常量可以作为枚举,常量组
- 常量组中如不指定类型和初始化值,则与上⼀⾏⾮空常量右值相同
- 显⽰指定类型的时候,必须确保常量左右值类型⼀致,需要时可做显⽰类型转换。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
// (1)声明常量
const pai = 3.1415926
const e float64 = 2.7182818
fmt.Println(pai * pai)
// (2)常量也可以和变量一样一组一起声明
// const monday, tuesday, wednesday = 1, 2, 3
// 更推荐下面这种方式
const (
monday = 1
tuesday = 2
wednesday = 3
thursday = 4
friday = 5
saturday = 6
sunday = 7
)
const (
female = 0
male = 1
)
// ⼀组常量中,如果某个常量没有初始值,默认和上⼀⾏⼀致
const (
a int = 1
b
c = 2
d
)
fmt.Println(a, b, c, d)
|
4.7.2 iota计数器
iota是go语言的常量计数器,只能在常量的表达式中使用。 使用iota时只需要记住以下两点
1.iota在const关键字出现时将被重置为0。
2.const中每新增一行常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
const (
food = iota
cloth
bed
electric
)
fmt.Println(food, cloth, bed, electric)
const (
a = 1
b = iota
c = 6
d
e = iota
f
)
fmt.Println(a, b, c, d, e, f)
|
1
2
3
4
5
6
7
8
9
10
|
const (
b = 1 << (iota * 10)
kb
mb
gb
tb
pb
)
fmt.Println(b, kb, mb, gb, tb, pb)
|
思考题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const (
n1 = iota
n2
_
n4
)
const (
a = iota
b
_
c, d = iota + 1, iota + 2
e = iota
)
fmt.Println(a, b, c, d, e)
|
五、流程控制语句
程序是由语句构成,而流程控制语句 是用来控制程序中每条语句执行顺序的语句。可以通过控制语句实现更丰富的逻辑以及更强大的功能。几乎所有编程语言都有流程控制语句,功能也都基本相似。
其流程控制方式有
这里最简单最常用的就是顺序结构,即语句从上至下一一执行。
5.1、分支语句
顺序结构的程序虽然能解决计算、输出等问题,但不能做判断再选择。对于要先做判断再选择的问题就要使用分支结构。
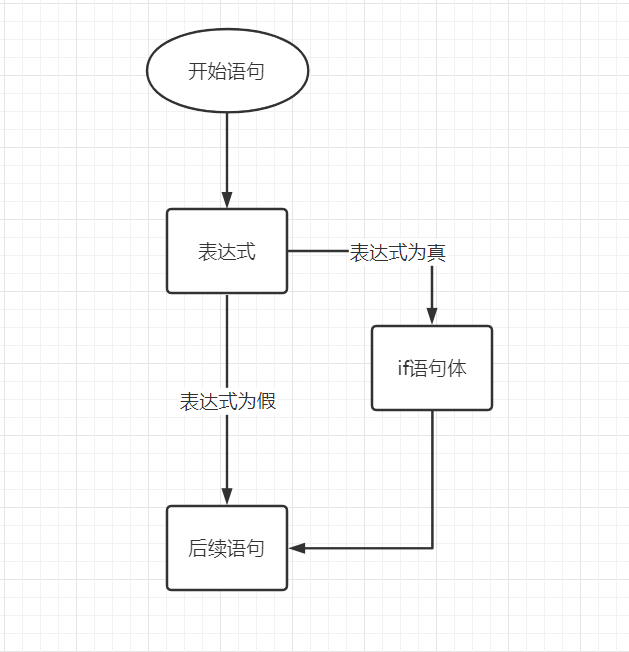
5.1.1、单分支语句
语法:
1
2
3
|
if 布尔表达式 { // 注意左花括号必须与表达式同行
/* 在布尔表达式为 true 时执行 */
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
var username,password string
fmt.Print("请输入用户名:")
fmt.Scanln(&username)
fmt.Println("username",username)
fmt.Print("请输入密码:")
fmt.Scanln(&password)
fmt.Println("password",password)
if username == "yuan" && password=="123"{
fmt.Println("登录成功!")
}
|
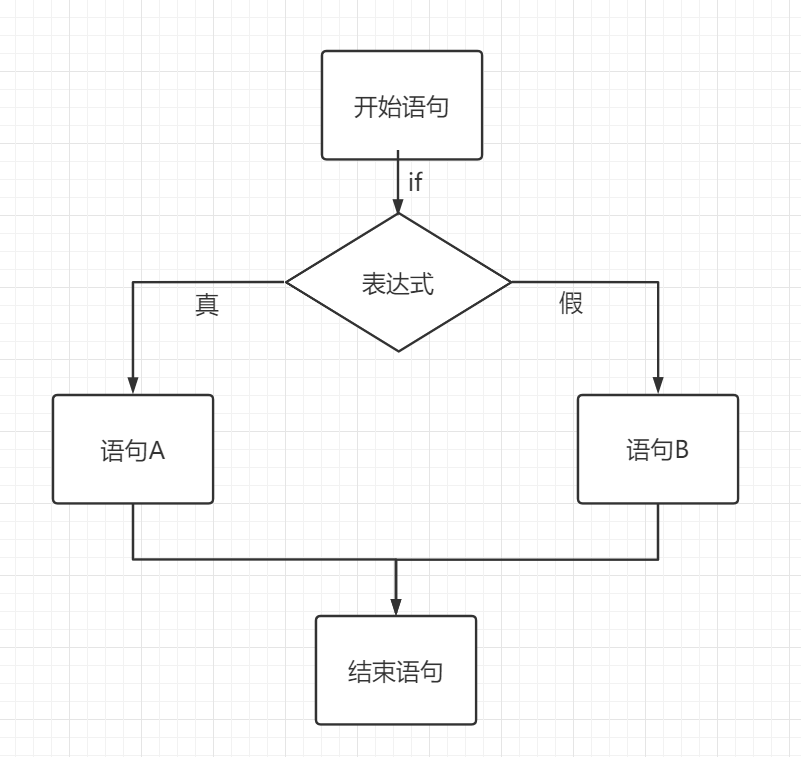
5.1.2、双分支语句
双分支语句顾名思义,二条分支二选一执行!
1
2
3
4
5
6
7
8
|
var age int
fmt.Println("请输入你的年龄:")
fmt.Scanln(&age)
if age >= 18 {
fmt.Println("恭喜,你已经成年,可以观看该影片!")
} else {
fmt.Println("抱歉,你还未成年,不宜观看该影片!")
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
var username,password string
fmt.Print("请输入用户名:")
fmt.Scanln(&username)
fmt.Println("username",username)
fmt.Print("请输入密码:")
fmt.Scanln(&password)
fmt.Println("password",password)
if username == "yuan" && password=="123"{
fmt.Println("登录成功!")
}else {
fmt.Println("用户名或者密码错误!")
}
|
5.1.3、if多分支语句
多分支即从比双分支更多的分支选择一支执行。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package main
import "fmt"
func main() {
var score int
fmt.Scanln(&score)
if score > 100 && score < 0 {
fmt.Println("输入数字应该在1-100之间")
} else if score > 90 {
fmt.Println("成绩优秀!")
} else if score > 80 {
fmt.Println("成绩良好!")
} else if score > 60 {
fmt.Println("成绩及格!")
} else {
fmt.Println("请输入一个数字!")
}
}
|
不管多少条分支只能执行一条分支!
练习:根据用户输入的生日判断星座

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
|
var month, day int
fmt.Print("请输入生日的月和日:")
fmt.Scan(&month, &day)
var xingZuo string
if day < 1 || day > 31 {
fmt.Println("输入的日有问题")
os.Exit(0)
}
switch month {
case 1:
// 日判断
if day >= 1 && day <= 19 {
xingZuo = "摩羯座"
} else {
xingZuo = "水瓶座"
}
case 2:
// 日判断
if day >= 1 && day <= 18 {
xingZuo = "水瓶座"
} else {
xingZuo = "双鱼座"
}
case 3:
// 日判断
if day >= 1 && day <= 20 {
xingZuo = "双鱼座"
} else {
xingZuo = "白羊座"
}
case 4:
// 日判断
if day >= 1 && day <= 19 {
xingZuo = "白羊座"
} else {
xingZuo = "金牛座"
}
case 5:
// 日判断
if day >= 1 && day <= 20 {
xingZuo = "金牛座"
} else {
xingZuo = "双子座"
}
case 6:
// 日判断
if day >= 1 && day <= 21 {
xingZuo = "双子座"
} else {
xingZuo = "巨蟹座"
}
case 7:
// 日判断
if day >= 1 && day <= 22 {
xingZuo = "巨蟹座"
} else {
xingZuo = "狮子座"
}
case 8:
// 日判断
if day >= 1 && day <= 22 {
xingZuo = "狮子座"
} else {
xingZuo = "处女座"
}
case 9:
// 日判断
if day >= 1 && day <= 22 {
xingZuo = "处女座"
} else {
xingZuo = "天秤座"
}
case 10:
// 日判断
if day >= 1 && day <= 23 {
xingZuo = "天秤座"
} else {
xingZuo = "天蝎座"
}
case 11:
// 日判断
if day >= 1 && day <= 22 {
xingZuo = "天蝎座"
} else {
xingZuo = "射手座"
}
case 12:
// 日判断
if day >= 1 && day <= 21 {
xingZuo = "射手座"
} else {
xingZuo = "摩羯座"
}
default:
fmt.Println("输入的月份有问题")
}
fmt.Println("您的星座是:", xingZuo)
|
5.1.4、switch多分支语句
语法:
1
2
3
4
5
6
7
8
|
switch var {
case val1:
...
case val2:
...
default:
...
}
|
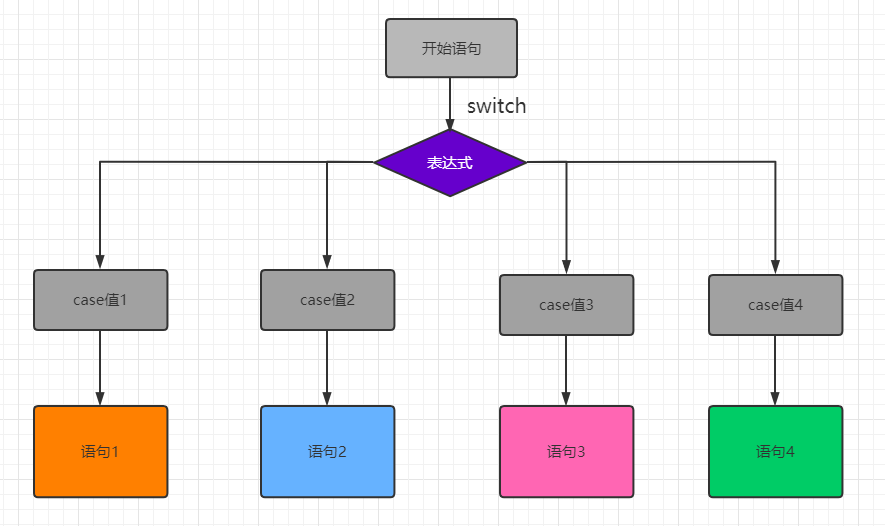
switch语句也是多分支选择语句,执行哪一代码块,取决于switch后的值与哪一case值匹配成功,则执行该case后的代码块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
/*
给出如下选项,并根据选项进行效果展示:
输入1:则输出"普通攻击"
输入2:则输出"超级攻击"
输入3:则输出"使用道具"
输入3:则输出"逃跑"
*/
var choice int
fmt.Println("请输入选择:")
fmt.Scanln(&choice)
//fmt.Println(choice,reflect.TypeOf(choice))
switch choice {
case 1:fmt.Println("普通攻击")
case 2:fmt.Println("超级攻击")
case 3:fmt.Println("使用道具")
case 4:fmt.Println("逃跑")
default:fmt.Println("输入有误!")
}
|
1、switch比if else更为简洁
2、执行效率更高。switch…case会生成一个跳转表来指示实际的case分支的地址,而这个跳转表的索引号与switch变量的值是相等的。从而,switch…case不用像if…else那样遍历条件分支直到命中条件,而只需访问对应索引号的表项从而到达定位分支的目的。
3、到底使用哪一个选择语句,代码环境有关,如果是范围取值,则使用if else语句更为快捷;如果是确定取值,则使用switch是更优方案。
switch同时支持多条件匹配:
1
2
3
4
|
switch{
case 1,2:
default:
}
|
strconv.ParseBool() 源码查看
5.1.5、分支嵌套
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// 分支嵌套
var user string
var pwd int
fmt.Printf("请输入用户名:")
fmt.Scanln(&user)
fmt.Printf("请输入密码:")
fmt.Scanln(&pwd)
if user == "yuan" && pwd==123{
var score int
fmt.Printf("请输入成绩:")
fmt.Scanln(&score)
if score >= 90 && score<=100 {
fmt.Println("成绩优秀!")
} else if score >= 80 {
fmt.Println("成绩良好!")
} else if score >= 60 {
fmt.Println("成绩及格")
} else {
fmt.Println("不及格!")
}
}else {
fmt.Println("用户名或者密码错误!")
}
|
5.2、循环语句
在不少实际问题中有许多具有规律性的重复操作,因此在程序中就需要重复执行某些语句。一组被重复执行的语句称之为循环体,能否继续重复,决定循环的终止条件。
与其它主流编程语言不同的的是,Go语言中的循环语句只支持 for 关键字,而不支持 while 和 do-while 结构。
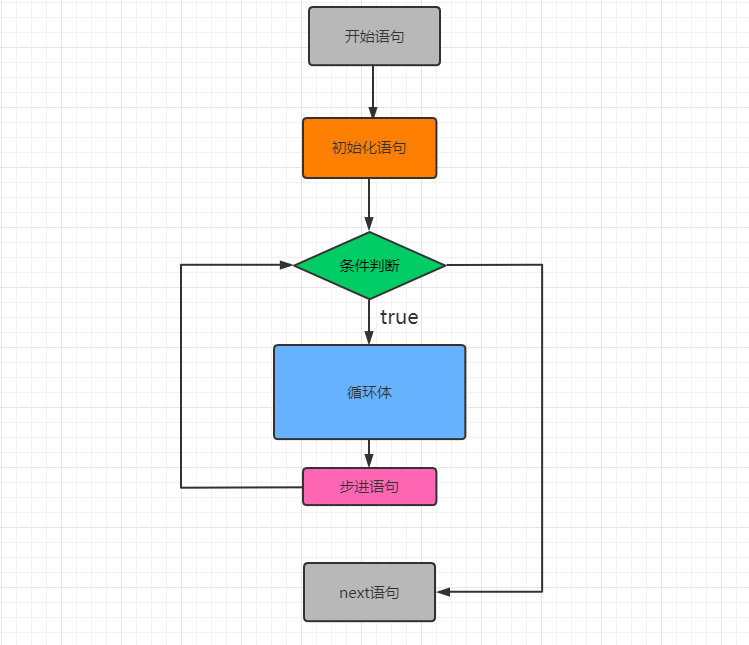
5.2.1、for循环
原始for循环
通过关系表达式或逻辑表达式控制循环
简单循环案例:
1
2
3
4
5
6
|
count := 0 // 初始化语句
for count < 10 { // 条件判断
fmt.Println("hello yuan!")
count++ // 步进语句
}
fmt.Println("end")
|
1
2
3
4
5
6
|
count := 10 // 初始化语句
for count > 0 { // 条件判断
fmt.Println(count)
count-- // 步进语句
}
fmt.Println("end")
|
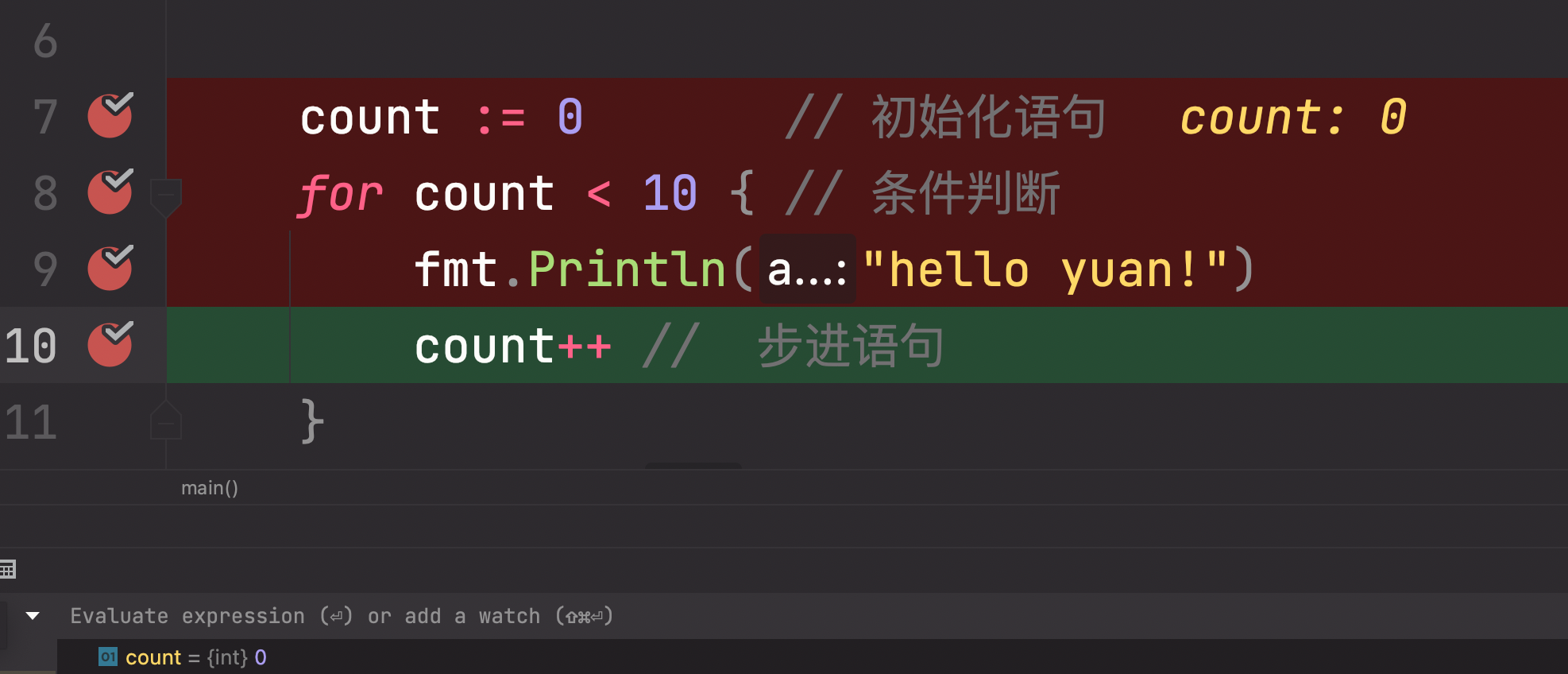
练习:如何打印1-100
三要素for循环(核心)
将初始化语句、条件判断以及步进语句格式固定化的循环方式,本质上和上面的for循环没有区别。
1
2
3
|
for init;condition;post {
// 循环体语句
}
|
-
init: 初始化语句,一般为赋值表达式,给控制变量赋初值;
-
condition:条件判断,一般是关系表达式或逻辑表达式,循环控制条件;
-
post: 步进语句,一般为赋值表达式,给控制变量增量或减量。
1
2
3
|
for i := 1; i < 10; i++ {
fmt.Println(i)
}
|
执行流程(关键):
(1)初始语句
(2)条件判断,布尔值为真则执行一次循环体,为假则退出循环
(3)执行一次循环体语句结束后,再执行步进语句,然后回到步骤(2),依次循环
案例1:计算1-100的和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
/* var s = 0
s += 1
s += 2
s += 3
s += 4
s += 5
s += 6
s += 7
s += 8
s += 9
s += 10
fmt.Println(s)*/
// 如果是1+2+3+....100呢?如何借助循环语法实现
var s = 0
for i := 1; i <= 100; i++ {
s += i
}
fmt.Println(s)
|
5.2.2、分支与循环的嵌套使用
循环与和分支语句是可以相互嵌套使用的,即分支语句中使用循环语句,循环语句中使用分支语句。
打印1-100中所有的偶数
1
2
3
4
5
|
for i := 1; i <= 100; i++ {
if i%2 == 0 {
fmt.Println(i)
}
}
|
无限循环案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
/*
无限循环
for true{}
*/
// 循环中嵌入分支语句
func main() {
fmt.Printf(`
1、普通攻击
2、超级攻击
3、使用道具
4、逃跑
`)
for true {
var choice int
fmt.Printf("请输入选择:")
fmt.Scanln(&choice)
//fmt.Println(choice,reflect.TypeOf(choice))
switch choice {
case 1:
fmt.Println("普通攻击")
case 2:
fmt.Println("超级攻击")
case 3:
fmt.Println("使用道具")
case 4:
fmt.Println("逃跑")
default:
fmt.Println("输入有误!")
}
}
}
|
输入正整数num,大于100,则打印1-num,小于100,则打印num-1?
1
2
3
4
5
6
7
8
9
10
11
12
|
var num int
fmt.Scanln(&num)
if num > 100 {
for i := 1; i <= num; i++ {
fmt.Println(i)
}
} else {
for i := num; i > 0; i-- {
fmt.Println(i)
}
}
|
5.2.3、退出循环
如果想提前结束循环(在不满足结束条件的情况下结束循环),可以使用break或continue关键字。
- break 用来跳出整个循环语句,也就是跳出所有的循环次数;
- continue 用来跳出当次循环,也就是跳过当前的一次循环。
break语句
当 break 关键字用于 for 循环时,会终止循环而执行整个循环语句后面的代码。break 关键字通常和 if 语句一起使用,即满足某个条件时便跳出循环,继续执行循环语句下面的代码。
1
2
3
4
5
6
|
for i := 0; i < 10; i++ {
if i==8{
break
}
fmt.Println(":",i)
}
|

continue语句
break 语句使得循环语句还没有完全执行完就提前结束,与之相反,continue 语句并不终止当前的循环语句的执行,仅仅是终止当前循环变量 i 所控制的这一次循环,而继续执行该循环语句。continue 语句的实际含义是“忽略 continue 之后的所有循环体语句,回到循环的顶部并开始下一次循环”
1
2
3
4
5
6
|
for i := 0; i < 10; i++ {
if i==8{
continue
}
fmt.Println(":",i)
}
|

案例: 计算 1 - 2 + 3 - 4 + … + 99 中除了88以外所有数的总和?
5.2.4、循环嵌套
在一个循环体语句中又包含另一个循环语句,称为循环嵌套
独立嵌套
在控制台上打印一个五行五列的矩形,如下图所示
1
2
3
4
5
|
*****
*****
*****
*****
*****
|
1
2
3
4
5
6
7
|
for i := 0; i < 5; i++ {
for j:=0;j<5;j++ {
fmt.Print("*")
}
fmt.Print("\n")
}
|
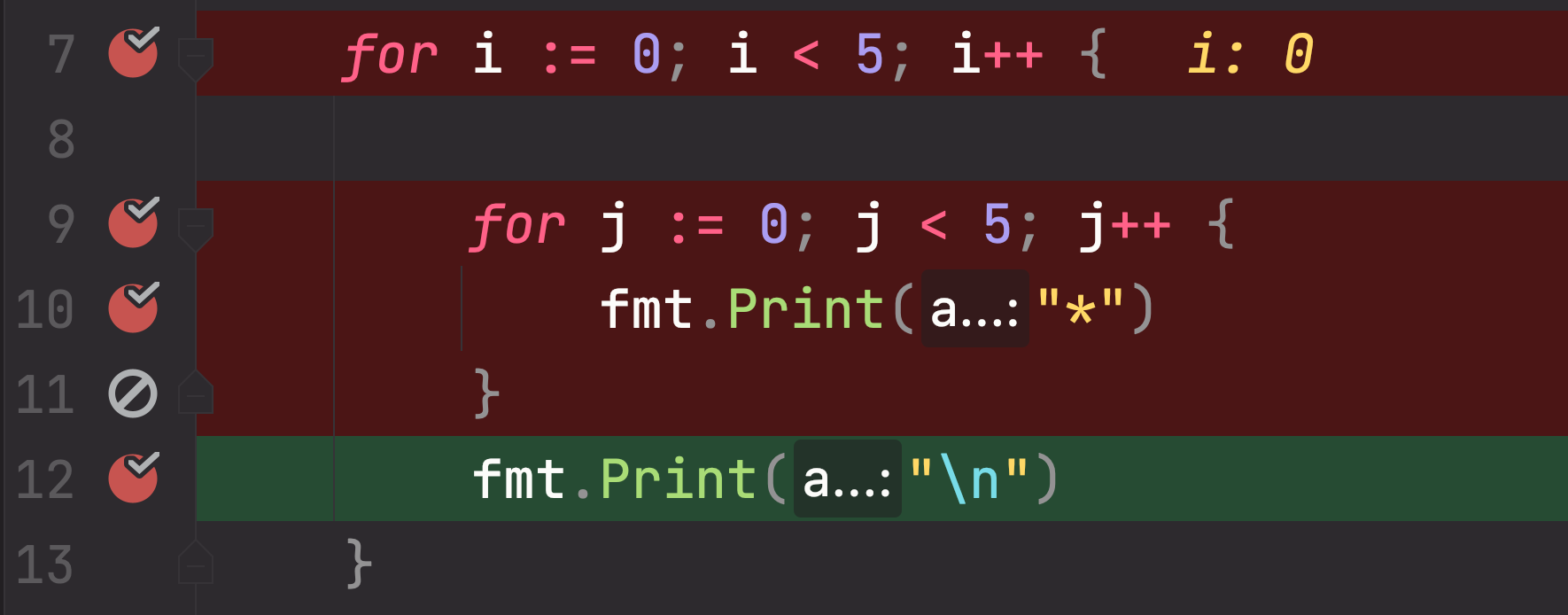
关联嵌套
在控制台上打印一个如下图所示的三角形
*
**
***
****
*****
1
2
3
4
5
6
|
for i := 0; i < 5; i++ {
for j := 0; j <= i; j++ {
fmt.Printf("*")
}
fmt.Println()
}
|
六、重要数据类型
6.1、指针类型(核心类型)
6.1.1、指针的基本使用
计算机中所有的数据都必须放在内存中,不同类型的数据占用的字节数不一样,例如 int 占用 4 个字节。为了正确地访问这些数据,必须为每个字节都编上号码,就像门牌号、身份证号一样,每个字节的编号是唯一的,根据编号可以准确地找到某个字节。
我们将内存中字节的编号称为地址(Address)或指针(Pointer)。地址从 0 开始依次增加,对于 32 位环境,程序能够使用的内存为 4GB,最小的地址为 0,最大的地址为 0XFFFFFFFF。
数据在内存中的地址也称为指针,如果一个变量存储了一份数据的指针,我们就称它为指针变量。
Go语言中使用对于指针存在两种操作: 取址和取值。
| 符号 |
名称 |
作用 |
| &变量 |
取址符 |
返回变量所在的地址 |
| *指针变量 |
取值符 |
返回指针指地址存储的值 |
1
2
3
4
5
6
7
8
|
var x = 100
// 取址符:& 取值符:*
fmt.Println("x的地址:", &x)
// 将地址值赋值给的变量称为指针变量
var p *int
p = &x
fmt.Println("p的值:", p)
fmt.Println("p地址对应的值", *p)
|
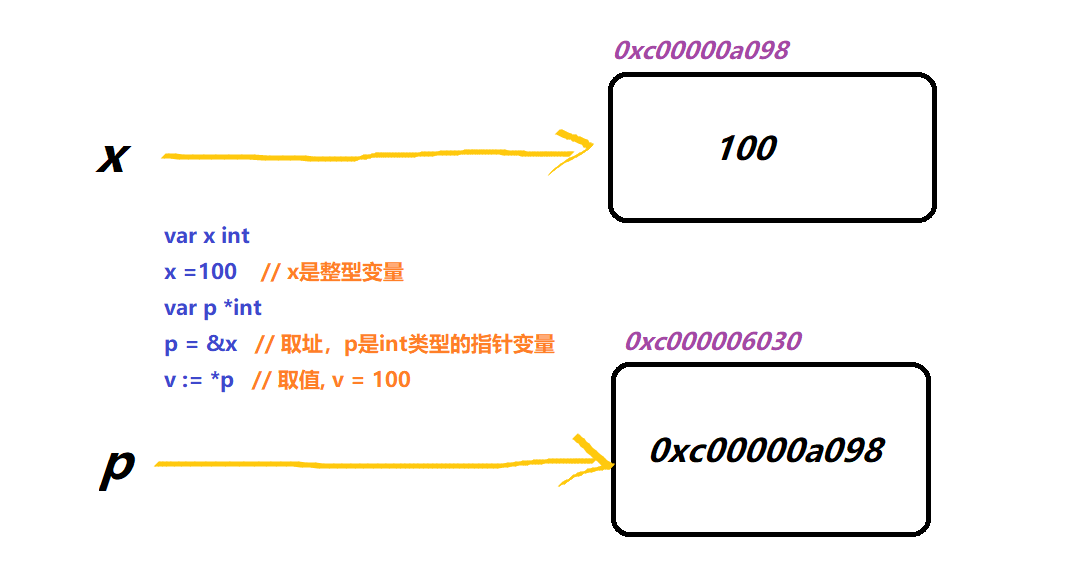
关于地址的格式化打印
1
2
3
4
5
|
var x = 10
fmt.Printf("%p\n", &x)
x = 100
fmt.Printf("%p\n", &x)
fmt.Println(*&x)
|
关于指针的应用:
1
2
3
4
5
6
7
8
9
|
// 当使用等号将一个变量的值赋给另一个变量时,如 x = y ,实际上是在内存中将 i 的值进行了拷贝
var x = 10
var y = x
var z = &x
x = 20
fmt.Println(y)
fmt.Println(*z)
*z = 30
fmt.Println(x)
|
练习1
1
2
3
4
5
6
7
|
var x = 10
var y = &x
var z = *y
x = 20
fmt.Println(x)
fmt.Println(*y)
fmt.Println(z)
|
练习2
1
2
3
4
5
|
var a = 100
var b = &a
var c = &b
**c = 200
fmt.Println(a)
|
- Go语言的指针类型变量即拥有指针高效访问的特点,又不会发生指针偏移和运算,从而避免了非法修改关键性数据的问题。
6.1.2、new函数
new 和 make 是 Go 语言中用于内存分配的原语。简单来说,new 只分配内存,make 用于初始化 slice、map 和 channel。
之前我们学习的基本数据类型声明之后是有一个默认零值的,但是指针类型呢?
1
2
3
4
|
var p *int
// fmt.Println(p) // <nil>
// fmt.Println(*p) // 报错,并没有开辟空间地址
*p = 10. // 报错
|
我们可以看到初始化⼀个指针变量,其值为nil,nil的值是不能直接赋值的。通过内建的new函数返回⼀个指向新分配的类型为int的指针,指针值为0xc00004c088,这个指针指向的内容的值为零(zero value)。
1
2
3
4
5
|
var p *int = new(int)
fmt.Println(p) // 0x14000122008
fmt.Println(*p) // 0
*p = 10
fmt.Println(*p) // 10
|
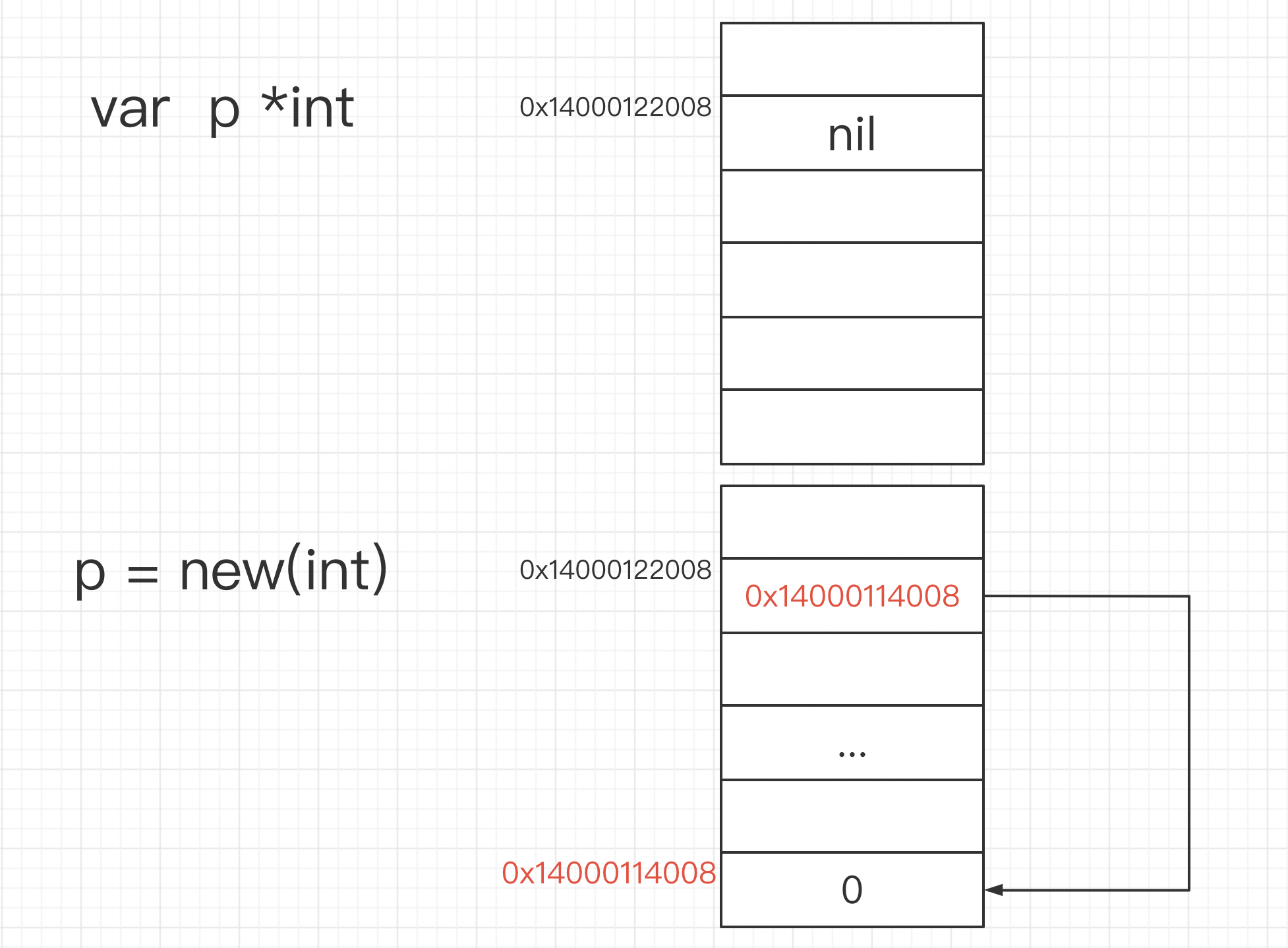
make返回的还是引⽤类型本⾝;⽽new返回的是指向类型的指针。后面再详细介绍
6.2、数组
我们之前学习过变量,当存储一个学生名字时可以name="yuan",但是如果班级有三十人,每个人的名字都想存储到内存中怎么办呢?总不能用三十个变量分别存储吧,这时数组就可以发挥作用了。
数组其实是和字符串一样的序列类型,不同于字符串在内存中连续存储字符,数组用[]的语法将同一类型的多个值存储在一块连续内存中。
6.2.1、声明数组
1
2
3
4
5
|
var names [5]string
fmt.Println(names,reflect.TypeOf(names)) // [ ] [5]string
var ages [5]int
fmt.Println(ages,reflect.TypeOf(ages)) // [0 0 0 0 0] [5]int
|
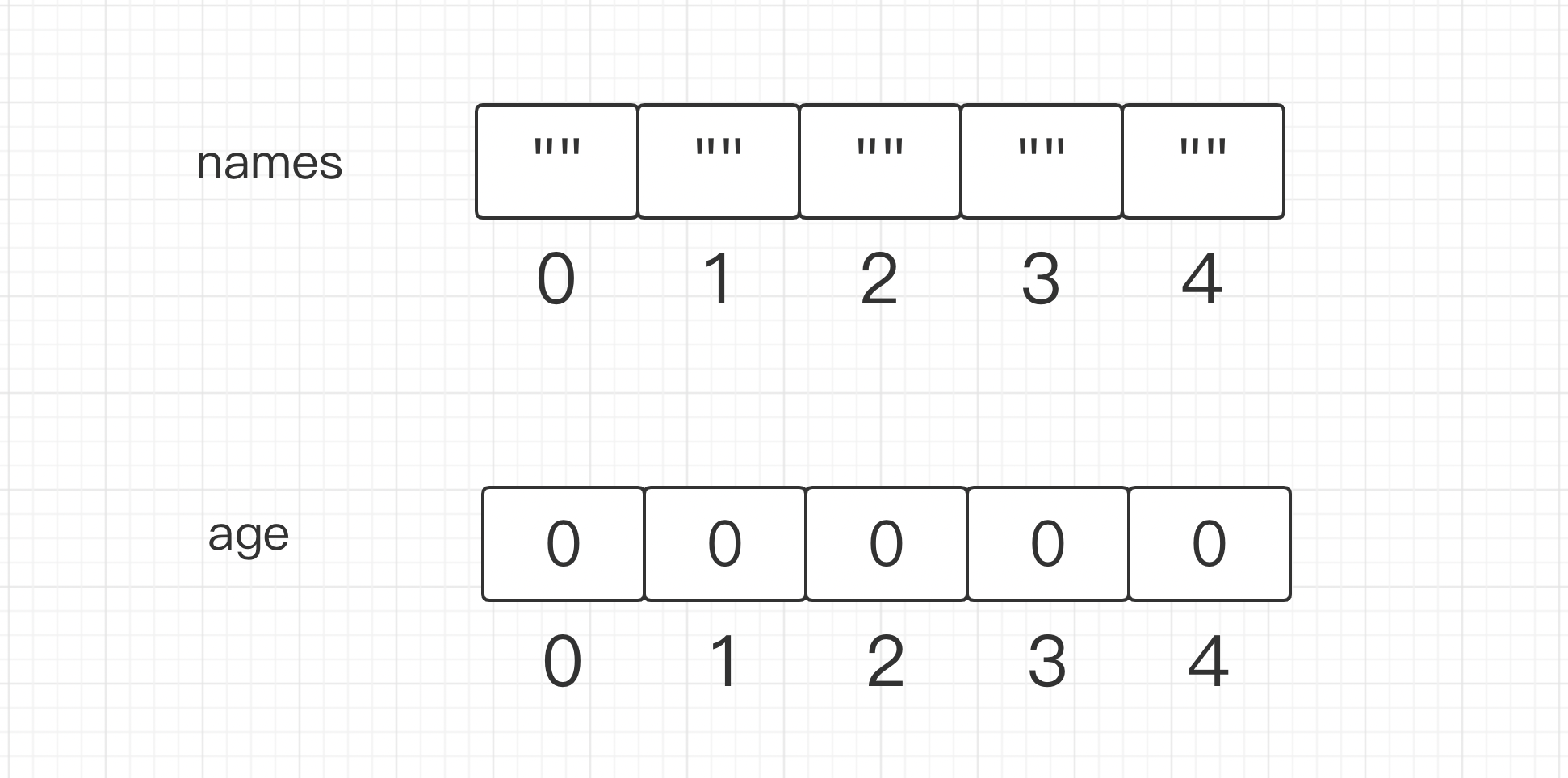
在计算机语言中数组是非常重要的集合类型,大部分计算机语言中数组具有如下三个基本特性:
- 一致性:数组只能保存相同数据类型元素,元素的数据类型可以是任何相同的数据类型。
- 有序性:数组中的元素是有序的,通过下标访问。
- 不可变性:数组一旦初始化,则长度(数组中元素的个数)不可变。
1
2
3
4
|
var x [3]int
var y [5]int
// x y的数据类型相同吗?
|
6.2.2、数组初始化
初始化方式1:先声明再赋值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
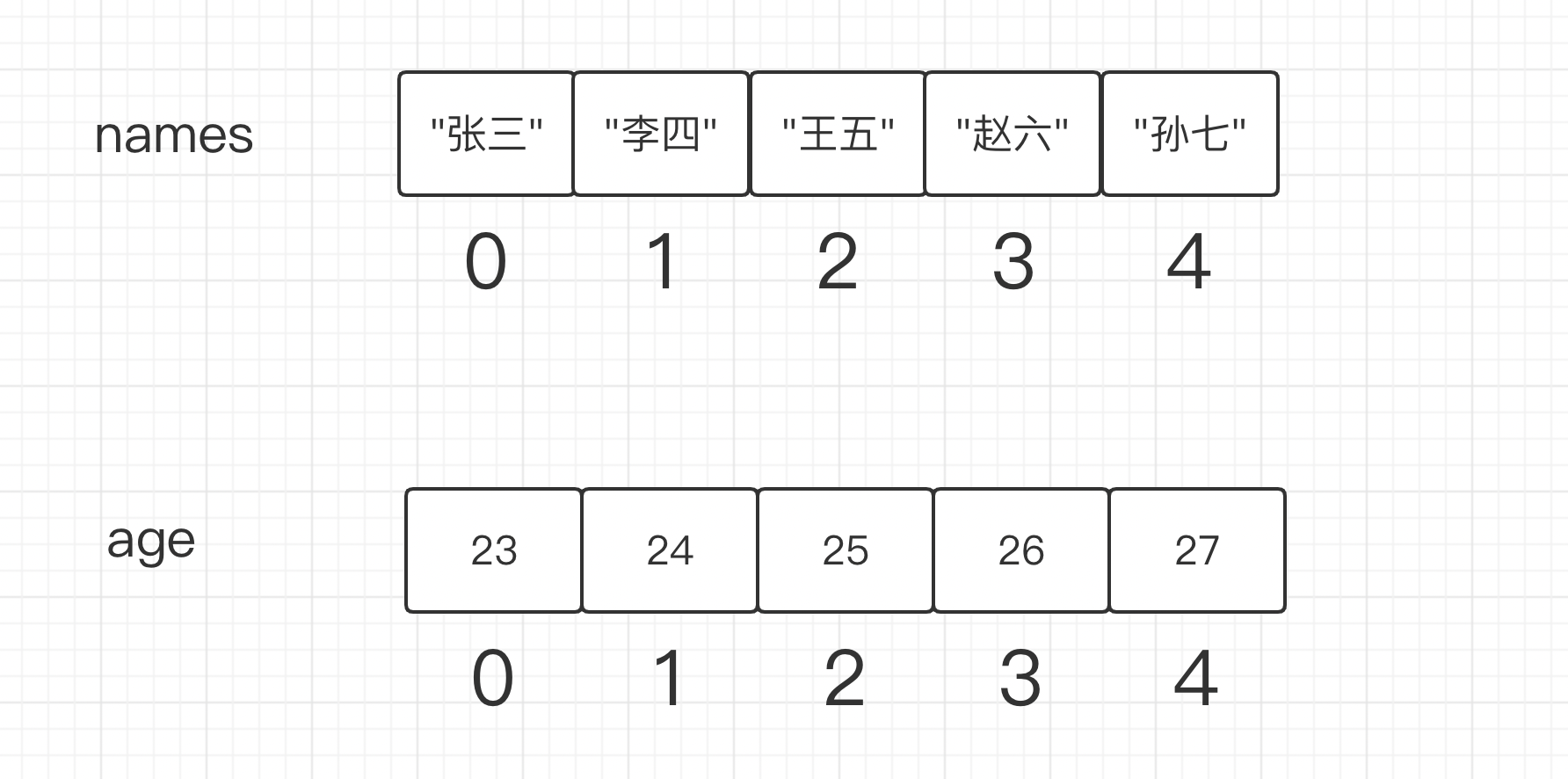
var names [5]string
var ages [5]int
names[0] = "张三"
names[1] = "李四"
names[2] = "王五"
names[3] = "赵六"
names[4] = "孙七"
fmt.Println(names) // [张三 李四 王五 赵六 孙七]
ages[0] = 23
ages[1] = 24
ages[2] = 25
ages[3] = 26
ages[4] = 27
fmt.Println(ages) // [23 24 25 26 27]
|
初始化方式2:声明并赋值
1
2
3
4
|
var names = [3]string{"张三","李四","王五"}
var ages = [3]int{23,24,25}
fmt.Println(names) // [张三 李四 王五]
fmt.Println(ages) // [23 24 25]
|
初始化方式3: […]不限长度
1
2
3
4
|
var names = [...]string{"张三","李四","王五"}
var ages = [...]int{23,24,25}
fmt.Println(names,reflect.TypeOf(names)) // [张三 李四 王五] [3]string
fmt.Println(ages,reflect.TypeOf(ages)) // [23 24 25] [3]int
|
初始化方式4:索引设置
1
2
|
var names = [...]string{0:"张三",2:"王五"}
fmt.Println(names) // [张三 王五]
|
6.2.3、基于索引访问和修改数组元素
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
var names = [...]string{"张三","李四","王五","赵六","孙七"}
// 索引取值
fmt.Println(names[2])
// 修改元素值
names[0] = "zhangsan"
fmt.Println(names)
// 切片取值
fmt.Println(names[0:4])
fmt.Println(names[0:])
fmt.Println(names[:3])
// 循环取值
for i:=0;i<len(names);i++{
fmt.Println(i,names[i])
}
for k,v := range names{ // range 表达式是副本参与循环
fmt.Println(k,v)
}
|
6.3、切片(slice)
切片是一个动态数组,因为数组的长度是固定的,所以操作起来很不方便,比如一个names数组,我想增加一个学生姓名都没有办法,十分不灵活。所以在开发中数组并不常用,切片类型才是大量使用的。
6.3.1、切片基本操作
切片的创建有两种方式:
- 从数组或者切片上切取获得
- 直接声明切片 :
var name []Type // 不同于数组, []没有数字
切片语法:
1
|
arr [start : end] 或者 slice [start : end] // start: 开始索引 end:结束索引
|
切片特点:
- 左闭右开 [ )
- 取出的元素数量为:结束位置 - 开始位置;
- 取出元素不包含结束位置对应的索引,切片最后一个元素使用
slice[len(slice)] 获取;
- 当缺省开始位置时,表示从连续区域开头到结束位置;当缺省结束位置时,表示从开始位置到整个连续区域末尾;两者同时缺省时,与切片本身等效;
1
2
3
4
5
6
|
var arr = [5]int{10, 11, 12, 13, 14}
var s1 = arr[1:4]
fmt.Println(s1, reflect.TypeOf(s1)) // [11 12 13] []int
var s2 = arr[2:5]
fmt.Println(s2, reflect.TypeOf(s2)) // [12 13 14]
var s3 = s2[0:2] // [12 13]
|
思考:
1
2
|
s3[0] = 1000
fmt.Println(":::", s1, s2, s3)
|
6.3.2、值类型和引用类型
数据类型从存储方式分为两类:值类型和引用类型!
(1) 值类型
基本数据类型(int,float,bool,string)以及数组和struct都属于值类型。
特点:变量直接存储值,内存通常在栈中分配,栈在函数调用完会被释放。值类型变量声明后,不管是否已经赋值,编译器为其分配内存,此时该值存储于栈上。
1
2
3
4
|
var a int //int类型默认值为 0
var b string //string类型默认值为 nil空
var c bool //bool类型默认值为false
var d [2]int //数组默认值为[0 0]
|
当使用等号=将一个变量的值赋给另一个变量时,如 j = i ,实际上是在内存中将 i 的值进行了拷贝,可以通过 &i 获取变量 i 的内存地址。此时如果修改某个变量的值,不会影响另一个。
1
2
3
4
5
6
7
8
9
10
11
12
|
// 整型赋值
var a =10
b := a
b = 101
fmt.Printf("a:%v,a的内存地址是%p\n",a,&a)
fmt.Printf("b:%v,b的内存地址是%p\n",b,&b)
//数组赋值
var c =[3]int{1,2,3}
d := c
d[1] = 100
fmt.Printf("c:%v,c的内存地址是%p\n",c,&c)
fmt.Printf("d:%v,d的内存地址是%p\n",d,&d)
|
(2) 引用类型
指针、slice,map,chan,interface等都是引用类型。
特点:变量通过存储一个地址来存储最终的值。内存通常在堆上分配,通过GC回收。
引用类型必须申请内存才可以使用,new()和make()是给引用类型申请内存空间。
6.3.3、切片原理
切片的构造根本是对一个具体数组通过切片起始指针,切片长度以及最大容量三个参数确定下来的
1
2
3
4
5
|
type Slice struct {
Data uintptr // 指针,指向底层数组中切片指定的开始位置
Len int // 长度,即切片的长度
Cap int // 最大长度(容量),也就是切片开始位置到数组的最后位置的长度
}
|

举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
var arr = [5]int{10, 11, 12, 13, 14}
s1 := arr[0:3] // 对数组切片
s2 := arr[2:5]
s3 := s2[0:2] // 对切片切片
fmt.Println(s1) // [10, 11, 12]
fmt.Println(s2) // [12, 13, 14]
fmt.Println(s3) // [12, 13]
// 地址是连续的
fmt.Printf("%p\n", &arr)
fmt.Printf("%p\n", &arr[0]) // 相差8个字节
fmt.Printf("%p\n", &arr[1])
fmt.Printf("%p\n", &arr[2])
fmt.Printf("%p\n", &arr[3])
fmt.Printf("%p\n", &arr[4])
// 每一个切片都有一块自己的空间地址,分别存储了对于数组的引用地址,长度和容量
fmt.Printf("%p\n", &s1) // s1自己的地址
fmt.Printf("%p\n", &s1[0])
fmt.Println(len(s1), cap(s1))
fmt.Printf("%p\n", &s2) // s2自己的地址
fmt.Printf("%p\n", &s2[0])
fmt.Println(len(s2), cap(s2))
fmt.Printf("%p\n", &s3) // s3自己的地址
fmt.Printf("%p\n", &s3[0])
fmt.Println(len(s3), cap(s3))
|
练习题:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
var a = [...]int{1, 2, 3, 4, 5, 6}
a1 := a[0:3]
a2 := a[0:5]
a3 := a[1:5]
a4 := a[1:]
a5 := a[:]
a6 := a3[1:2]
fmt.Printf("a1的长度%d,容量%d\n", len(a1), cap(a1))
fmt.Printf("a2的长度%d,容量%d\n", len(a2), cap(a2))
fmt.Printf("a3的长度%d,容量%d\n", len(a3), cap(a3))
fmt.Printf("a4的长度%d,容量%d\n", len(a4), cap(a4))
fmt.Printf("a5的长度%d,容量%d\n", len(a5), cap(a5))
fmt.Printf("a6的长度%d,容量%d\n", len(a6), cap(a6))
|
除了可以从原有的数组或者切片中生成切片外,也可以声明一个新的切片,每一种类型都可以拥有其切片类型,表示多个相同类型元素的连续集合,因此切片类型也可以被声明,切片类型声明格式如下:
1
|
var name []Type // []Type是切片类型的标识
|
其中 name 表示切片的变量名,Type 表示切片对应的元素类型。
1
2
|
var names = []string{"张三","李四","王五"}
fmt.Println(names,reflect.TypeOf(names)) // [张三 李四 王五 赵六 孙七] []string
|
直接声明切片,会针对切片构建底层数组,然后切片形成对数组的引用
练习1
1
2
3
4
|
s1 := []int{1, 2, 3}
s2 := s1[1:]
s2[1] = 4
fmt.Println(s1)
|
练习2
1
2
3
4
|
var a = []int{1, 2, 3}
b := a
a[0] = 100
fmt.Println(b)
|
6.3.4、make函数
变量的声明我们可以通过var关键字,然后就可以在程序中使用。当我们不指定变量的默认值时,这些变量的默认值是他们的零值,比如int类型的零值是0,string类型的零值是"",引用类型的零值是nil。
对于例子中的两种类型的声明,我们可以直接使用,对其进行赋值输出。但是如果我们换成引用类型呢?
1
2
3
4
|
// arr := []int{}
var arr [] int // 如果是 var arr [2] int
arr[0] = 1
fmt.Println(arr)
|
从这个提示中可以看出,对于引用类型的变量,我们不光要声明它,还要为它分配内容空间。
对于值类型的声明不需要,是因为已经默认帮我们分配好了。要分配内存,就引出来今天的make函数。make也是用于chan、map以及切片的内存创建,而且它返回的类型就是这三个类型本身。
如果需要动态地创建一个切片,可以使用 make() 内建函数,格式如下:
1
|
make([]Type, size, cap)
|
其中 Type 是指切片的元素类型,size 指的是为这个类型分配多少个元素,cap 为预分配的元素数量,这个值设定后不影响 size,只是能提前分配空间,降低多次分配空间造成的性能问题。 示例如下:
1
2
3
4
5
|
a := make([]int, 2)
b := make([]int, 2, 10)
fmt.Println(a, b)
fmt.Println(len(a), len(b))
fmt.Println(cap(a), cap(b))
|
使用 make() 函数生成的切片一定发生了内存分配操作,但给定开始与结束位置(包括切片复位)的切片只是将新的切片结构指向已经分配好的内存区域,设定开始与结束位置,不会发生内存分配操作。
1
2
3
4
5
|
a := make([]int, 5)
b := a[0:3]
a[0] = 100
fmt.Println(a)
fmt.Println(b)
|
6.3.5、append(重点)
上面我们已经讲过,切片作为一个动态数组是可以添加元素的,添加方式为内建方法append。
(1)append的基本用法
1
2
3
4
5
6
7
8
9
10
11
12
|
var emps = make([]string, 3, 5)
emps[0] = "张三"
emps[1] = "李四"
emps[2] = "王五"
fmt.Println(emps)
emps2 := append(emps, "rain")
fmt.Println(emps2)
emps3 := append(emps2, "eric")
fmt.Println(emps3)
// 容量不够时发生二倍扩容
emps4 := append(emps3, "yuan")
fmt.Println(emps4) // 此时底层数组已经发生变化
|

扩容机制
1、每次 append 操作都会检查 slice 是否有足够的容量,如果足够会直接在原始数组上追加元素并返回一个新的 slice,底层数组不变,但是这种情况非常危险,极度容易产生 bug!而若容量不够,会创建一个新的容量足够的底层数组,先将之前数组的元素复制过来,再将新元素追加到后面,然后返回新的 slice,底层数组改变而这里对新数组的进行扩容
2、扩容策略:如果切片的容量小于 1024 个元素,于是扩容的时候就翻倍增加容量。上面那个例子也验证了这一情况,总容量从原来的4个翻倍到现在的8个。一旦元素个数超过 1024 个元素,那么增长因子就变成 1.25 ,即每次增加原来容量的四分之一。
经典面试题
1
2
3
4
5
6
7
8
9
|
arr := [4]int{10, 20, 30, 40}
s1 := arr[0:2] // [10, 20]
s2 := s1 // // [10, 20]
s3 := append(append(append(s1, 1), 2), 3)
s1[0] = 1000
fmt.Println(s1)
fmt.Println(s2)
fmt.Println(s3)
fmt.Println(arr)
|
(2)append的扩展用法
1
2
3
4
5
6
7
|
var a []int
a = append(a, 1) // 追加1个元素
fmt.Println(a)
a = append(a, 1, 2, 3) // 追加多个元素, 手写解包方式
fmt.Println(a)
a = append(a, []int{1, 2, 3}...) // 追加一个切片, 切片需要解包
fmt.Println(a)
|
a = append(a, 1)返回切片又重新赋值a的目的是丢弃老数组
经典练习:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
// 案例1
a := []int{11, 22, 33}
fmt.Println(len(a), cap(a))
c := append(a, 44)
a[0] = 100
fmt.Println(a)
fmt.Println(c)
// 案例2
a := make([]int, 3, 10)
fmt.Println(a)
b := append(a, 11, 22)
fmt.Println(a) // 小心a等于多少?
fmt.Println(b)
a[0] = 100
fmt.Println(a)
fmt.Println(b)
// 案例3
l := make([]int, 5, 10)
v1 := append(l, 1)
fmt.Println(v1)
fmt.Printf("%p\n", &v1)
v2 := append(l, 2)
fmt.Println(v2)
fmt.Printf("%p\n", &v2)
fmt.Println(v1)
|
6.2.6、切片的插入和删除
开头添加元素
1
2
3
|
var a = []int{1,2,3}
a = append([]int{0}, a...) // 在开头添加1个元素
a = append([]int{-3,-2,-1}, a...) // 在开头添加1个切片
|
在切片开头添加元素一般都会导致内存的重新分配,而且会导致已有元素全部被复制 1 次,因此,从切片的开头添加元素的性能要比从尾部追加元素的性能差很多。
任意位置插入元素
1
2
3
|
var a []int
a = append(a[:i], append([]int{x}, a[i:]...)...) // 在第i个位置插入x
a = append(a[:i], append([]int{1,2,3}, a[i:]...)...) // 在第i个位置插入切片
|
每个添加操作中的第二个 append 调用都会创建一个临时切片,并将 a[i:] 的内容复制到新创建的切片中,然后将临时创建的切片再追加到 a[:i] 中。
思考这样写可以不:
1
2
3
4
|
var a = []int{1,2,3,4}
s1:=a[:2]
s2:=a[2:]
fmt.Println(append(append(s1,100,),s2...))
|
删除元素
Go语言中并没有删除切片元素的专用方法,我们可以使用切片本身的特性来删除元素。
1
2
3
4
5
|
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
|
要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
思考题:
1
2
3
4
5
|
a:=[...]int{1,2,3}
b:=a[:]
b =append(b[:1],b[2:]...)
fmt.Println(a)
fmt.Println(b)
|
6.2.7、切片元素排序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
a:=[]int{10,2,3,100}
sort.Ints(a)
fmt.Println(a) // [2 3 10 100]
b:=[]string{"melon","banana","caomei","apple"}
sort.Strings(b)
fmt.Println(b) // [apple banana caomei melon]
c:=[]float64{3.14,5.25,1.12,4,78}
sort.Float64s(c)
fmt.Println(c) // [1.12 3.14 4 5.25 78]
// 注意:如果是一个数组,需要先转成切片再排序 [:]
sort.Sort(sort.Reverse(sort.IntSlice(a)))
sort.Sort(sort.Reverse(sort.Float64Slice(c)))
fmt.Println(a,c)
|
6.2.8、切片拷贝
1
2
3
4
5
6
7
8
9
|
var s1 = []int{1, 2, 3, 4, 5}
var s2 = make([]int, len(s1))
copy(s2, s1)
fmt.Println(s2)
s3 := []int{4, 5}
s4 := []int{6, 7, 8, 9}
copy(s4, s3)
fmt.Println(s4) //[4 5 3]
|
6.3、map(映射)类型
通过切片,我们可以动态灵活存储管理学生姓名、年龄等信息,比如
1
2
3
4
|
names := []string{"张三","李四","王五"}
ages := []int{23,24,25}
fmt.Println(names)
fmt.Println(ages)
|
但是如果我想获取张三的年龄,这是一个再简单不过的需求,但是却非常麻烦,我们需要先获取张三的切片索引,再去ages切片中对应索引取出,前提还得是姓名年龄按索引对应存储。
所以在编程语言中大都会存在一种映射(key-value)类型,在JS中叫json对象类型,在python中叫字典(dict)类型,而在Go语言中则叫Map类型。
- Map是一种通过key来获取value的一个数据结构,其底层存储方式为数组,在存储时key不能重复,当key重复时,value进行覆盖,我们通过key进行hash运算(可以简单理解为把key转化为一个整形数字)然后对数组的长度取余,得到key存储在数组的哪个下标位置,最后将key和value组装为一个结构体,放入数组下标处
- slice查询是遍历方式,时间复杂度是O(n), map查询是hash映射 ;当数据量小的时候切片查询比map快,但是数据量大的时候map的优势就体现出来了
6.3.1、map的声明和初始化
不同于切片根据索引查找值,map类型是根据key查找值。
map 是引用类型,声明语法:
1
|
var map_name map[key_type]value_type
|
其中:
map_name 为 map 的变量名。key_type为键类型。value_type是键对应的值类型。
1
2
|
var info map[string]string
fmt.Println(info) // map[]
|
(1) 先声明再赋值
1
2
3
4
5
|
// var info map[string]string // 没有默认空间
info := make(map[string]string)
info["name"] = "yuan"
info["age"] = "23"
fmt.Println(info) // map[age:23 name:yuan]
|
- map的键是无序的
- map的键不能重复
(2) 直接声明赋值
1
2
|
info := map[string]string{"name": "yuan", "age": "23","gender":"male"}
fmt.Println(info) // map[age:18 gender:male name:yuan]
|
6.3.2、map的增删改查
(1) 查
1
2
3
4
5
6
7
8
9
10
|
info := map[string]string{"name": "yuan", "age": "18","gender":"male"}
val:= info["name"]
val,is_exist:= info["name"] // 判断某个键是否存在map数据中
if is_exist{
fmt.Println(val)
fmt.Println(is_exist)
}else {
fmt.Println("键不存在!")
}
|
1
2
3
|
for k,v :=range info{
fmt.Println(k,v)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
|
noSortMap := map[int]int{
1: 1,
2: 2,
3: 3,
4: 4,
5: 5,
6: 6,
}
for k, v := range noSortMap { // for range顺序随机
fmt.Println(k, v)
}
|
(2)添加和更新
1
2
3
4
|
info := map[string]string{"name": "yuan", "age": "18","gender":"male"}
info["height"] = "180cm" // 键不存在,则是添加键值对
info["age"] = "22" // 键存在,则是更新键的值
fmt.Println(info) // map[age:22 gender:male height:180cm name:yuan]
|
(3)删除键值对
一个内置函数 delete(),用于删除容器内的元素
1
2
3
|
info := map[string]string{"name": "yuan", "age": "18","gender":"male"}
delete(info,"gender")
fmt.Println(info)
|
如果想清空一个map,最优方式即创建一个新的map!
6.3.3、map 容量
和数组不同,map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity,格式如下:
1
|
make(map[keytype]valuetype, cap)
|
例如:
1
|
m := make(map[string]float, 100)
|
当 map 增长到容量上限的时候,如果再增加新的 key-value,map 的大小会自动加 1,所以出于性能的考虑,对于大的 map 或者会快速扩张的 map,即使只是大概知道容量,也最好先标明。
6.3.4、map的灵活运用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// 案例1
data := map[string][]string{"hebei": []string{"廊坊市", "石家庄", "邯郸"}, "beijing": []string{"朝阳", "丰台", "海淀"}}
// 打印河北的第二个城市
// 循环打印每个省份的名字和城市数量
// 添加一个新的省份和城市的key-value
// 删除北京的key-value
// 案例2
info := map[int]map[string]string{1001: {"name": "yuan", "age": "23"}, 1002: {"name": "alvin", "age": "33"}}
// 打印学号为1002的学生的年龄
// 循环打印每个学员的学号,姓名,年龄
// 添加一个新的学员
// 删除1001的学生
// 案例3
stus := []map[string]string{{"name": "yuan", "age": "23"}, {"name": "rain", "age": "22"}, {"age": "32", "name": "eric"}}
// 打印第二个学生的姓名
// 循环打印每一个学生的姓名和年龄
// 添加一个新的学生map
// 删除一个学生map
// 将姓名为rain的学生的年龄自加一岁
|
6.3.5、练习
1
2
3
|
// 根据age的大小重新排序
stus := []map[string]int{map[string]int{"age": 23}, map[string]int{"age": 33}, map[string]int{"age": 18}}
fmt.Println(stus)
|
6.3.6、map的底层原理
(1)摘要算法
“消息摘要”(Message Digest)是一种能产生特殊输出格式的算法,这种加密算法的特点是无论用户输入什么长度的原始数据,经过计算后输出的密文都是固定长度的,这种算法的原理是根据一定的运算规则对原数据进行某种形式的提取,这种提取就是“摘要”,被“摘要”的数据内容与原数据有密切联系,只要原数据稍有改变,输出的“摘要”便完全不同,因此基于这种原理的算法便能对数据完整性提供较为健全的保障。但是,由于输出的密文是提取原数据经过处理的定长值,所以它已经不能还原为原数据,即消息摘要算法是**“不可逆”**的,理论上无法通过反向运算取得原数据内容,因此它通常只能被用来做数据完整性验证,而不能作为原数据内容的加密方案使用,否则谁也无法还原。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package main
import (
"crypto/md5"
"crypto/sha1"
"crypto/sha256"
"fmt"
"os"
)
func main() {
//输⼊字符串测试开始.
input := "k4"
//MD5算法.
hash := md5.New()
_, err := hash.Write([]byte(input))
if err != nil {
fmt.Println(err)
os.Exit(-1)
}
result := hash.Sum(nil)
//或者result := hash.Sum([]byte(""))
fmt.Printf("md5 hash算法长度为%d,结果:%x\n", len(result), result)
//SHA1算法.
hash = sha1.New()
_, err = hash.Write([]byte(input))
if err != nil {
fmt.Println(err)
os.Exit(-1)
}
result = hash.Sum(nil)
//或者result = hash.Sum([]byte(""))
fmt.Printf("sha1 hash算法长度为%d,结果:%x\n", len(result), result)
//SHA256算法.
hash = sha256.New()
_, err = hash.Write([]byte(input))
if err != nil {
fmt.Println(err)
os.Exit(-1)
}
result = hash.Sum(nil)
//或者result = hash.Sum([]byte(""))
fmt.Printf("sha256 hash算法长度为%d,结果:%x\n", len(result), result)
}
|
(2)map底层存储
哈希表属于编程中比较常见的数据结构之一,基本上所有的语言都会实现数组和哈希表这两种结构。
slice查询是遍历⽅式,时间复杂度是O(n)
map查询是hash映射,时间复杂度是O(1)
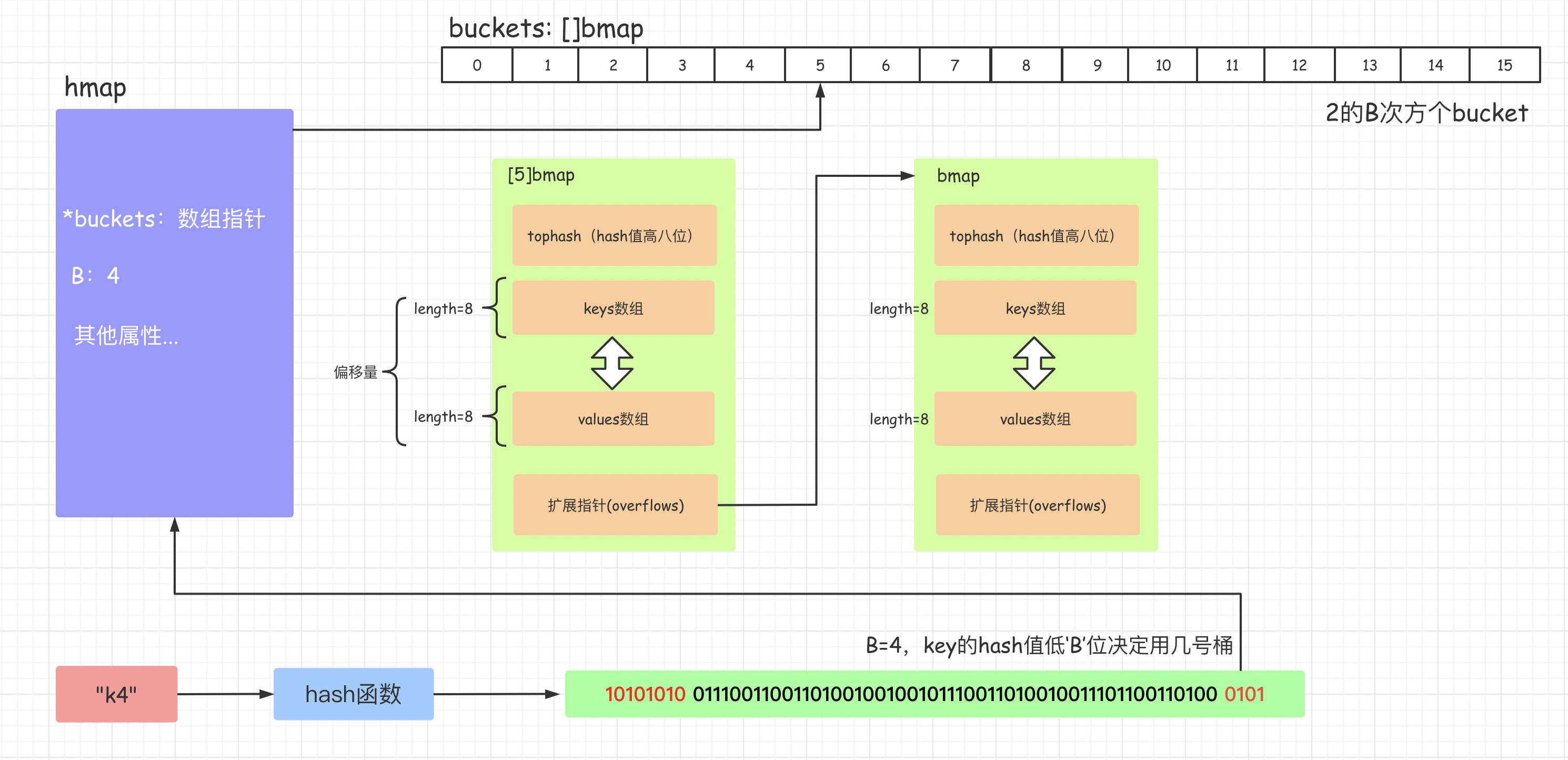
在go的map实现中,它的底层结构体是hmap,hmap⾥维护着若⼲个bucket数组 (即桶数组)。
Bucket数组中每个元素都是bmap结构,也即每个bucket(桶)都是bmap结构,【ps:后⽂为了语义⼀致,和⽅便理解,就不再提bmap 了,统⼀叫作桶】 每个桶中保存了8个kv对,如果8个满了,⼜来了⼀个key落在了这个桶⾥,会使⽤overflow连接下⼀个桶(溢出桶)。
map 的源码位于 src/runtime/map.go 文件中,结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
type hmap struct {
count int // 当前 map 中元素数量
flags uint8
B uint8 // 当前 buckets 数量,2^B 等于 buckets 个数
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // buckets 数组指针
oldbuckets unsafe.Pointer // 扩容时保存之前 buckets 数据。
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
|
| count |
键值对的数量 |
| B |
2^B=len(buckets) |
| hash0 |
hash因子 |
| buckets |
指向一个数组(连续内存空间),数组的类型为[]bmap,bmap类型就是存在键值对的结构下面会详细介绍,这个字段我们可以称之为正常桶。如下图所示 |
| oldbuckets |
扩容时,存放之前的buckets(Map扩容相关字段) |
| extra |
溢出桶结构,正常桶里面某个bmap存满了,会使用这里面的内存空间存放键值对 |
| noverflow |
溢出桶里bmap大致的数量 |
| nevacuate |
分流次数,成倍扩容分流操作计数的字段(Map扩容相关字段) |
| flags |
状态标识,比如正在被写、buckets和oldbuckets在被遍历、等量扩容(Map扩容相关字段) |
1
2
3
4
5
6
7
8
9
10
11
12
|
// 每一个 bucket 的结构,即 hmap 中 buckets 指向的数据。
type bmap struct {
tophash [bucketCnt]uint8
}
// 编译期间重构此结构
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
|
| topbits |
长度为8的数组,[]uint8,元素为:key获取的hash的高8位,遍历时对比使用,提高性能。如下图所示 |
| keys |
长度为8的数组,[]keytype,元素为:具体的key值。每个bucket可以存储8个键值对 |
| elems |
长度为8的数组,[]elemtype,元素为:键值对的key对应的值。 |
| overflow |
指向的hmap.extra.overflow溢出桶里的bmap,上面的字段topbits、keys、elems长度为8,最多存8组键值对,存满了就往指向的这个bmap里存 |
| pad |
对齐内存使用的,不是每个bmap都有会这个字段,需要满足一定条件 |
(1)插入key-value
map的赋值流程可总结位如下几步:
map的赋值流程可总结位如下⼏步:
<1> 通过key的hash值后“B”位确定是哪⼀个桶,图中⽰例为5号桶。
<2> 遍历当前桶,通过key的tophash和hash值,防⽌key重复。如果key已存在则直接更新值。如果没找到将key,将key插入到第⼀个可以插⼊的位置,即空位置处存储数据。
<3> 如果当前桶元素已满,会通过overflow链接创建⼀个新的桶,来存储数据。
(2)查询key-value
参考上图,k4的get流程可以归纳为如下⼏步:
<1> 计算k4的hash值。[由于当前主流机都是64位操作系统,所以计算结果有64个⽐特位]
<2> 通过最后的“B”位来确定在哪号桶,此时B为4,所以取k4对应哈希值的后4位,也就是0101,0101⽤⼗进制表⽰为5,所以在5号桶)
<3> 根据k4对应的hash值前8位快速确定是在这个桶的哪个位置(额外说明⼀下,在bmap中存放了每个key对应的tophash,是key的哈希值前8位),⼀旦发现前8位⼀致,则会执⾏下⼀步
<4> 对⽐key完整的hash是否匹配,如果匹配则获取对应value
<5> 如果都没有找到,就去连接的下⼀个溢出桶中找
有很多同学会问这⾥为什么要多维护⼀个tophash,即hash前8位?
这是因为tophash可以快速确定key是否正确,也可以把它理解成⼀种缓存措施,如果前8位都不对了,后⾯就没有必要⽐较了。
七、函数
设计一个程序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
/*
打印两个六层菱形
期待结果:
*
***
*****
*******
*********
***********
*********
*******
*****
***
*
*
***
*****
*******
*********
***********
*********
*******
*****
***
*
*/
|
如果没有函数,我们的实现方式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
|
// 打印菱形
// 层数
var n int = 6
for i := 1; i <= n; i++ {
for k := 1; k <= n-i; k++ {
fmt.Print(" ")
}
for j := 1; j <= 2*i-1; j++ {
fmt.Print("*")
}
fmt.Println()
}
for i := n - 1; i >= 1; i-- {
for k := 1; k <= n-i; k++ {
fmt.Print(" ")
}
for j := 1; j <= 2*i-1; j++ {
fmt.Print("*")
}
fmt.Println()
}
// 再次打印菱形
var n int = 6
for i := 1; i <= n; i++ {
for k := 1; k <= n-i; k++ {
fmt.Print(" ")
}
for j := 1; j <= 2*i-1; j++ {
fmt.Print("*")
}
fmt.Println()
}
for i := n - 1; i >= 1; i-- {
for k := 1; k <= n-i; k++ {
fmt.Print(" ")
}
for j := 1; j <= 2*i-1; j++ {
fmt.Print("*")
}
fmt.Println()
}
|
相信大家一定看出来了,这种方式会出现大量重复代码,对于阅读和维护整个程序都会变得十分麻烦。
这时候,函数就出现了!
简单说,函数就是一段封装好的,可以重复使用的代码,它使得我们的程序更加模块化,避免大量重复的代码。
刚才的程序函数版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
package main
import "fmt"
func printLing(){
// 打印菱形
var n int = 6
for i := 1; i <= n; i++ {
for k := 1; k <= n-i; k++ {
fmt.Print(" ")
}
for j := 1; j <= 2*i-1; j++ {
fmt.Print("*")
}
fmt.Println()
}
for i := n - 1; i >= 1; i-- {
for k := 1; k <= n-i; k++ {
fmt.Print(" ")
}
for j := 1; j <= 2*i-1; j++ {
fmt.Print("*")
}
fmt.Println()
}
}
func main() {
// 打印菱形
printLing()
// 打印菱形
printLing()
}
|
7.1、函数声明和调用
go语言是通过func关键字声明一个函数的,声明语法格式如下
1
2
3
4
|
func 函数名(形式参数) (返回值) {
函数体
return 返回值 // 函数终止语句
}
|
其中:
- 函数名:由字母、数字、下划线组成。但函数名的第一个字母不能是数字。在同一个包内,函数名也称不能重名(包的概念详见后文)。
- 形式参数:参数由参数变量和参数变量的类型组成,多个参数之间使用
,分隔。
- 返回值:返回值由返回值变量和其变量类型组成,也可以只写返回值的类型,多个返回值必须用
()包裹,并用,分隔。
- 函数体:实现指定功能的代码块。
1
2
3
4
5
6
7
8
9
|
func cal_sum100() {
// 计算1-100的和
var s = 0
for i := 1; i <= 100; i++ {
s += i
}
fmt.Println(s)
}
|
声明一个函数并不会执行函数内代码,只是完成一个一个包裹的作用。真正运行函数内的代码还需要对声明的函数进行调用,一个函数可以在任意位置多次调用。调用一次,即执行一次该函数内的代码。
调用语法:
案例:
1
2
3
4
5
6
7
8
9
|
func cal_sum100() {
// 计算1-100的和
var s = 0
for i := 1; i <= 100; i++ {
s += i
}
fmt.Println(s)
}
cal_sum100()
|
7.3、函数参数
7.3.1、什么是参数
什么是参数,函数为什么需要参数呢?将上面的打印的两个菱形换乘打印一个6行的和一个8行的,如何实现呢?这就涉及到了函数参数。
再比如上面我们将计算1-100的和通过函数实现了,但是完成新的需求:
分别计算并在终端打印1-100的和,1-150的和以及1-200的和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
package main
import "fmt"
func cal_sum100() {
// 计算1-100的和
var s = 0
for i := 1; i <= 100; i++ {
s += i
}
fmt.Println(s)
}
func cal_sum150() {
// 计算1-100的和
var s = 0
for i := 1; i <= 150; i++ {
s += i
}
fmt.Println(s)
}
func cal_sum200() {
// 计算1-100的和
var s = 0
for i := 1; i <= 200; i++ {
s += i
}
fmt.Println(s)
}
func main() {
cal_sum100()
cal_sum150()
cal_sum200()
}
|
这样当然可以实现,但是是不是依然有大量重复代码,一会发现三个函数出了一个变量值不同以外其他都是相同的,所以为了能够在函数调用的时候动态传入一些值给函数,就有了参数的概念。
参数从位置上区分分为形式参数和实际参数。
1
2
3
4
5
6
|
// 函数声明
func 函数名(形式参数1 参数1类型,形式参数2 参数2类型,...){
函数体
}
// 调用函数
函数名(实际参数1,实际参数2,...)
|
函数每次调用可以传入不同的实际参数,传参的过程其实就是变量赋值的过程,将实际参数按位置分别赋值给形参。
还是刚才的案例,用参数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
package main
import "fmt"
func cal_sum(n int) {
// 计算1-100的和
var s = 0
for i := 1; i <= n; i++ {
s += i
}
fmt.Println(s)
}
func main() {
cal_sum(100)
cal_sum(101)
cal_sum(200)
}
|
这样是不是就灵活很多了呢,所以基本上一个功能强大的函数都会有自己需要的参数,让整个业务实现更加灵活。
7.3.2、位置参数
位置参数,有时也称必备参数,指的是必须按照正确的顺序将实际参数传到函数中,换句话说,调用函数时传入实际参数的数量和位置都必须和定义函数时保持一致。
1
2
3
4
5
6
7
8
9
10
11
12
|
// 函数声明 两个形参:x,y
func add_cal(x int,y int){
fmt.Println(x+y)
}
func main() {
// 函数调用,按顺序传参
// add_cal(2) // 报错
// add_cal(232,123,12) // 报错
add_cal(100,12)
}
|
7.3.3、不定长参数
如果想要一个函数能接收任意多个参数,或者这个函数的参数个数你无法确认,就可以使用不定长参数,也叫可变长参数。Go语言中的可变参数通过在参数名后加...来标识。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
package main
import "fmt"
func sum(nums ...int) { //变参函数
fmt.Println("nums",nums)
total := 0
for _, num := range nums {
total += num
}
fmt.Println(total)
}
func main() {
sum(12,23)
sum(1,2,3,4)
}
|
注意:可变参数通常要作为函数的最后一个参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
package main
import "fmt"
func sum(base int, nums ...int) int {
fmt.Println(base, nums)
sum := base
for _, v := range nums {
sum = sum + v
}
return sum
}
func main() {
ret := sum(10,2,3,4)
fmt.Println(ret)
}
|
go的函数强调显示表达的设计哲学,没有默认参数
7.4、函数返回值
7.4.1、返回值的基本使用
函数的返回值是指函数被调用之后,执行函数体中的代码所得到的结果,这个结果通过 return 语句返回。return 语句将被调函数中的一个确定的值带回到主调函数中,供主调函数使用。函数的返回值类型是在定义函数时指定的。return 语句中表达式的类型应与定义函数时指定的返回值类型必须一致。
1
2
3
4
5
6
|
func 函数名(形参 形参类型)(返回值类型){
// 函数体
return 返回值
}
变量 = 函数(实参) // return 返回的值赋值给某个变量,程序就可以使用这个返回值了。
|
同样是设计一个加法计算函数:
1
2
3
4
5
6
7
8
|
func add_cal(x,y int) int{
return x+y
}
func main() {
ret := add_cal(1,2)
fmt.Println(ret)
}
|
7.4.2、无返回值
声明函数时没有定义返回值,函数调用的结果不能作为值使用
1
2
3
4
5
6
7
8
9
10
|
func foo(){
fmt.Printf("hi,yuan!")
return // 不写return默认return空
}
func main() {
// ret := foo() // 报错:无返回值不能将调用的结果作为值使用
foo()
}
|
7.4.3、返回多个值
函数可以返回多个值
1
2
3
4
5
6
7
8
|
func get_name_age() (string, int) {
return "yuan",18
}
func main() {
a, b := get_name_age()
fmt.Println(a, b)
}
|
7.4.4、返回值命名
函数定义时可以给返回值命名,并在函数体中直接使用这些变量,最后通过return关键字返回。
1
2
3
4
5
|
func calc(x, y int) (sum, sub int) {
sum = x + y
sub = x - y
return // return sum sub
}
|
7.5、作用域
所谓变量作用域,即变量可以作用的范围。
作用域(scope)通常来说,程序中的标识符并不是在任何位置都是有效可用的,而限定这个标识符的可用性的范围就是这个名字的作用域。
变量根据所在位置的不同可以划分为全局变量和局部变量
- 局部变量 :写在{}中或者函数中或者函数的形参, 都是局部变量
1、局部变量的作用域是从定义的那一行开始, 直到遇到 } 结束或者遇到return为止
2、局部变量, 只有执行了才会分配存储空间, 只要离开作用域就会自动释放
3、局部变量存储在栈区
4、局部变量如果没有使用, 编译会报错。全局变量如果没有使用, 编译不会报错
5、:=只能用于局部变量, 不能用于全局变量
1、全局变量的作用域是从定义的那一行开始, 直到文件末尾为止
2、全局变量, 只要程序一启动就会分配存储空间, 只有程序关闭才会释放存储空间,
3、全局变量存储在静态区(数据区)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func foo() {
// var x =10
x = 10
fmt.Println(x)
}
var x = 30 // 全局变量
func main() {
// var x = 20
foo()
fmt.Println(x)
}
|
注意,if,for语句具备独立开辟作用域的能力:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
// if的局部空间
if true{
x:=10
fmt.Println(x)
}
fmt.Println(x)
// for的局部空间
for i:=0;i<10 ;i++ {
}
fmt.Println(i)
|
7.6、值传递
7.6.1、赋值操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 案例1
var x = 10
fmt.Printf("x的地址%p\n", &x)
y := x
fmt.Printf("y的地址%p\n", &y)
x = 100
fmt.Println(y)
// 案例2
var a = []int{1, 2, 3}
b := a
a[0] = 100
fmt.Println(b)
// 案例3
var m1 = map[string]string{"name":"yuan"}
var m2 = m1
m2["age"] = "22"
fmt.Println(m1)
|
7.6.2、函数传参
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
package main
import "fmt"
func swap(a int, b int) {
c := a
a = b
b = c
fmt.Println("a", a)
fmt.Println("b", b)
}
func main() {
var x = 10
var y = 20
swap(x, y)
fmt.Println("x", x)
fmt.Println("y", y)
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
package main
import "fmt"
func func01(x int) {
x = 100
}
func func02(s []int) {
fmt.Printf("func02的s的地址:%p\n",&s)
s[0] = 100
// s = append(s, 1000)
}
func func03(p *int) {
*p = 100
}
func main() {
// 案例1
var x = 10
func01(x)
fmt.Println(x)
// 案例2
var s = []int{1, 2, 3}
fmt.Printf("main的s的地址:%p\n",&s)
func02(s)
fmt.Println(s)
//案例3
var a = 10
var p *int = &a
func03(p)
fmt.Println(a)
}
|
思考之前的scan函数为什么一定传参&
Go语言中所有的传参都是值传递(传值),都是一个副本,一个拷贝。因为拷贝的内容有时候是非引用类型(int、string、struct等这些),这样就在函数中就无法修改原内容数据;有的是引用类型(指针、map、slice、chan等这些),这样就可以修改原内容数据。
1
2
|
func makemap(t *maptype, hint int64, h *hmap, bucket unsafe.Pointer) *hmap {
}
|
make函数创建的map就是一个指针类型,工作原理类似于案例3,所以map数据和切片数据一样虽然值拷贝但依然可以修改原值。
7.7、匿名函数
匿名函数,顾名思义,没有函数名的函数。
匿名函数的定义格式如下:
1
2
3
|
func(参数列表)(返回参数列表){
函数体
}
|
匿名函数可以在使用函数的时候再声明调用
1
2
3
4
5
6
7
8
9
10
|
//(1)
(func() {
fmt.Println("yuan")
})()
//(2)
var z =(func(x,y int) int {
return x + y
})(1,2)
fmt.Println(z)
|
也可以将匿名函数作为一个func类型数据赋值给变量
1
2
3
4
5
6
7
|
var f = func() {
fmt.Println("yuan")
}
fmt.Println(reflect.TypeOf(f)) // func
f() // 赋值调用调用
|
Go语言不支持在函数内部声明普通函数,只能声明匿名函数。
1
2
3
4
5
6
7
|
func foo() {
fmt.Println("foo功能")
f := func(){
fmt.Println("bar功能")
}
fmt.Println(f)
}
|
7.8、高阶函数
一个高阶函数应该具备下面至少一个特点:
- 将一个或者多个函数作为形参
- 返回一个函数作为其结果
首先明确一件事情:函数名亦是一个变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package main
import (
"fmt"
"reflect"
)
func addCal(x int, y int)int{
return x + y
}
func main() {
var a = addCal
a(2, 3)
fmt.Println(a)
fmt.Println(addCal)
fmt.Println(reflect.TypeOf(addCal)) // func(int, int) int
}
|
结论:函数参数是一个变量,所以,函数名当然可以作为一个参数传入函数体,也可以作为一个返回值。
7.8.1、函数参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package main
import (
"fmt"
"time"
)
func timer(f func()){
timeBefore := time.Now().Unix()
f()
timeAfter := time.Now().Unix()
fmt.Println("运行时间:", timeAfter - timeBefore)
}
func foo() {
fmt.Println("foo function... start")
time.Sleep(time.Second * 2)
fmt.Println("foo function... end")
}
func bar() {
fmt.Println("bar function... start")
time.Sleep(time.Second * 3)
fmt.Println("bar function... end")
}
func main() {
timer(foo)
timer(bar)
}
|
注意如果函数参数也有参数该怎么写呢?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package main
import "fmt"
func add(x,y int ) int {
return x+y
}
func mul(x,y int ) int {
return x*y
}
// 双值计算器
func cal(f func(x,y int) int,x,y int,) int{
return f(x,y)
}
func main() {
ret1 := cal(add,12,3,)
fmt.Println(ret1)
ret2 := cal(mul,12,3,)
fmt.Println(ret2)
}
|
7.8.2、函数返回值
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package main
import (
"fmt"
)
func foo() func(){
inner := func() {
fmt.Printf("函数inner执行")
}
return inner
}
func main() {
foo()()
}
|
7.9、闭包
复习函数作用域
7.9.1、闭包函数
闭包并不只是一个go中的概念,在函数式编程语言中应用较为广泛。
首先看一下维基上对闭包的解释:
在计算机科学中,闭包(英语:Closure),又称词法闭包(Lexical Closure)或函数闭包(function closures),是引用了自由变量(外部非全局)的函数。
简单来说就是一个函数定义中引用了函数外定义的变量,并且该函数可以在其定义环境外被执行。这样的一个函数我们称之为闭包函数。
- 闭包就是当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之 外执行。
- 需要注意的是,自由变量不一定是在局部环境中定义的,也有可能是以参数的形式传进局部环境;另外在 Go 中,函数也可以作为参数传递,因此函数也可能是自由变量。
- 闭包中,自由变量的生命周期等同于闭包函数的生命周期,和局部环境的周期无关。
- 闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。
实现一个计数器函数,不考虑闭包的情况下,最简单的方式就是声明全局变量:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
package main
import "fmt"
var i = 0
func counter() {
i++
fmt.Println(i)
}
func main() {
counter()
counter()
counter()
}
|
这种方法的一个缺点是全局变量容易被修改,安全性较差。闭包可以解决这个问题,从而实现数据隔离。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
package main
import "fmt"
func getCounter() func() {
var i = 0
return func() {
i++
fmt.Println(i)
}
}
func main() {
counter := getCounter()
counter()
counter()
counter()
counter2 := getCounter()
counter2()
counter2()
counter2()
}
|
getCounter完成了对变量i以及counter函数的封装,然后重新赋值给counter变量,counter函数和上面案例的counter函数的区别就是将需要操作的自由变量转化为闭包环境。
7.9.2、闭包函数应用案例
在go语言中可以使用闭包函数来实现装饰器
案例1:计算函数调用次数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
package main
import (
"fmt"
"reflect"
"runtime"
)
// 函数计数器
func getCounter(f func()) func() {
calledNum := 0 // 数据隔离
return func() {
f()
calledNum += 1
// 获取函数名
fn := runtime.FuncForPC(reflect.ValueOf(f).Pointer()).Name()
fmt.Printf("函数%s第%d次被调用\n", fn, calledNum)
}
}
// 测试的调用函数
func foo() {
fmt.Println("foo function执行")
}
func bar() {
fmt.Println("bar function执行")
}
func main() {
/*fooAndCounter := getCounter(foo) // 针对foo的计数器
fooAndCounter()
fooAndCounter()
fooAndCounter()
barAndCounter := getCounter(bar)
barAndCounter()
barAndCounter()
barAndCounter()*/
foo := getCounter(foo) // 开放原则
foo()
foo()
foo()
bar := getCounter(bar)
bar()
bar()
}
|
案例2:计算函数运行时间
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package main
import (
"fmt"
"time"
)
func GetTimer(f func(t time.Duration)) func(duration time.Duration) {
return func(t time.Duration) {
t1 := time.Now().Unix()
f(t)
t2 := time.Now().Unix()
fmt.Println("运行时间:", t2-t1)
}
}
func foo(t time.Duration) {
fmt.Println("foo功能开始")
time.Sleep(time.Second * t)
fmt.Println("foo功能结束")
}
func bar(t time.Duration) {
fmt.Println("bar功能开始")
time.Sleep(time.Second * t)
fmt.Println("bar功能结束")
}
func main() {
var foo = GetTimer(foo)
foo(3)
var bar = GetTimer(bar)
bar(2)
}
|
关键点:将一个功能函数作为自由变量与一个装饰函数封装成一个整体作为返回值,赋值给一个新的函数变量,这个新的函数变量在调用的时候,既可以完成原本的功能函数又可以实现装饰功能。
7.10、defer语句
defer语句是go语言提供的一种用于注册延迟调用的机制,是go语言中一种很有用的特性。
7.10.1、defer的用法
defer语句注册了一个函数调用,这个调用会延迟到defer语句所在的函数执行完毕后执行,所谓执行完毕是指该函数执行了return语句、函数体已执行完最后一条语句或函数所在协程发生了恐慌。
1
2
3
|
fmt.Println("test01")
defer fmt.Println("test02")
fmt.Println("test03")
|
编程经常会需要申请一些资源,比如数据库连接、打开文件句柄、申请锁、获取可用网络连接、申请内存空间等,这些资源都有一个共同点那就是在我们使用完之后都需要将其释放掉,否则会造成内存泄漏或死锁等其它问题。但操作完资源忘记关闭释放是正常的,而defer可以很好解决这个问题
1
2
3
4
5
6
7
8
|
// 打开文件
file_obj,err:=os.Open("满江红")
if err != nil {
fmt.Println("文件打开失败,错误原因:",err)
}
// 关闭文件
defer file_obj.Close()
// 操作文件
|
7.10.2、多个defer执行顺序
当一个函数中有多个defer语句时,会按defer定义的顺序逆序执行,也就是说最先注册的defer函数调用最后执行。
1
2
3
4
5
|
fmt.Println("test01")
defer fmt.Println("test02")
fmt.Println("test03")
defer fmt.Println("test04")
fmt.Println("test05")
|
7.10.3、defer的拷贝机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
// 案例1
foo := func() {
fmt.Println("I am function foo1")
}
defer foo()
foo = func() {
fmt.Println("I am function foo2")
}
// 案例2
x := 10
defer func(a int) {
fmt.Println(a)
}(x)
x++
// 案例3
x := 10
defer func() {
fmt.Println(x) // 保留x的地址
}()
x++
|
当执行defer语句时,函数调用不会马上发生,会先把defer注册的函数及变量拷贝到defer栈中保存,直到函数return前才执行defer中的函数调用。需要格外注意的是,这一拷贝拷贝的是那一刻函数的值和参数的值。注册之后再修改函数值或参数值时,不会生效。
7.10.4、defer执行时机
在Go语言的函数 return 语句不是原子操作,而是被拆成了两步
rval = xxx
ret
而 defer 语句就是在这两条语句之间执行,也就是
1
2
3
4
5
6
7
8
|
rval = xxx
defer_func
ret rval
defer x = 100
x := 10
return x // rval=10. x = 100, ret rval
|
经典面试题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
package main
import "fmt"
func f1() int {
i := 5
defer func() {
i++
}()
return i
}
func f2() *int {
i := 5
defer func() {
i++
fmt.Printf(":::%p\n", &i)
}()
fmt.Printf(":::%p\n", &i)
return &i
}
func f3() (result int) {
defer func() {
result++
}()
return 5 // result = 5;ret result(result替换了rval)
}
func f4() (result int) {
defer func() {
result++
}()
return result // ret result变量的值
}
func f5() (r int) {
t := 5
defer func() {
t = t + 1
}()
return t // ret r = 5 (拷贝t的值5赋值给r)
}
func f6() (r int) {
fmt.Println(&r)
defer func(r int) {
r = r + 1
fmt.Println(&r)
}(r)
return 5
}
func f7() (r int) {
defer func(x int) {
r = x + 1
}(r)
return 5
}
func main() {
// println(f1())
// println(*f2())
// println(f3())
// println(f4())
// println(f5())
// println(f6())
// println(f7())
}
|
在命名返回方式中,最终函数返回的就是命名返回变量的值,因此,对该命名返回变量的修改会影响到最终的函数返回值!
7.11、递归函数
一种计算过程,如果其中每一步都要用到前一步或前几步的结果,称为递归的。用递归过程定义的函数,称为递归函数,例如连加、连乘及阶乘等。
递归特性:
- 调用自身函数
- 必须有一个明确的结束条件
- 在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返 回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
案例1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
package main
import "fmt"
func factorial(n int)int{
if n == 0{
return 1
}
return n * factorial(n-1)
}
func main() {
// 计算n的阶乘,即 n!
var ret = factorial(4)
fmt.Println(ret)
}
|
案例2
这个数列生成规则很简单,每一项都是前两项的和,举例
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233……
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
package main
import "fmt"
func fib(n int) int {
if n == 2 || n == 1 {
return 1
}
return fib(n-1) + fib(n-2)
}
func main() {
// 计算n的阶乘,即 n!
ret:=fib(6)
fmt.Println(ret)
}
|

7.12、章节练习
添加客户:
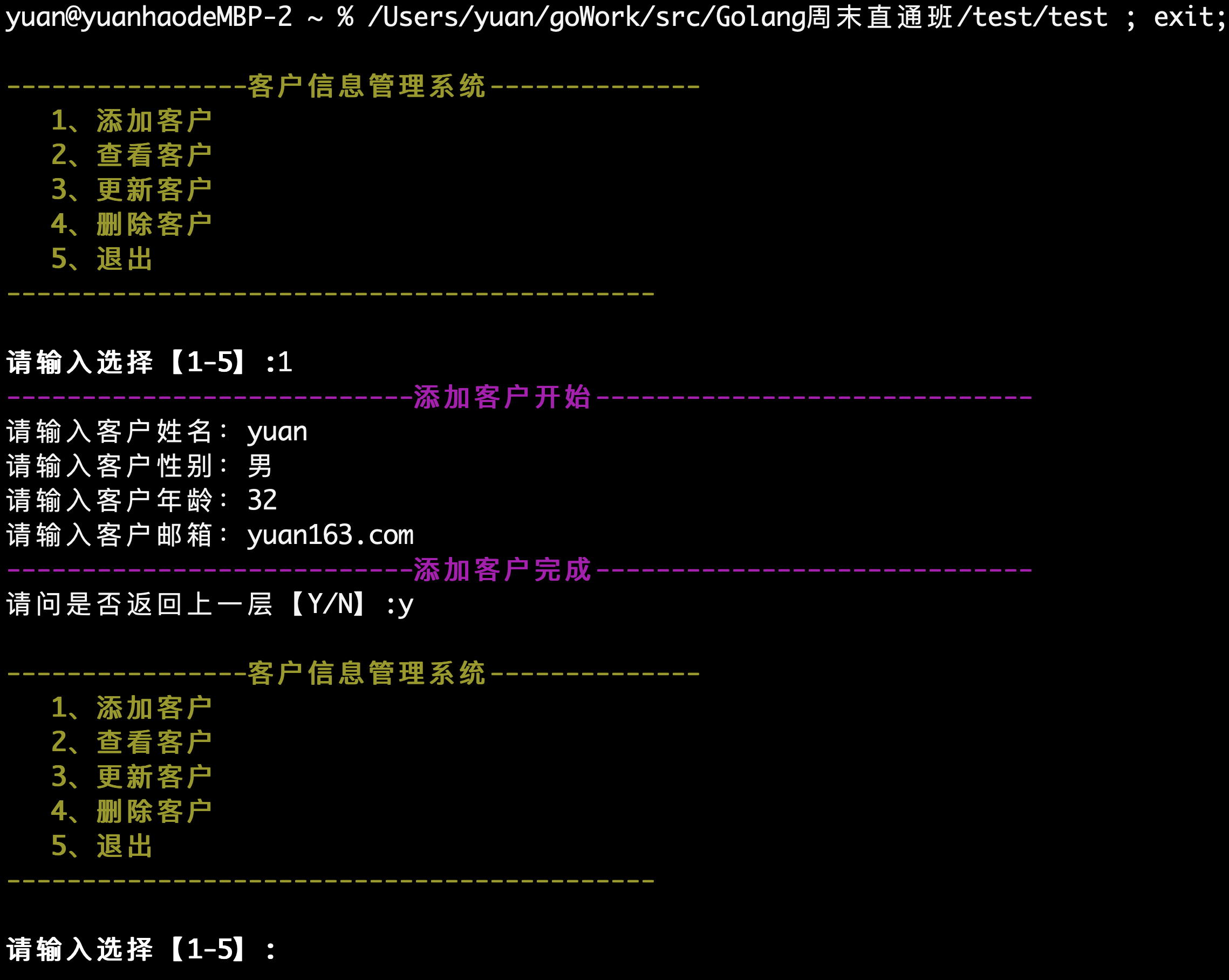
查看客户和删除客户:
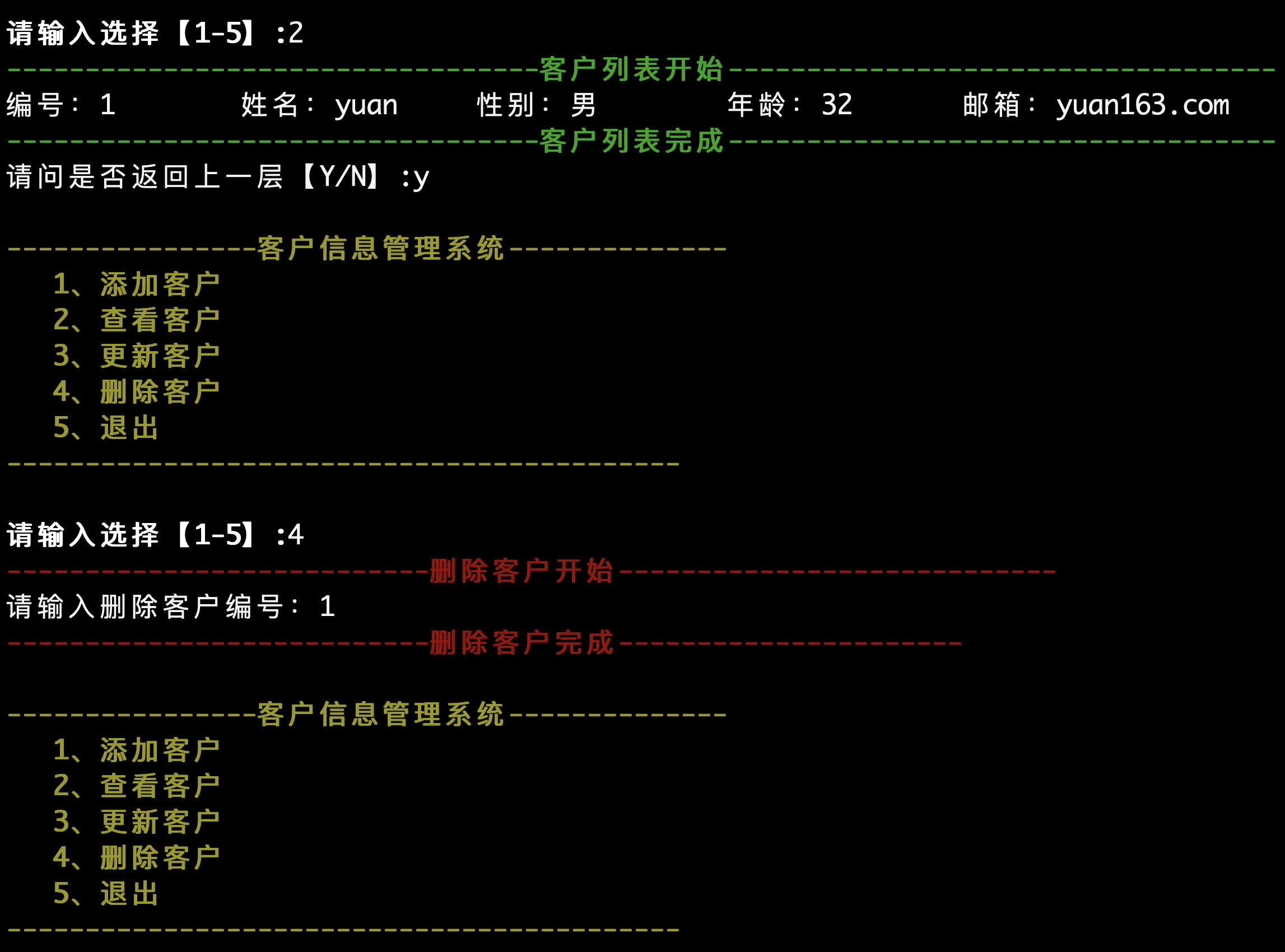
修改客户:
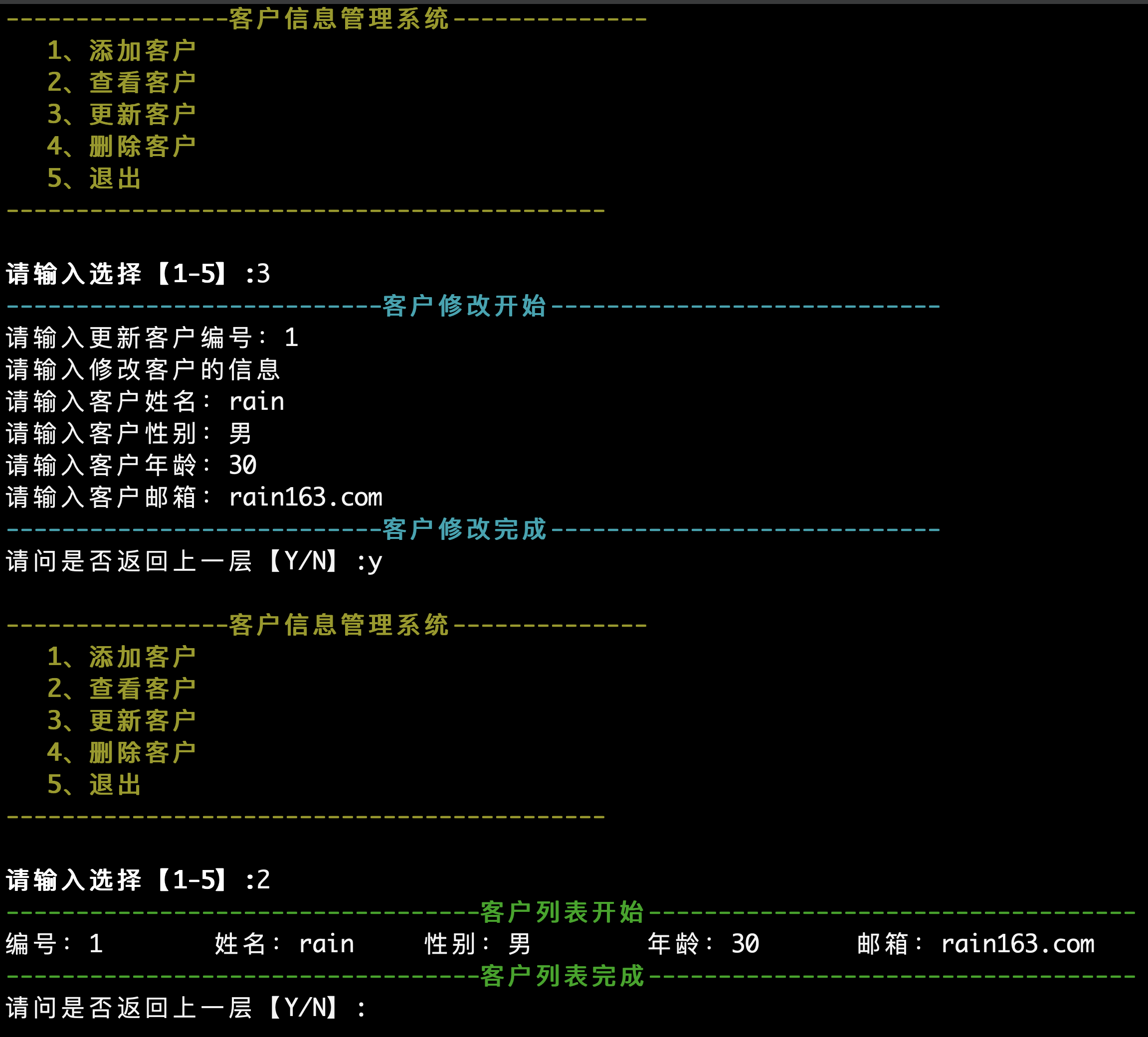
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
|
package main
import (
"bufio"
"fmt"
"os"
"strings"
)
// 构建数据存储结构
var customers []map[string]interface{}
var customersId int
func findById(id int) int {
index := -1
//遍历this.customers切⽚
for i := 0; i < len(customers); i++ {
if customers[i]["cid"] == id {
index = i
}
}
return index
}
func isBack() bool {
// 引导用户选择继续还是返回
fmt.Print("请问是否返回上一层【Y/N】:")
var backChoice string
fmt.Scan(&backChoice)
if strings.ToUpper(backChoice) == "Y" {
return true
} else {
return false
}
}
func inputInfo() (string, string, int8, string) {
var name string
fmt.Print("请输入客户姓名:")
fmt.Scan(&name)
var gender string
fmt.Print("请输入客户性别:")
fmt.Scan(&gender)
var age int8
fmt.Print("请输入客户年龄:")
fmt.Scan(&age)
var email string
fmt.Print("请输入客户邮箱:")
fmt.Scan(&email)
return name, gender, age, email
}
func addCustomer() {
for true {
// 引导用户输入学号和姓名
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户开始-----------------------------")
name, gender, age, email := inputInfo()
// 创建客户的map对象
customersId++ // 客户编号不需要输入,系统自增即可
newCustomer := map[string]interface{}{
"cid": customersId,
"name": name,
"gender": gender,
"age": age,
"email": email,
}
// 添加客户map对象添加到客户切片中
customers = append(customers, newCustomer)
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户完成-----------------------------")
b := isBack()
if b {
break
}
}
}
func listCustomer() {
for true {
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表开始-----------------------------------")
for _, customer := range customers {
fmt.Printf("编号:%-8d 姓名:%-8s 性别:%-8s 年龄:%-8d 邮箱:%-8s \n",
customer["cid"], customer["name"], customer["gender"], customer["age"], customer["email"])
}
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表完成-----------------------------------")
b := isBack()
if b {
break
}
}
}
func updateCustomer() {
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改开始----------------------------")
for true {
var updateCid int
fmt.Print("请输入更新客户编号:")
fmt.Scan(&updateCid)
updateIndex := findById(updateCid)
if updateIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
fmt.Println("请输入修改客户的信息")
name, gender, age, email := inputInfo()
customers[updateIndex]["name"] = name
customers[updateIndex]["gender"] = gender
customers[updateIndex]["age"] = age
customers[updateIndex]["email"] = email
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改完成----------------------------")
b := isBack()
if b {
break
}
}
}
func deleteCustomer() {
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户开始----------------------------")
var delCid int
fmt.Print("请输入删除客户编号:")
fmt.Scan(&delCid)
delIndex := findById(delCid)
if delIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
return
}
customers = append(customers[:delIndex], customers[delIndex+1:]...)
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户完成----------------------")
}
var data = make(map[string]map[string]string)
func main() {
for true {
fmt.Printf("\033[1;33;40m%s\033[0m\n", `
----------------客户信息管理系统--------------
1、添加客户
2、查看客户
3、更新客户
4、删除客户
5、退出
-------------------------------------------
`)
var choice int
fmt.Printf("\033[1;38;40m%s\033[0m", "请输入选择【1-5】:")
stdin := bufio.NewReader(os.Stdin)
fmt.Fscan(stdin, &choice)
switch choice {
case 1:
addCustomer()
case 2:
listCustomer()
case 3:
updateCustomer()
case 4:
deleteCustomer()
default:
fmt.Println("非法输入!")
os.Exit(0)
}
}
}
|
八、文件操作
8.1、编码

众所周知,计算机起源于美国,英文只有26个字符,算上其他所有特殊符号也不会超过128个。字节是计算机的基本储存单位,一个字节(bytes)包括八个比特位(bit),能够表示出256个二进制数字,所以美国人在这里只是用到了一个字节的前七位即127个数字来对应了127个具体字符,而这张对应表就是ASCII码字符编码表,简称ASCII表。后来为了能够让计算机识别拉丁文,就将一个字节的最高位也应用了,这样就多扩展出128个二进制数字来对应新的符号。这张对应表因为是在ASCII表的基础上扩展的最高位,因此称为扩展ASCII表。到此位置,一个字节能表示的256个二进制数字都有了特殊的符号对应。
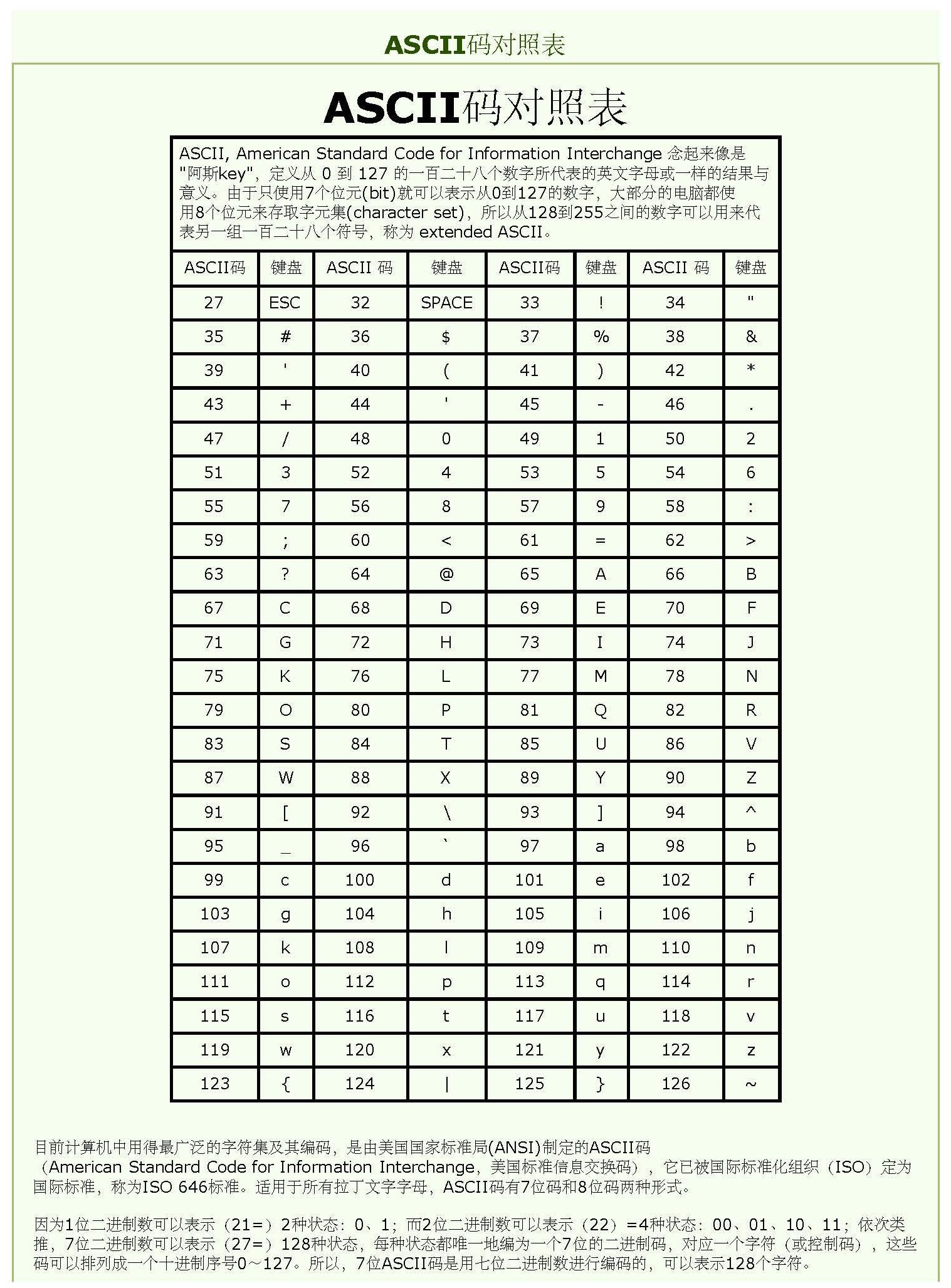
但是,当计算机发展到东亚国家后,问题又出现了,像中文,韩文,日文等符号也需要在计算机上显示。可是一个字节已经被西方国家占满了。于是,我中华民族自己重写一张对应表,直接生猛地将扩展的第八位对应拉丁文全部删掉,规定一个小于127的字符的意义与原来相同,即支持ASCII码表,但两个大于127的字符连在一起时,就表示一个汉字,这样就可以将几千个汉字对应一个个二进制数了。而这种编码方式就是GB2312,也称为中文扩展ASCII码表。再后来,我们为了对应更多的汉字规定只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。这样能多出几万个二进制数字,就算甲骨文也能够用了。而这次扩展的编码方式称为GBK标准。当然,GBK标准下,一个像”苑”这样的中文符号,必须占两个字节才能存储显示。
与此同时,其它国家也都开发出一套编码方式,即本国文字符号和二进制数字的对应表。而国家彼此间的编码方式是互不支持的,这会导致很多问题。于是ISO国际化标准组织为了统一编码,统计了世界上所有国家的字符,开发出了一张万国码字符表,用两个字节即六万多个二进制数字来对应。这就是Unicode编码方式。这样,每个国家都使用这套编码方式就再也不会有计算机的编码问题了。Unicode的编码特点是对于任意一个字符,都需要两个字节来存储。这对于美国人而言无异于吃上了世界的大锅饭,也就是说,如果用ASCII码表,明明一个字节就可以存储的字符现在为了兼容其他语言而需要两个字节了,比如字母I,本可以用01001001来存储,现在要用Unicode只能是00000000 01001001存储,而这将导致大量的空间被浪费掉。基于此,美国人创建了utf8编码,而utf8编码是一种针对Unicode的可变长字符编码方式,根据具体不同的字符计算出需要的字节,对于ASCII码范围的字符,就用一个字节,而且符号与数字的对应也是一致的,所以说utf8是兼容ASCII码表的。但是对于中文,一般是用三个字节存储的。
8.2、Go的字符与字节
byte就是字节的意思,一个字节就是8个二进制位。uint8,无符号整形,占8位,正好也是2的8次方。所以byte和 uint8 类型本质上没有区别,它表示的是 ACSII 表中的一个字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// byte类型
var b1 byte
b1 = 'A' // 必须是单引号
// b1 = 98 // 必须是单引号
fmt.Println(reflect.TypeOf(b1)) // 65 uint8
fmt.Printf("%c\n",b1)
fmt.Printf("%d\n",b1) // ASCII数字
fmt.Println(b1) // ASCII数字
// uint8类型
var b2 uint8
b2 = 65
// b2 = 'c'
fmt.Printf("%c\n",b2)
fmt.Printf("%d\n",b2)
fmt.Println(b2) // ASCII数字
// var b3 byte
var b3 rune
b3 = '苑'
// rune,占用4个字节,共32位比特位,所以它和 int32 本质上也没有区别。它表示的是一个 Unicode字符
fmt.Println(b3,string(b3),reflect.TypeOf(b3))
|
8.3、字符串
go语⾔的string是⼀种数据类型,这个数据类型占⽤16字节空间,前8字节是⼀个指针,指向字符串值的地址,后⼋个字节是⼀个整数,标识字 符串的长度;
(1)字符串的存储原理
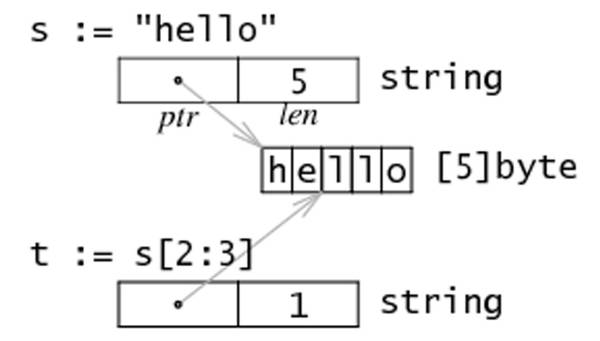
string 数据结构:源码包src/runtime/string.go:stringStruct定义了string的数据结构:
1
2
3
4
|
type stringStruct struct {
str unsafe.Pointer
len int
}
|
其数据结构很简单:
stringStruct.str:字符串的首地址;
stringStruct.len:字符串的长度;
string数据结构跟切片有些类似,只不过切片还有一个表示容量的成员,事实上string和切片,准确的说是byte切片经常发生转换。这个后面再详细介绍。
1
2
3
4
5
6
|
s1 := "hello"
s2 := s1[:]
s3 := s1[1:]
fmt.Println(&s1, (*reflect.StringHeader)(unsafe.Pointer(&s1)))
fmt.Println(&s2, (*reflect.StringHeader)(unsafe.Pointer(&s2)))
fmt.Println(&s3, (*reflect.StringHeader)(unsafe.Pointer(&s3)))
|
1
2
3
4
5
|
/*
A string type represents the set of string values. A string value is a (possibly empty) sequence of bytes. Strings are immutable: once created, it is impossible to change the contents of a string. The predeclared string type is string.
The length of a string s (its size in bytes) can be discovered using the built-in function len. The length is a compile-time constant if the string is a constant. A string's bytes can be accessed by integer indices 0 through len(s)-1. It is illegal to take the address of such an element; if s[i] is the i'th byte of a string, &s[i] is invalid.
*/
|
字符串类型表示字符串值的集合。字符串值是一个字节序列(可能为空)。字符串是不可变的:一旦创建,就不可能改变字符串的内容。预先声明的字符串类型是string。
字符串s的长度(以字节为单位的大小)可以使用内置函数len来发现。如果字符串是常量,则长度为编译时常量。字符串的字节可以通过索引0到len(s)-1的整数来访问。取这样一个元素的地址是非法的;如果s[i]是字符串的第i个字节,&s[i]是无效的。
go语⾔指针和C/C++指针的唯⼀差别就是:go语⾔不允许对指针做算术运算(+、-、++、–)。
但是,Go提供了⼀套底层库reflect和unsafe,它们可以把任意⼀个go指针转成uintptr类型的值,然后再像C/C++⼀样对指针做算术运算,最后再还原成go类型。所以从这个⾓度上看,go指针也是可以和C/C++指针⼀样使⽤的,只是会⽐较绕,这同时也要求使⽤者⾃⼰明⽩,如果真要把指针这么⽤,那么请记得后果⾃负。
(2)字符串的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
// 本质上,unicode是一个编码集,和ascii码相同,而utf8是编码规则
var a = '苑'
fmt.Printf("字符'苑'unicode的十进制:%d\n", a)
fmt.Printf("字符'苑'unicode的十六进制:%x\n", a)
fmt.Printf("字符'苑'unicode的二进制:%b\n", a)
var b = 0b111010001000101110010001
fmt.Printf("字符'苑'的utf8:%x\n", b)
var c = "苑abc"
fmt.Println(c) // 苑abc
for i := 0; i < len(c); i++ {
fmt.Printf("%d\n", c[i]) // 存储的字节的十进制数
}
for _, v := range c {
fmt.Printf("%d,%c\n", v, v) // 通过存储的utf8解析到unicode值和对应的符号
}
|
UTF-8的编码规则:
(1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
(2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
举例说明:
已知’苑’的unicode是82d1(1000001011010001),‘苑’的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从’苑’的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,‘苑’的UTF-8编码是 “111010001 00010111 0010001”,转换成十六进制就是e88b91。
(3)字符串与字节串的转换
字节数组,就是一个数组,里面每一个元素都是字符,字符又跟字节划等号。所以字符串和字节数组之间可以相互转化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
// (1) 字符串类型(string) 转为字节串类型([]byte)
var s = "苑昊"
fmt.Println(s,reflect.TypeOf(s)) // 苑昊 string
var b = []byte(s) // 默认用uft-8进行编码
fmt.Println(b,reflect.TypeOf(b)) // [232 139 145 230 152 138] []uint8
// 可以通过代码 len([]rune(s)) 来获得字符串中字符的数量, 但使用 utf8.RuneCountInString(s) 效率会更高一点.
s := "Hello,世界"
r1 := []byte(s)
r2 := []rune(s)
fmt.Println(r1) // 输出:[72 101 108 108 111 44 32 228 184 150 231 149 140]
fmt.Println(r2) // 输出:[72 101 108 108 111 44 32 19990 30028]
// 统计字节个数
fmt.Println(len(r1))
// 统计字符个数
fmt.Println(len(r2))
fmt.Println(utf8.RuneCountInString(s))
// (2) byte转为string
fmt.Println(string(b))
var data = []byte{121,117,97,110}
fmt.Println(string(data)) // yuan
|
这里的转化不是将string结构体中指向的byte切片直接做赋值操作,而是通过copy实现的,在数据量比较大时,这里的转化会比较耗费内存空间。
(4)练习
将字符串 “hello” 转换为 “cello”
1
2
3
4
|
s := "hello"
c := []byte(s)
c[0] = 'c'
s2 := string(c) //s2 == "cello"
|
将字符串 “hello” 反转
1
2
3
4
5
6
7
8
9
|
func reverseString(s []byte) []byte {
var i, j = 0, len(s) - 1
for i < j {
s[i], s[j] = s[j], s[i]
i++
j--
}
return s
}
|
8.3、读写文件
8.3.1、打开文件
os.Open()函数能够打开一个文件,返回一个*File和一个err。
1
2
3
4
5
6
7
|
//打开文件
file, err := os.Open("./满江红")
if err != nil {
fmt.Println("err: ", err)
}
//关闭文件句柄
defer file.Close()
|
8.3.2、读文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"os"
)
func readBytes(file *os.File) {
var b = make([]byte, 3)
n, err := file.Read(b)
if err != nil {
fmt.Println("err:", err)
return
}
fmt.Printf("读取字节数:%d\n", n)
fmt.Printf("切片值:%v\n", b)
fmt.Printf("读取内容:%v\n", string(b[:n]))
}
func readLines(file *os.File) {
reader := bufio.NewReader(file)
for {
// (1) 按行都字符串
strs, err := reader.ReadString('\n') // 读取到换行符为止,读取内容包括换行符
fmt.Print(err, strs)
// (2) 按行都字节串
// bytes, err := reader.ReadBytes('\n')
// fmt.Print(bytes)
// fmt.Print(string(bytes))
if err == io.EOF { //io.EOF 读取到了文件的末尾
// fmt.Println("读取到文件末尾!")
break
}
}
}
func readFile() {
content, err := ioutil.ReadFile("满江红") //包含了打开文件和读取整个文件,适用于较小文件
if err != nil {
fmt.Println("read file failed, err:", err)
return
}
fmt.Print(string(content))
}
func main() {
//打开文件
file, err := os.Open("满江红") // 相对路径或者绝对路径
if err != nil {
fmt.Println("err: ", err)
}
//关闭文件句柄
defer file.Close()
// (1) 按字节读取数据
// readBytes(file)
// (2) 按行读取文件
// readLines(file)
// (3) 读取整个文件
// readFile()
}
|
8.3.3、写文件
OpenFile是一个更一般性的文件打开函数,大多数调用者都应用Open或Create代替本函数。它会使用指定的选项(如O_RDONLY等)、指定的模式(如0666等)打开指定名称的文件。如果操作成功,返回的文件对象可用于I/O。如果出错,错误底层类型是*PathError。
1
2
3
4
5
6
7
8
9
10
11
12
|
func OpenFile(name string, flag int, perm FileMode) (file *File, err error) // ⽂件路径、打开模式、⽂件权限
/*
os.O_RDONLY: 只读模式(read-only)
os.O_WRONLY: 只写模式(write-only)
os.O_RDWR : 读写模式(read-write)
os.O_APPEND: 追加模式(append)
os.O_CREATE: ⽂件不存在就创建(create a new file if none exists.)
os.O_TRUNC: 打开并清空⽂件(必须有写权限)
os.O_EXCL: 如与 O_CREATE ⼀起⽤,构成⼀个新建⽂件的功能,它要求⽂件必须不存在(used with O_CREATE, file must not exist)
os.O_SYNC:同步⽅式打开,即不使⽤缓存,直接写⼊硬盘
*/
|
(1)只写模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
package main
import (
"bufio"
"fmt"
"io/ioutil"
"os"
)
func writeBytesOrStr(file *os.File) {
str := "满江红666\n"
//写入字节切片数据
file.Write([]byte(str))
//直接写入字符串数据
file.WriteString("怒发冲冠,凭栏处、潇潇雨歇。")
}
func writeByBufio(file *os.File) {
writer := bufio.NewWriter(file)
//将数据先写入缓存,并不会到文件中
writer.WriteString("大浪淘沙\n")
// 必须flush将缓存中的内容写入文件
// writer.Flush()
}
func writeFile() {
str := "怒发冲冠,凭栏处、潇潇雨歇。"
err := ioutil.WriteFile("满江红", []byte(str), 0666)
if err != nil {
fmt.Println("write file failed, err:", err)
return
}
}
func main() {
file, err := os.OpenFile("满江红.txt", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
fmt.Println("open file failed, err:", err)
return
}
defer file.Close()
// 写字节或者字符串
writeBytesOrStr(file)
// flush写
writeByBufio(file)
// 写文件
writeFile()
}
|
0777:-rwxrwxrwx,创建了一个普通文件,所有人拥有所有的读、写、执行权限
0666:-rw-rw-rw-,创建了一个普通文件,所有人拥有对该文件的读、写权限,但是都不可执行
0644:-rw-r–r–,创建了一个普通文件,文件所有者对该文件有读写权限,用户组和其他人只有读权限,没有执行权限
(2)读写模式
读取一个文件每一行内容,并追加一行该行的字符个数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
package main
import (
"bufio"
"fmt"
"io"
"os"
"strings"
)
func main() {
file, err := os.OpenFile("读写满江红", os.O_CREATE|os.O_RDWR|os.O_APPEND, 0666)
if err != nil {
fmt.Println("open file failed, err:", err)
return
}
defer file.Close()
reader := bufio.NewReader(file)
writer := bufio.NewWriter(file)
for true {
// (1) 按行都字符串
strs, err := reader.ReadString('\n') // 读取到换行符为止,读取内容包括换行符
content := strings.Trim(strs, "\n")
s := fmt.Sprintf("\n该行长度为%d,内容为:%s", len([]rune(content)), content)
// (2) 将行数记录追加进入文件
writer.WriteString(s)
writer.Flush()
if err == io.EOF {
break
}
}
}
|
8.4、其它文件操作
(1) 删除文件
os.Remove(fname)
(2) 创建目录
dname :=“rain”
os.Mkdir(dname,os.ModeDir|os.ModePerm)
(3)获取文件信息
通过os.Stat方法,我们可以获取文件的信息,比如文件大小、名字等。
1
2
3
4
5
6
7
8
9
10
|
func main() {
f,err:=os.Stat("满江红")
if err ==nil {
fmt.Println("name:",f.Name())
fmt.Println("size:",f.Size())
fmt.Println("is dir:",f.IsDir())
fmt.Println("mode::",f.Mode())
fmt.Println("modTime:",f.ModTime())
}
}
|
以上就是可以获取到的文件信息,还包括判断是否是目录,权限模式和修改时间。所以我们对于文件的信息获取要使用os.Stat函数,它可以在不打开文件的情况下,高效获取文件信息。
os.Stat函数有两个返回值,一个是文件信息,一个是err,通过err我们可以判断文件是否存在。首先,err==nil的时候,文件肯定是存在的;其次err!=nil的时候也不代表不存在,通过err是否等于os.IsNotExist来判断一个文件不存在。
九、结构体
在实际开发中,我们可以将一组类型不同的、但是用来描述同一件事物的变量放到结构体中。例如,在校学生有姓名、年龄、身高、成绩等属性,学了结构体后,我们就不需要再定义多个变量了,将它们都放到结构体中即可。
在Go语言中,结构体承担着面向对象语言中类的作用。Go语言中,结构体本身仅用来定义属性。还可以通过接收器函数来定义方法,使用内嵌结构体来定义继承。这样使用结构体相关操作Go语言就可以实现OOP面向对象编程了。
9.1、声明结构体
Go语言通过type和struct关键字声明结构体,格式如下:
1
2
3
4
5
|
type 类型名 struct { // 标识结构体的类型名,在同一个包内不能重复
字段1 字段1类型 // 字段名必须唯一
字段2 字段2类型
…
}
|
Go语言结构体(Struct)从本质上讲是一种自定义的数据类型,只不过这种数据类型比较复杂,是由 int、char、float 等基本类型组成的。你可以认为结构体是一种聚合类型。
1
2
3
4
5
6
7
|
type Student struct {
sid int
name string
age int8
course []string // 选秀课程
}
|
Go 语言使用结构体和结构体成员来描述真实世界的实体和实体对应的各种属性。结构体成员,也可称之为成员变量,字段,属性。属性要满足唯一性。
同类型的变量也可以写在一行,用逗号隔开
1
2
3
4
|
type Book struct {
title,author string
price int
}
|
9.2、结构体的实例化
结构体的定义只是一种内存布局的描述,只有当结构体实例化时,才会真正地分配内存,因此必须在定义结构体并实例化后才能使用结构体的字段。实例化就是根据结构体定义的格式创建一份与格式一致的内存区域,结构体实例与实例间的内存是完全独立的。
实例化方式包括如下几种。
9.2.1、声明结构体变量再赋值
结构体本身是一种类型,可以像整型、字符串等类型一样,以 var 的方式声明结构体即可完成实例化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
package main
import "fmt"
type Student struct {
sid int
name string
age int8
course []string // 选秀课程
}
func main() {
// 声明一个结构体对象 ,值类型,默认开辟空间,字段赋予零值
var s Student
fmt.Println("s:", s)
// 要访问结构体成员,需要使用点号 . 操作符
fmt.Println(s.name)
// 更改成员变量的值
s.name = "yuan"
fmt.Println(s.name)
// s.course[0] = "chinese" // 结果,如何调整
}
|
1、结构体属于值类型,即var声明后会像整形字符串一样创建内存空间。
2、创建结构体对象如果没有给字段赋值,则默认零值(字符串默认 “",数值默认0,布尔默认false,切片和map默认nil对象)
结构体的内存存储:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import "fmt"
type Student struct {
sid int
name string
age int8
course []string // 选秀课程
}
func main() {
// 声明一个结构体对象 ,值类型,默认开辟空间,字段赋予零值
var s Student
fmt.Println("s:", s)
s.sid = 1001
s.name = "yuan"
s.age = 23
s.course = []string{"chinese", "math", "english"}
fmt.Printf("%p\n", &s)
fmt.Printf("%p\n", &(s.sid))
fmt.Printf("%p\n", &(s.name))
fmt.Printf("%p\n", &(s.age))
fmt.Printf("%p\n", &(s.course)) // 切片24个字节
}
|
之前我们学习过值类型和引用类型,知道值类型是变量对应的地址直接存储值,而引用类型是变量对应地址存储的是地址。因为结构体因为是值类型,所以p的地址与存储的第一个值的地址是相同的,而后面每一个成员变量的地址是连续的。
9.2.2、实例化之 结构体
1
2
3
4
5
6
7
8
9
10
|
// (1) 方式1
s1 := Student{}
s1.sid = 1001
s1.name = "yuan"
// (2) 方式2:键值对赋值
s2 := Student{sid: 1002, name: "rain", course: []string{"chinese", "math", "english"}}
fmt.Println(s2)
// (3) 方式3:多值赋值
s3 := Student{1003, "alvin", 22, []string{"chinese", "math", "english"}}
fmt.Println(s3)
|
1、结构体可以使用“键值对”(Key value pair)初始化字段,每个“键”(Key)对应结构体中的一个字段,键的“值”(Value)对应字段需要初始化的值。键值对的填充是可选的,不需要初始化的字段可以不填入初始化列表中,走默认值。
2、多值初始化方式必须初始化结构体的所有字段且每一个初始值的填充顺序必须与字段在结构体中的声明顺序一致。
3、键值对与值列表的初始化形式不能混用。
9.2.3、实例化之&结构体
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
package main
import "fmt"
type Student struct {
sid int
name string
age int8
course []string // 选秀课程
}
func CourseInit(stu Student) {
stu.course = []string{"chinese", "math", "english"}
fmt.Println(stu)
}
func CourseInit2(stu *Student) {
(*stu).course = []string{"chinese", "math", "english"}
}
func main() {
// 案例1
s1 := Student{sid: 1001, name: "alvin", age: 32}
s2 := s1 // 值拷贝
fmt.Println(s2)
s1.age = 100
fmt.Println(s2.name)
// 如果希望s3的值跟随s2保持一致怎么实现
s3 := &s1 // var s4 *Student = &s2
s1.age = 100
fmt.Println((*s3).age)
fmt.Println(s3.age)
// 案例2
var s4 = Student{sid: 1001, name: "alvin", age: 32}
CourseInit(s4)
fmt.Println("s报的课程:", s4.course)
// 怎么能初始化成功呢?
var s5 = &Student{sid: 1001, name: "alvin", age: 32}
CourseInit2(s5)
fmt.Println("s报的课程:", (*s5).course) // *s.course的写法是错误的
fmt.Println("s报的课程:", s5.course)
}
|
在Go语言中,结构体指针的变量可以继续使用.,这是因为Go语言为了方便开发者访问结构体指针的成员变量可以像访问结构体的成员变量一样简单,使用了语法糖(Syntactic sugar)技术,将 instance.Name 形式转换为 (*instance).Name。
9.2.4、实例化之 new(结构体)
Go语言中,还可以使用 new 关键字对类型(包括结构体、整型、浮点数、字符串等)进行实例化,结构体在实例化后会形成指针类型的结构体。使用 new 的格式如下:其中:
其中:
- T 为类型,可以是结构体、整型、字符串等。
instance:T 类型被实例化后保存到 instance 变量中,instance的类型为 *T,属于指针。
1
2
3
4
5
6
|
s := new(Student) // &Student{}
fmt.Println(reflect.TypeOf(s)) // *Student
fmt.Println(s) // *Student
s.name = "yuan"
fmt.Println((*s).name)
fmt.Println(s.name)
|
9.4、模拟构造函数
Go语言没有构造函数,但是我们可以使用结构体初始化的过程来模拟实现构造函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import "fmt"
type Student struct {
sid int
name string
age int8
course []string // 选秀课程
}
func NewStudent(sid int, name string, age int8, course []string) *Student {
return &Student{
sid: sid,
name: name,
age: age,
course: course,
}
}
func main() {
s := NewStudent(1001, "yuan", 32, nil)
fmt.Println(s)
}
|
9.5、方法接收器
Go语言中的方法(Method)是一种作用于特定类型变量的函数。这种特定类型变量叫做接收者(Receiver)。
方法的定义格式如下:
1
2
3
|
func (接收者变量 接收者类型) 方法名(参数列表) (返回参数) {
函数体
}
|
其中,
- 接收者变量:接收者中的参数变量名在命名时,官方建议使用接收者类型名称首字母的小写,而不是
self、this之类的命名。例如,Person类型的接收者变量应该命名为 p,Connector类型的接收者变量应该命名为c等。
- 接收者类型:接收者类型和参数类似,可以是指针类型和非指针类型。
- 方法名、参数列表、返回参数:具体格式与函数定义相同。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package main
import "fmt"
type Player struct {
Name string
HealthPoint int
Level int
NowPosition []int
Prop []string
}
func NewPlayer(name string, hp int, level int, np []int, prop []string) *Player {
return &Player{
name,
hp,
level,
np,
prop,
}
}
func (p Player) attack() {
fmt.Printf("%s发起攻击!\n", p.Name)
}
func (p *Player) attacked() {
fmt.Printf("%s被攻击!\n", p.Name)
p.HealthPoint -= 10
fmt.Println(p.HealthPoint)
}
func (p *Player) buyProp(prop string) {
p.Prop = append(p.Prop, prop)
fmt.Printf("%s购买道具!\n", p.Name)
}
func main() {
player := NewPlayer("yuan", 100, 100, nil, nil)
player.attack()
player.attacked()
fmt.Println(player.HealthPoint)
player.buyProp("魔法石")
fmt.Println(player.Prop)
}
|
1、官方定义:Methods are not mixed with the data definition (the structs): they are orthogonal to types; representation(data) and behavior (methods) are independent
2、方法与函数的区别是,函数不属于任何类型,方法属于特定的类型。
9.6、匿名字段
结构体允许其成员字段在声明时没有字段名而只有类型,这种没有名字的字段就称为匿名字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
package main
import "fmt"
type Person struct {
string
int
}
func main() {
p1 := Person{
"yuan",
18,
}
fmt.Printf("%#v\n", p1) //main.Person{string:"yuan", int:18}
fmt.Println(p1.string, p1.int) //北京 18
}
|
结构体也可以作为匿名字段使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import "fmt"
type Addr struct {
country string
province string
city string
}
type Person struct {
name string
age int
Addr
}
func main() {
p1 := Person{
"yuan",
18,
Addr{"中国", "广东省", "深圳"},
}
fmt.Printf("%#v\n", p1) //main.Person{string:"北京", int:18}
fmt.Println(p1.name, p1.age) // yuan 18
fmt.Println(p1.Addr)
fmt.Println(p1.Addr.country) // 中国
fmt.Println(p1.city) // 深圳
}
|
当结构体中有和匿名字段相同的字段时,采用外层优先访问原则
9.7、结构体的继承
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
|
package main
import "fmt"
//Animal 动物
type Animal struct {
name string
}
func (a *Animal) eat() {
fmt.Printf("%s is eating!\n", a.name)
}
func (a *Animal) sleep() {
fmt.Printf("%s is sleeping!\n", a.name)
}
// Dog 类型
type Dog struct {
Kind string
*Animal //通过嵌套匿名结构体实现继承
}
func (d *Dog) bark() {
fmt.Printf("%s is barking ~\n", d.name)
}
// Cat 类型
type Cat struct {
*Animal
}
func (c *Cat) climbTree() {
fmt.Printf("%s is climb tree ~\n", c.name)
}
func main() {
d1 := &Dog{
Kind: "金毛",
Animal: &Animal{ //注意嵌套的是结构体指针
name: "旺财",
},
}
d1.eat()
d1.bark()
c1 := &Cat{
Animal: &Animal{
name: "喵喵",
},
}
c1.sleep()
c1.climbTree()
}
|
9.8、序列化
序列化: 通过某种方式把数据结构或对象写入到磁盘文件中或通过网络传到其他节点的过程。
反序列化:把磁盘中对象或者把网络节点中传输的数据恢复为python的数据对象的过程。
9.8.1、json初识
序列化最重要的就是json序列化。
JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
| go语言数据类型 |
json支持的类型 |
| 整型、浮点型 |
整型、浮点型 |
| 字符串(在双引号中) |
字符串(双引号) |
逻辑值(true 或 false) |
逻辑值(true 或 false) |
| 数组,切片 |
数组(在方括号中) |
| map |
对象(在花括号中) |
| nil |
null |
9.8.2、结构体的json操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
package main
import (
"encoding/json"
"fmt"
)
type Addr struct {
Province string
City string
}
type Stu struct {
Name string `json:"name"` // 结构体的标签
Age int `json:"-"` // 表示不参与序列化
Addr Addr
}
func main() {
var stuMap = map[string]interface{}{"name": "yuan", "age": 32, "addr": "beijing"}
var stuStruct = Stu{Name: "yuan", Age: 18, Addr: Addr{Province: "Hebei", City: "langFang"}}
// 序列化
jsonStuMap, _ := json.Marshal(stuMap)
jsonStuStruct, _ := json.Marshal(stuStruct)
fmt.Println(string(jsonStuMap))
fmt.Println(string(jsonStuStruct))
// 反序列化
// var x = make(map[int]string)
var StuMap map[string]interface{}
err := json.Unmarshal(jsonStuMap, &StuMap)
if err != nil {
return
}
fmt.Println("StuMap", StuMap, StuMap["name"])
var StuStruct Stu
err := json.Unmarshal(jsonStuStruct, &StuStruct)
if err != nil {
return
}
fmt.Println(StuStruct)
fmt.Println(StuStruct.Name)
fmt.Println(StuStruct.Addr.City)
}
|
9.9、章节作业
将客户关系管理系统改为结构体版本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
|
package main
import (
"bufio"
"encoding/json"
"fmt"
"io/ioutil"
"os"
"strings"
)
type Customer struct {
Cid int
Name string
Gender string
Age int8
Email string
}
func NewCustomer(cid int, name string, gender string, age int8, email string) Customer {
return Customer{
Cid: cid,
Name: name,
Gender: gender,
Age: age,
Email: email,
}
}
type CustomerService struct {
customers []Customer
customersId int
}
func NewCustomerService(customers []Customer, customersId int) CustomerService {
return CustomerService{customers, customersId}
}
func (cs *CustomerService) findById(id int) int {
index := -1
for i := 0; i < len(cs.customers); i++ {
if cs.customers[i].Cid == id {
index = i
}
}
return index
}
func (cs *CustomerService) nextChoice() (b bool) {
// 引导用户选择继续还是返回
fmt.Print("返回上一层【回车】,继续该操作【C/c】,退出【Q/q】:")
var Choice string
fmt.Scanln(&Choice)
if strings.ToUpper(Choice) == "C" {
b = true
} else if strings.ToUpper(Choice) == "Q" {
os.Exit(0)
}
return
}
func (cs *CustomerService) addCustomer() {
for true {
// 引导用户输入学号和姓名
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户开始-----------------------------")
// 引导用户输入
var name string
fmt.Print("请输入客户姓名:")
fmt.Scan(&name)
var gender string
fmt.Print("请输入客户性别:")
fmt.Scan(&gender)
var age int8
fmt.Print("请输入客户年龄:")
fmt.Scan(&age)
var email string
fmt.Print("请输入客户邮箱:")
fmt.Scan(&email)
// 创建客户的map对象
cs.customersId++ // 客户编号不需要输入,系统自增即可
newCustomer := NewCustomer(cs.customersId, name, gender, age, email)
// 添加客户map对象添加到客户切片中
cs.customers = append(cs.customers, newCustomer)
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户完成-----------------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) listCustomer() {
for true {
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表开始----------------------------")
for _, customer := range cs.customers {
fmt.Printf("\u001B[1;39;45m编号:%-8d 姓名:%-8s 性别:%-8s 年龄:%-8d 邮箱:%-10s \u001B[0m\n",
customer.Cid, customer.Name, customer.Gender, customer.Age, customer.Email)
}
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表完成----------------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) updateCustomer() {
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改开始----------------------------")
for true {
var updateCid int
fmt.Print("请输入更新客户编号(-1退出):")
fmt.Scan(&updateCid)
if updateCid == -1 {
return
}
updateIndex := cs.findById(updateCid)
if updateIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
// 引导用户输入
var name string
fmt.Printf("请输入客户姓名(%s):", cs.customers[updateIndex].Name)
fmt.Scanln(&name)
var gender string
fmt.Printf("请输入客户性别(%s):", cs.customers[updateIndex].Gender)
fmt.Scanln(&gender)
var age int8
fmt.Printf("请输入客户年龄(%d):", cs.customers[updateIndex].Age)
fmt.Scanln(&age)
var email string
fmt.Printf("请输入客户邮箱(%s):", cs.customers[updateIndex].Email)
fmt.Scanln(&email)
if age != 0 {
cs.customers[updateIndex].Age = age
}
if name != "" {
cs.customers[updateIndex].Name = name
}
if gender != "" {
cs.customers[updateIndex].Gender = gender
}
if email != "" {
cs.customers[updateIndex].Email = email
}
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改完成----------------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) deleteCustomer() {
for true {
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户开始----------------------------")
var delCid int
fmt.Print("请输入删除客户编号:")
fmt.Scan(&delCid)
delIndex := cs.findById(delCid)
if delIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
cs.customers = append(cs.customers[:delIndex], cs.customers[delIndex+1:]...)
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户完成----------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) keepCustomers() {
customersJsonBytes, _ := json.Marshal(cs.customers)
err := ioutil.WriteFile("customers.json", customersJsonBytes, 0666)
if err != nil {
return
}
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------保存完成----------------------")
}
func main() {
var customers []Customer
customersJsonBytes, err := ioutil.ReadFile("customers.json")
if err != nil {
return
}
json.Unmarshal(customersJsonBytes, &customers)
cs := NewCustomerService(customers, customers[len(customers)-1].Cid)
for true {
fmt.Printf("\033[1;30;42m%s\033[0m\n", `
----------------客户信息管理系统--------------
1、添加客户
2、查看客户
3、更新客户
4、删除客户
5、保存
6、退出
-------------------------------------------
`)
var choice int
fmt.Printf("\033[1;38;40m%s\033[0m", "请输入选择【1-5】:")
stdin := bufio.NewReader(os.Stdin)
fmt.Fscan(stdin, &choice)
switch choice {
case 1:
cs.addCustomer()
case 2:
cs.listCustomer()
case 3:
cs.updateCustomer()
case 4:
cs.deleteCustomer()
case 5:
cs.keepCustomers()
case 6:
os.Exit(0)
default:
fmt.Println("按要求输入数字,请重新输入")
}
}
}
|
十、接口(interface)
10.1、楔子
10.1.1 、多态的含义
在java里,多态是同一个行为具有不同表现形式或形态的能力,即对象多种表现形式的体现,就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
如下图所示:使用手机扫描二维码支付时,二维码并不知道客户是通过何种方式进行支付,只有通过二维码后才能判断是走哪种支付方式执行对应流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
// 支付抽象类或者接口
public class Pay {
public String pay() {
System.out.println("do nothing!")
return "success"
}
}
// 支付宝支付
public class AliPay extends Pay {
@Override
public String pay() {
System.out.println("支付宝pay");
return "success";
}
}
// 微信支付
public class WeixinPay extends Pay {
@Override
public String pay() {
System.out.println("微信Pay");
return "success";
}
}
// 银联支付
public class YinlianPay extends Pay {
@Override
public String pay() {
System.out.println("银联支付");
return "success";
}
}
// 测试支付
public static void main(String[] args) {
// 测试支付宝支付多态应用
Pay pay = new AliPay();
pay.pay();
// 测试微信支付多态应用
pay = new WeixinPay();
pay.pay();
// 测试银联支付多态应用
pay = new YinlianPay();
pay.pay();
}
// 输出结果如下:
支付宝pay
微信Pay
银联支付
|
多态存在的三个必要条件:
比如:
1
|
Pay pay = new AliPay();
|
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误;如果有,再去调用子类的同名方法。
10.1.2、抽象类与接口
这样实现当然是可行的,但其实有一个小小的问题,就是Pay类当中的pay方法多余了。因为我们使用的只会是它的子类,并不会用到Pay这个父类。所以我们没必要实现父类Pay中的pay方法,做一个标记,表示有这么一个方法**,子类实现的时候需要实现它就可以了。
这就是抽象类和抽象方法的来源,我们可以把Pay做成一个抽象类,声明pay是一个抽象方法。抽象类是不能直接创建实例的,只能创建子类的实例,并且抽象方法也不用实现,只需要标记好参数和返回就行了。具体的实现都在子类当中进行。说白了抽象方法就是一个标记,告诉编译器凡是继承了这个类的子类必须要实现抽象方法,父类当中的方法不能调用。那抽象类就是含有抽象方法的类。
我们写出Pay变成抽象类之后的代码:
1
2
3
|
public abstract class Pay {
abstract public String pay();
}
|
很简单,因为我们只需要定义方法的参数就可以了,不需要实现方法的功能,方法的功能在子类当中实现。由于我们标记了pay这个方法是一个抽象方法,凡是继承了Pay的子类都必须要实现这个方法,否则一定会报错。
抽象类其实是一个擦边球,我们可以在抽象类中定义抽象的方法也就是只声明不实现,也可以在抽象类中实现具体的方法。在抽象类当中非抽象的方法,子类的实例是可以直接调用的,和子类调用父类的普通方法一样。但假如我们不需要父类实现方法,我们提出提取出来的父类中的所有方法都是抽象的呢?针对这一种情况,Java当中还有一个概念叫做接口,也就是interface,本质上来说interface就是抽象类,只不过是只有抽象方法的抽象类。
所以刚才的Pay通过接口实现如下:
1
2
3
|
interface Pay {
String pay();
}
|
把Pay变成了interface之后,子类的实现没什么太大的差别,只不过将extends关键字换成了implements。另外,子类只能继承一个抽象类,但是可以实现多个接口。早先的Java版本当中,interface只能够定义方法和常量,在Java8以后的版本当中,我们也可以在接口当中实现一些默认方法和静态方法。
接口的好处是很明显的,我们可以用接口的实例来调用所有实现了这个接口的类。也就是说接口和它的实现是一种要宽泛许多的继承关系,大大增加了灵活性。
以上虽然全是Java的内容,但是讲的其实是面向对象的内容,如果没有学过Java的小伙伴可能看起来稍稍有一点点吃力,但总体来说问题不大,没必要细扣当中的语法细节,get到核心精髓就可以了。
10.1.3、Go中的接口实现
Golang当中也有接口,但是它的理念和使用方法和Java稍稍有所不同,它们的使用场景以及实现的目的是类似的,本质上都是为了抽象。通过接口提取出了一些方法,所有继承了这个接口的类都必然带有这些方法,那么我们通过接口获取这些类的实例就可以使用了,大大增加了灵活性。
但是Java当中的接口有一个很大的问题就是侵入性,Golang当中的接口解决了这个问题,也就是说它完全拿掉了原本弱化的继承关系,只要接口中定义的方法能对应的上,那么就可以认为这个类实现了这个接口。
我们先来创建一个interface,当然也是通过type关键字:
1
2
3
|
type Pay interface {
pay() string
}
|
我们定义了一个Pay的接口,当中声明了一个pay函数。也就是说只要是拥有这个函数的结构体就可以用这个接口来接收
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
type AliPay struct{}
type WeixinPay struct{}
type YinlianPay struct{}
func (a AliPay) pay() {
fmt.Println("支付宝pay")
}
func (w WeixinPay) pay() {
fmt.Println("微信pay")
}
func (y YinlianPay) pay() {
fmt.Println("银联pay")
}
|
之后,我们尝试使用这个接口来接收各种结构体的对象,然后调用它们的pay方法:
1
2
3
4
5
6
7
8
9
|
func main() {
var p Pay
p = AliPay{}
p.pay()
p = WeixinPay{}
p.pay()
p = YinlianPay{}
p.pay()
}
|
出来的结果是一样的!
golang中的接口设计非常出色,因为它解耦了接口和实现类之间的联系,使得进一步增加了我们编码的灵活度,解决了供需关系颠倒的问题。但是世上没有绝对的好坏,golang中的接口在方便了我们编码的同时也带来了一些问题,比如说由于没了接口和实现类的强绑定,其实也一定程度上增加了开发和维护的成本。
总体来说这是一个仁者见仁的改动,有些写惯了Java的同学可能会觉得没有必要,这是过度解绑,有些人之前深受其害的同学可能觉得这个进步非常关键。但不论你怎么看,这都不影响我们学习它,毕竟学习本身是不带立场的。
接口本身就是一种规范,能让大家在一个框架下开发,比如张三新进入部门,开发一个新的支付功能,在接口的限制下,开发就会会规范很多。就像USB接口一样,定义统一接口,无论外部实现的是音响还是硬盘,必须都按定义好的数据格式开发。
10.2、Go的接口语法
10.2.1、基本语法
在 Golang 中,interface 是一组 method 的集合,是 duck-type programming 的一种体现。不关心属性(数据),只关心行为(方法)。具体使用中你可以自定义自己的 struct,并提供特定的 interface 里面的 method 就可以把它当成 interface 来使用。
if something looks like a duck, swims like a duck and quacks like a duck then it’s probably a duck.
每个接口由数个方法组成,接口的定义格式如下:
1
2
3
4
5
|
type 接口类型名 interface{
方法名1( 参数列表1 ) 返回值列表1
方法名2( 参数列表2 ) 返回值列表2
…
}
|
其中:
- 接口名:使用
type将接口定义为自定义的类型名。Go语言的接口在命名时,一般会在单词后面添加er,如有写操作的接口叫Writer,有字符串功能的接口叫Stringer等。接口名最好要能突出该接口的类型含义。
- 方法名:当方法名首字母是大写且这个接口类型名首字母也是大写时,这个方法可以被接口所在的包(package)之外的代码访问。
- 参数列表、返回值列表:参数列表和返回值列表中的参数变量名可以省略。
10.2.2、实现接口的条件
一个对象只要全部实现了接口中的方法,那么就实现了这个接口。换句话说,接口就是一个需要实现的方法列表。
我们来定义一个Animal接口:
1
2
3
4
|
// Animal 接口
type Animal interface {
sleep()
}
|
定义Dog和Cat两个结构体:
1
2
3
4
5
6
|
type Dog struct {
name string
}
type Cat struct {
name string
}
|
因为Animal接口里只有一个sleep方法,所以我们只需要给Dog和Cat 类分别实现sleep方法就可以实现Sayer接口了。
1
2
3
4
5
6
7
8
|
// Dog实现了Animal接口
func (d Dog) sleep() {
fmt.Printf("%s正在侧卧着睡觉\n", d.name)
}
// Cat实现了Animal接口
func (c Cat) sleep() {
fmt.Printf("%s正在卷成团睡觉\n", c.name)
}
|
接口的实现就是这么简单,只要实现了接口中的所有方法,就实现了这个接口。
10.2.3、接口类型变量
那实现了接口有什么用呢?
接口类型变量能够存储所有实现了该接口的实例。 例如上面的示例中,Animal类型的变量能够存储Dog和Cat类型的变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func foo(animal Animal) {
animal.sleep()
}
func main() {
var a Animal
var d = Dog{"川普"}
var c = Cat{"拜登"}
// 案例1
a = d
a.sleep()
a = c
a.sleep()
// 案例2
foo(d)
foo(c)
}
|
10.2.4、值和指针接收者实现接口
使用值接收者实现接口和使用指针接收者实现接口有什么区别呢?接下来我们通过一个例子看一下其中的区别。
(1)值接收者实现接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import (
"fmt"
)
type Animal interface {
sleep()
}
type Dog struct {
name string
}
// Dog实现了Animal接口
func (d Dog) sleep() {
fmt.Printf("%s正在侧卧着睡觉\n", d.name)
}
func main() {
var a Animal
var chuanPu = Dog{"川普"}
a = chuanPu // a可以接收Dog类型
chuanPu.sleep() // 将Dog类型chuanPu拷贝给接收者方法sleep的d,然后执行sleep方法
a = &chuanPu // a可以接受*Dog类型
a.sleep() //将*Dog类型chuanPu取值操作后拷贝给接收者方法sleep的d,然后执行sleep方法
}
|
从上面的代码中我们可以发现,使用值接收者实现接口之后,不管是Dog结构体对象还是结构体指针对象都可以赋值给该接口变量。因为Go语言中有对指针类型变量求值的语法糖,Dog指针a内部会自动求值川普结构体对象然后拷贝赋值。
(2)指针接收者实现接口
同样的代码我们再来测试一下使用指针接收者有什么区别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
package main
import (
"fmt"
)
type Animal interface {
sleep()
}
type Dog struct {
name string
}
// Dog实现了Animal接口
func (d *Dog) sleep() {
fmt.Printf("%s正在侧卧着睡觉\n", d.name)
}
func main() {
var a Animal
var chuanPu = Dog{"川普"}
// a = chuanPu // a不可以接收Dog类型
a = &chuanPu // a只可以接收*Dog类型
a.sleep()
}
|
此时实现Animal的接口的是*Dog类型,所以不能给a传入Dog类型的chuanPu,此时a只能存储*Dog类型的值,即&chuanPu。
10.2.5、类型与接口的关系
(1)一个类型实现多个接口
一个类型可以同时实现多个接口,而接口间彼此独立,不知道对方的实现。 例如,狗可以跑,也可以叫。我们就分别定义Runner接口和Sayer接口。
1
2
3
4
5
6
7
8
9
|
// Sayer 接口
type Sayer interface {
say()
}
// Runner 接口
type Runner interface {
run()
}
|
Dog既可以实现Sleep接口,也可以实现Run接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package main
import (
"fmt"
)
// Sayer 接口
type Sayer interface {
say()
}
// Runner 接口
type Runner interface {
run()
}
type Dog struct {
name string
}
// 实现Sayer接口
func (d Dog) say() {
fmt.Printf("%s汪汪汪叫\n", d.name)
}
// 实现Runner接口
func (d Dog) run() {
fmt.Printf("%s吐舌头跑\n", d.name)
}
func main() {
var s Sayer
var r Runner
var d = Dog{name: "旺财"}
s = d
s.say()
r = d
r.run()
}
|
(2)多个类型实现同一接口
Go语言中不同的类型还可以实现同一接口 首先我们定义一个Runner接口,它要求必须有一个run方法。
1
2
3
4
|
// Runner 接口
type Runner interface {
run()
}
|
例如狗可以跑,汽车也可以跑,可以使用如下代码实现这个关系:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
type Car struct {
brand string
}
type Dog struct {
name string
}
// Runner 接口
type Runner interface {
run()
}
// Dog实现Runner接口
func (d Dog) run() {
fmt.Printf("%s正在吐舌头跑\n", d.name)
}
// Car实现Runner接口
func (c Car) run() {
fmt.Printf("%s正在飞速行驶\n", c.brand)
}
|
这个时候我们在代码中就可以把狗和汽车当成一个会动的物体来处理了,不再需要关注它们具体是什么,只需要调用它们的move方法就可以了。
1
2
3
4
5
6
7
8
9
10
|
func main() {
var r Runner
var d = Dog{name: "旺财"}
var c = Car{brand: "奔驰"}
r = d
r.run()
r = c
r.run()
}
|
10.2.6、类型嵌套
一个类型(struct)必须实现了接口中的所有方法才能称为实现了该接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
// Animal 接口
type Animal interface {
sleep()
run()
}
type Dog struct {
name string
}
// Dog实现了run方法和sleep方法,即实现了Animal接口
func (d Dog) run() {
fmt.Printf("%s正在吐舌头跑\n", d.name)
}
/*func (d Dog) sleep() {
fmt.Printf("%s正在侧翻睡\n", d.name)
}*/
func main() {
var r Animal
var d = Dog{name: "旺财"}
r = d
r.run()
}
|
一个接口的方法,不一定需要由一个类型完全实现,接口的方法可以通过在类型中嵌入其他类型或者结构体来实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
package main
import (
"fmt"
)
// WashingMachine 洗衣机
type WashingMachine interface {
wash()
dry()
}
// 甩干器
type Dryer struct{
brand string
}
// 实现WashingMachine接口的dry()方法
func (d Dryer) dry() {
fmt.Println("甩干衣服")
}
// 海尔洗衣机
type Haier struct {
name string
Dryer //嵌入甩干器
}
// 实现WashingMachine接口的wash()方法
func (h Haier) wash() {
fmt.Println("洗衣服")
}
func main() {
var wm WashingMachine
wm = Haier{
name: "海尔洗衣机",
Dryer:Dryer{
brand:"西门子",
},
}
wm.wash()
wm.dry()
}
|
10.2.7、接口嵌套
接口与接口间可以通过嵌套创造出新的接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
package main
import (
"fmt"
)
// Animal 接口
/*type Animal interface {
sleep()
run()
}*/
// Sleep接口
type Sleep interface {
sleep()
}
// Runner接口
type Runner interface {
run()
}
// Animal接口
type Animal interface {
Sleep
Runner
}
type Dog struct {
name string
}
// Dog实现了run方法和sleep方法,即实现了Animal接口
func (d Dog) run() {
fmt.Printf("%s正在吐舌头跑\n", d.name)
}
func (d Dog) sleep() {
fmt.Printf("%s正在侧翻睡\n", d.name)
}
func main() {
var r Animal
var d = Dog{name: "旺财"}
r = d
r.run()
r.sleep()
}
|
10.2.8、空接口
(1)空接口的定义
空接口是指没有定义任何方法的接口。因此任何类型都实现了空接口。
空接口类型的变量可以存储任意类型的变量。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
func main() {
// 定义一个空接口x
var x interface{}
s := "Hello Yuan"
x = s
fmt.Printf("type:%T value:%v\n", x, x)
i := 100
x = i
fmt.Printf("type:%T value:%v\n", x, x)
b := true
x = b
fmt.Printf("type:%T value:%v\n", x, x)
}
|
(2)空接口的应用
使用空接口实现可以接收任意类型的函数参数。
1
2
3
4
|
// 空接口作为函数参数
func show(a interface{}) {
fmt.Printf("type:%T value:%v\n", a, a)
}
|
使用空接口实现可以保存任意值的字典。
1
2
3
4
5
6
|
// 空接口作为map值
var studentInfo = make(map[string]interface{})
studentInfo["name"] = "yuan"
studentInfo["age"] = 18
studentInfo["isMarried"] = false
fmt.Println(studentInfo)
|
一个接口的值(简称接口值)是由一个具体类型和具体类型的值两部分组成的。这两部分分别称为接口的动态类型和动态值。
想要判断空接口中的值这个时候就可以使用类型断言,其语法格式:
其中:
- x:表示类型为
interface{}的变量
- T:表示断言
x可能是的类型。
该语法返回两个参数,第一个参数是x转化为T类型后的变量,第二个值是一个布尔值,若为true则表示断言成功,为false则表示断言失败。
举个例子:
1
2
3
4
5
6
7
8
9
10
|
func main() {
var x interface{}
x = "Hello Yuan!"
v, ok := x.(string)
if ok {
fmt.Println(v)
} else {
fmt.Println("类型断言失败")
}
}
|
上面的示例中如果要断言多次就需要写多个if判断,这个时候我们可以使用switch语句来实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func justifyType(x interface{}) {
switch v := x.(type) {
case string:
fmt.Printf("x is a string类型,value is %v\n", v)
case int:
fmt.Printf("x is a int类型, value is %v\n", v)
case bool:
fmt.Printf("x is a bool类型,value is %v\n", v)
default:
fmt.Println("unsupport type!")
}
}
func main() {
justifyType(12)
justifyType(true)
justifyType("hi,yuan!")
}
|
因为空接口可以存储任意类型值的特点,所以空接口在Go语言中的使用十分广泛。
关于接口需要注意的是,只有当有两个或两个以上的具体类型必须以相同的方式进行处理时才需要定义接口。不要为了接口而写接口,那样只会增加不必要的抽象,导致不必要的运行时损耗。
十一、包管理

11.1、package
Go语言是使用包来组织源代码的,包(package)是多个 Go 源码的集合,是一种高级的代码复用方案。Go语言中为我们提供了很多内置包,如 fmt、os、io 等。任何源代码文件必须属于某个包,同时源码文件的第一行有效代码必须是package pacakgeName 语句,通过该语句声明自己所在的包。
Go语言的包借助了目录树的组织形式,一般包的名称就是其源文件所在目录的名称,虽然Go语言没有强制要求包名必须和其所在的目录名同名,但还是建议包名和所在目录同名,这样结构更清晰。
11.1.1、包的基本使用
导入包的语法:
导入包路径规则:
Go 程序首先在 GOROOT/src 目录中寻找包目录,如果没有找到,则会去 GOPATH/src 目录中继续寻找。比如 fmt 包是位于 GOROOT/src 目录的 Go 语言标准库中的一部分,它将会从该目录中导入。
目录结构
db包
1
2
3
4
5
6
7
|
package db
import "fmt"
func HandleMySQL() {
fmt.Println("操作MySQL数据库")
}
|
1
2
3
4
5
6
7
|
package db
import "fmt"
func HandleRedis() {
fmt.Println("操作redis数据库")
}
|
api包
1
2
3
4
5
6
7
8
9
|
package api
import "fmt"
import "mysite/db"
func RestfulAPI() {
db.HandleMySQL()
fmt.Println("RestfulAPI:MySQL数据接口")
}
|
1
2
3
4
5
6
7
8
9
|
package api
import "fmt"
import "mysite/db"
func RpcAPI() {
db.HandleRedis()
fmt.Println("RpcAPI:redis数据接口")
}
|
main包
1
2
3
4
5
6
7
8
9
10
11
12
|
package main
import "mysite/api"
func main() {
// db.HandleMySQL()
// db.HandleRedis()
api.RestfulAPI()
api.RpcAPI()
}
|
1、包名一般是小写的,见名知意,包名中不能包含- 等特殊符号。
2、包名规范上要和所在的目录同名,也可以不同。比如package api改为package newApi,代码改动为
1
2
3
4
5
6
7
8
|
package main
import newApi "mysite/api"
func main() {
newApi.RestfulAPI()
newApi.RpcAPI()
}
|
3、包名为 main 的包为应用程序的入口包,编译不包含 main 包的源码文件时不会得到可执行文件。
4、一个文件夹下的所有源码文件只能属于同一个包,同样属于同一个包的源码文件不能放在多个文件夹下。
5、一个包下的不同文件不能含有同名函数。
6、如果想在一个包中引用另外一个包里的标识符(如变量、常量、类型、函数等)时,该标识符必须是对外可见的(public),在Go语言中只需要将标识符的首字母大写就可以让标识符对外可见了。
7、环境变量GO111MODULE=off: go env -w GO111MODULE=off
8、将mysite剪切到src外的任何位置,都会导包失败。
11.1.2、包的导入格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
// 一次导入多个包
import (
"fmt"
"mysite/api"
)
// 设置包的别名
import F "fmt"
// 省略引用格式
import . "mysite/api"
RestfulAPI()
// 匿名导入 :在引用某个包时,如果只是希望执行包初始化的 init 函数,而不使用包内部的数据时,可以使用匿名引用格式
import _ "包名"
import (
"database/sql"
_ "github.com/go-sql-driver/mysql"
)
|
11.1.3、包的加载顺序
init()函数会在每个包完成初始化后自动执行,并且执行优先级比main函数高。
init 函数通常被用来:
- 对变量进行初始化
- 检查/修复程序的状态
- 注册
- 运行一次计算
注意:
1、一个包可以有多个 init 函数,包加载时会执行全部的 init 函数,但并不能保证执行顺序,所以不建议在一个包中放入多个 init 函数,将需要初始化的逻辑放到一个 init 函数里面。
2、包不能出现环形引用的情况,比如包 a 引用了包 b,包 b 引用了包 c,如果包 c 又引用了包 a,则编译不能通过。
3、包的重复引用是允许的,比如包 a 引用了包 b 和包 c,包 b 和包 c 都引用了包 d。这种场景相当于重复引用了 d,这种情况是允许的,并且 Go 编译器保证包 d 的 init 函数 只会执行一次。
4、init()函数没有参数也没有返回值。 init()函数在程序运行时自动被调用执行,不能在代码中主动调用它。
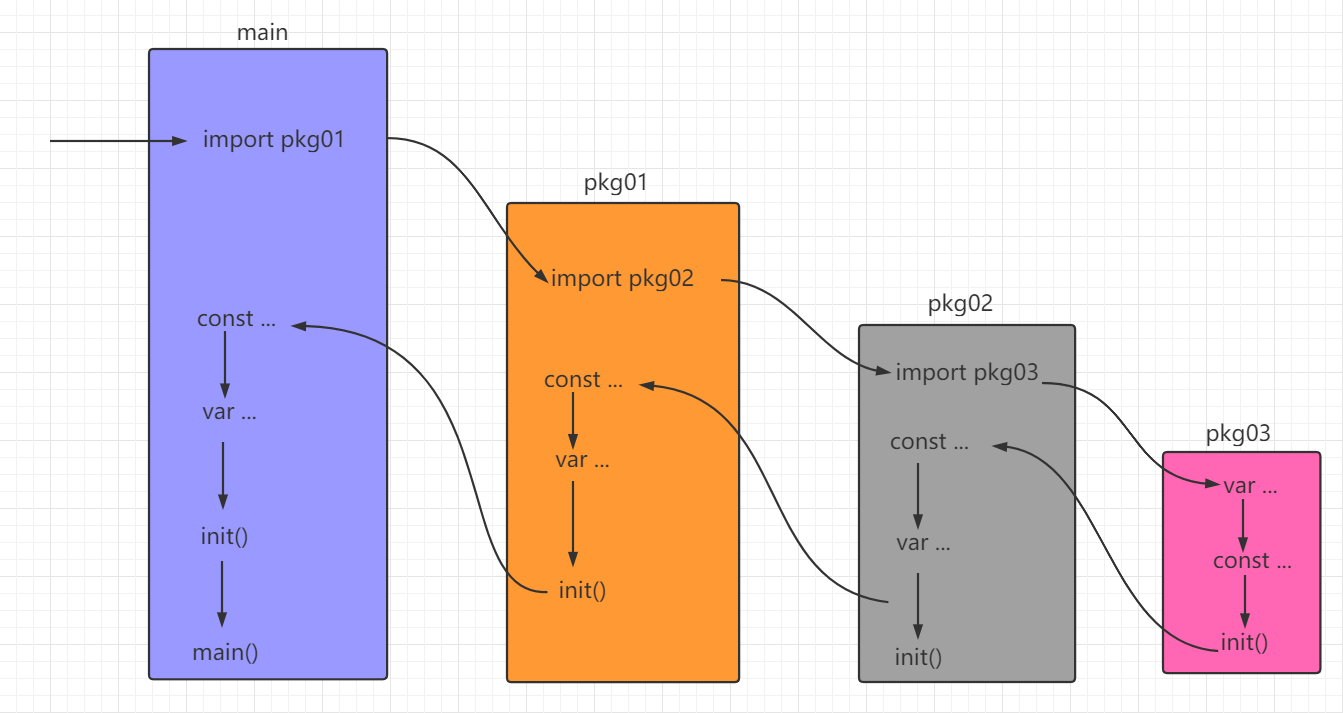
11.2、go module
module是一个相关Go包的集合,它是源代码更替和版本控制的单元。
11.2.1、Go mod命令
1
2
3
4
5
6
7
8
9
|
/*
download download modules to local cache (下载依赖的module到本地cache))
edit edit go.mod from tools or scripts (编辑go.mod文件)
graph print module requirement graph (打印模块依赖图))
init initialize new module in current directory (再当前文件夹下初始化一个新的module, 创建go.mod文件))
tidy add missing and remove unused modules (增加丢失的module,去掉未用的module)
vendor make vendored copy of dependencies (将依赖复制到vendor下)
verify verify dependencies have expected content (校验依赖)
why explain why packages or modules are needed (解释为什么需要依赖)*/
|
Mod Cache 路径默认在$GOPATH/pkg 下面:$GOPATH/pkg/mod
11.2.2、go mod流程
同样是mysite项目,现在从src中剪切到其它任何位置,会编译报错。用go module来解决这个问题。
(1) 首先将你的版本更新到最新的Go版本(>=1.11)
(2)通过go命令行,进入到你当前的工程目录下,在命令行设置临时环境变量go env -w GO111MODULE=off
(3)go mod init在当前目录下生成一个go.mod文件,执行这条命令时,当前目录不能存在go.mod文件(有删除)。
1
|
go mod init xxx // xxx即声明的模块名
|
该命令会在当前目录下生成go.mod文件,文件中声明了模块名称。
以后相关依赖可以声明在这里,就像python的requirements。
此时运行程序,会将相关的依赖直接下载到GOPATH/pkg/mod路径下。
(4)执行go mod tidy命令,它会添加缺失的模块以及移除不需要的模块
执行后会生成go.sum文件(模块下载条目)。添加参数-v,例如go mod tidy -v可以将执行的信息,即删除和添加的包打印到命令行;
将拉取的依赖存放到GOPATH/pkg/mod路径下。
(5)执行命令go mod verify来检查当前模块的依赖是否全部下载下来,是否下载下来被修改过。如果所有的模块都没有被修改过,那么执行这条命令之后,会打印all modules verified。
(6)执行命令go mod vendor生成vendor文件夹,用来区分某些库的不同版本。该文件夹下将会放置你go.mod文件描述的依赖包,文件夹下同时还有一个文件modules.txt,它是你整个工程的所有模块。在执行这条命令之前,如果你工程之前有vendor目录,应该先进行删除。同理go mod vendor -v会将添加到vendor中的模块打印出来;
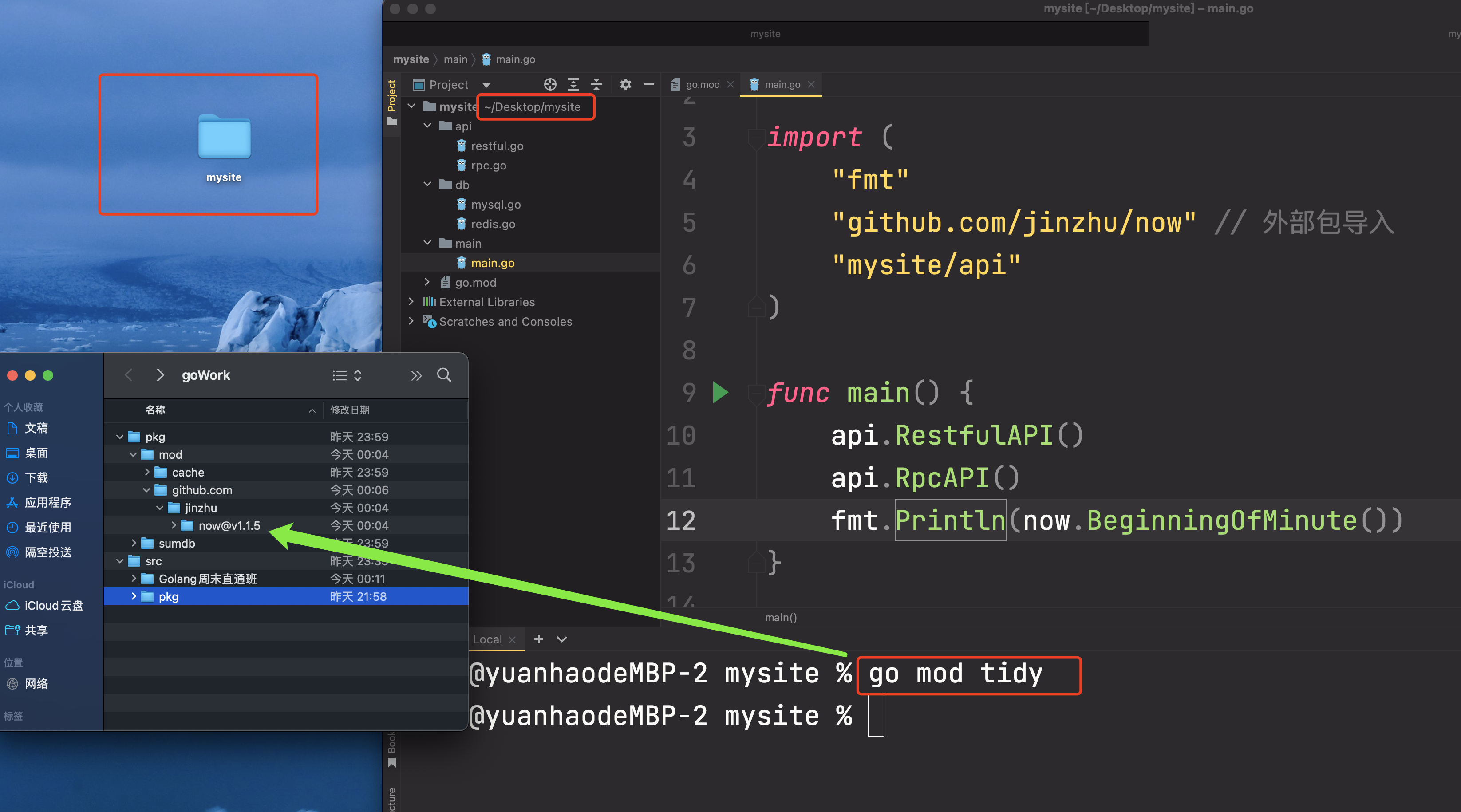
内部包调用从初始化模块名go.mod所在的目录开始查找,所以导入api包:import "xxx/api"
11.3、章节作业
将客户关系管理系统改为包管理版本

版本1
目录结构:
model包的customer.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package model
type Customer struct {
Cid int
Name string
Gender string
Age int8
Email string
}
func NewCustomer(cid int, name string, gender string, age int8, email string) Customer {
return Customer{
Cid: cid,
Name: name,
Gender: gender,
Age: age,
Email: email,
}
}
|
service包的costumerService.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
|
package service
import (
"customerSys/model"
"encoding/json"
"fmt"
"io/ioutil"
"os"
"strings"
)
type CustomerService struct {
customers []model.Customer
customersId int
}
func NewCustomerService(customers []model.Customer, customersId int) CustomerService {
return CustomerService{customers, customersId}
}
func (cs *CustomerService) findById(id int) int {
index := -1
for i := 0; i < len(cs.customers); i++ {
if cs.customers[i].Cid == id {
index = i
}
}
return index
}
func (cs *CustomerService) nextChoice() (b bool) {
// 引导用户选择继续还是返回
fmt.Print("返回上一层【回车】,继续该操作【C/c】,退出【Q/q】:")
var backChoice string
fmt.Scanln(&backChoice)
if strings.ToUpper(backChoice) == "C" {
b = true
} else if strings.ToUpper(backChoice) == "Q" {
os.Exit(0)
}
return
}
func (cs *CustomerService) AddCustomer() {
for true {
// 引导用户输入学号和姓名
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户开始-----------------------------")
// 引导用户输入
var name string
fmt.Print("请输入客户姓名:")
fmt.Scan(&name)
var gender string
fmt.Print("请输入客户性别:")
fmt.Scan(&gender)
var age int8
fmt.Print("请输入客户年龄:")
fmt.Scan(&age)
var email string
fmt.Print("请输入客户邮箱:")
fmt.Scan(&email)
// 创建客户的map对象
cs.customersId++ // 客户编号不需要输入,系统自增即可
newCustomer := model.NewCustomer(cs.customersId, name, gender, age, email)
// 添加客户map对象添加到客户切片中
cs.customers = append(cs.customers, newCustomer)
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户完成-----------------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) ListCustomer() {
for true {
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表开始----------------------------")
for _, customer := range cs.customers {
fmt.Printf("\u001B[1;39;45m编号:%-8d 姓名:%-8s 性别:%-8s 年龄:%-8d 邮箱:%-10s \u001B[0m\n",
customer.Cid, customer.Name, customer.Gender, customer.Age, customer.Email)
}
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表完成----------------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) UpdateCustomer() {
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改开始----------------------------")
for true {
var updateCid int
fmt.Print("请输入更新客户编号(-1退出):")
fmt.Scan(&updateCid)
if updateCid == -1 {
return
}
updateIndex := cs.findById(updateCid)
if updateIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
// 引导用户输入
var name string
fmt.Printf("请输入客户姓名(%s):", cs.customers[updateIndex].Name)
fmt.Scanln(&name)
var gender string
fmt.Printf("请输入客户性别(%s):", cs.customers[updateIndex].Gender)
fmt.Scanln(&gender)
var age int8
fmt.Printf("请输入客户年龄(%d):", cs.customers[updateIndex].Age)
fmt.Scanln(&age)
var email string
fmt.Printf("请输入客户邮箱(%s):", cs.customers[updateIndex].Email)
fmt.Scanln(&email)
if age != 0 {
cs.customers[updateIndex].Age = age
}
if name != "" {
cs.customers[updateIndex].Name = name
}
if gender != "" {
cs.customers[updateIndex].Gender = gender
}
if email != "" {
cs.customers[updateIndex].Email = email
}
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改完成----------------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) DeleteCustomer() {
for true {
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户开始----------------------------")
var delCid int
fmt.Print("请输入删除客户编号:")
fmt.Scan(&delCid)
delIndex := cs.findById(delCid)
if delIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
cs.customers = append(cs.customers[:delIndex], cs.customers[delIndex+1:]...)
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户完成----------------------")
goOn := cs.nextChoice()
if !goOn {
break
}
}
}
func (cs *CustomerService) KeepCustomers() {
customersJsonBytes, _ := json.Marshal(cs.customers)
err := ioutil.WriteFile("db/customers.json", customersJsonBytes, 0666)
if err != nil {
return
}
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------保存完成----------------------")
}
|
main包main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
package main
import (
"bufio"
"customerSys/model"
"customerSys/service"
"encoding/json"
"fmt"
"io/ioutil"
"os"
)
func main() {
var customers []model.Customer
customersJsonBytes, err := ioutil.ReadFile("db/customers.json")
if err != nil {
fmt.Println("err:", err)
}
json.Unmarshal(customersJsonBytes, &customers)
cs := service.NewCustomerService(customers, customers[len(customers)-1].Cid)
for true {
fmt.Printf("\033[1;30;42m%s\033[0m\n", `
----------------客户信息管理系统--------------
1、添加客户
2、查看客户
3、更新客户
4、删除客户
5、保存
6、退出
-------------------------------------------
`)
var choice int
fmt.Printf("\033[1;38;40m%s\033[0m", "请输入选择【1-5】:")
stdin := bufio.NewReader(os.Stdin)
fmt.Fscan(stdin, &choice)
switch choice {
case 1:
cs.AddCustomer()
case 2:
cs.ListCustomer()
case 3:
cs.UpdateCustomer()
case 4:
cs.DeleteCustomer()
case 5:
cs.KeepCustomers()
case 6:
os.Exit(0)
default:
fmt.Println("按要求输入数字,请重新输入")
}
}
}
|
版本2:前后端分离版本
目录结构:
model包的customer.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
package model
type Customer struct {
Cid int
Name string
Gender string
Age int8
Email string
}
func NewCustomer(cid int, name string, gender string, age int8, email string) Customer {
return Customer{
Cid: cid,
Name: name,
Gender: gender,
Age: age,
Email: email,
}
}
|
service包的costumerService.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
|
package service
import (
"customerSys2/model"
"encoding/json"
"fmt"
"io/ioutil"
)
type CustomerService struct {
customers []model.Customer
customersId int
}
func NewCustomerService() CustomerService {
var customers []model.Customer
customersJsonBytes, err := ioutil.ReadFile("db/customers.json")
if err != nil {
fmt.Println("err:", err)
}
json.Unmarshal(customersJsonBytes, &customers)
return CustomerService{customers, len(customers) + 1}
}
func (cs *CustomerService) FindById(id int) int {
index := -1
for i := 0; i < len(cs.customers); i++ {
if cs.customers[i].Cid == id {
index = i
}
}
return index
}
func (cs *CustomerService) FindCustomer(id int) *model.Customer {
return &cs.customers[cs.FindById(id)]
}
func (cs *CustomerService) AddCustomer(name string, gender string, age int8, email string) {
// 创建客户的map对象
cs.customersId++ // 客户编号不需要输入,系统自增即可
newCustomer := model.NewCustomer(cs.customersId, name, gender, age, email)
// 添加客户map对象添加到客户切片中
cs.customers = append(cs.customers, newCustomer)
}
func (cs *CustomerService) ListCustomer() []model.Customer {
return cs.customers
}
func (cs *CustomerService) UpdateCustomer(updateCustomer *model.Customer, name string, age int8, gender string, email string) bool {
if age != 0 {
updateCustomer.Age = age
}
if name != "" {
updateCustomer.Name = name
}
if gender != "" {
updateCustomer.Gender = gender
}
if email != "" {
updateCustomer.Email = email
}
return true
}
func (cs *CustomerService) DeleteCustomer(delIndex int) {
cs.customers = append(cs.customers[:delIndex], cs.customers[delIndex+1:]...)
}
func (cs *CustomerService) KeepCustomers() {
customersJsonBytes, _ := json.Marshal(cs.customers)
err := ioutil.WriteFile("db/customers.json", customersJsonBytes, 0666)
if err != nil {
return
}
}
|
view包的costumerView.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
|
package view
import (
"bufio"
"customerSys2/service"
"fmt"
"os"
"strings"
)
type CustomerView struct {
Choice int //接收⽤户输⼊...
CS service.CustomerService
}
func (cv *CustomerView) nextChoice() (b bool) {
// 引导用户选择继续还是返回
fmt.Print("返回上一层【回车】,继续该操作【C/c】,退出【Q/q】:")
var backChoice string
fmt.Scanln(&backChoice)
if strings.ToUpper(backChoice) == "C" {
b = true
} else if strings.ToUpper(backChoice) == "Q" {
os.Exit(0)
}
return
}
func (cv *CustomerView) AddView() {
for true {
// 引导用户输入学号和姓名
fmt.Printf("\033[1;35;40m%s\033[0m\n", "---------------------------添加客户开始-----------------------------")
// 引导用户输入
var name string
fmt.Print("请输入客户姓名:")
fmt.Scan(&name)
var gender string
fmt.Print("请输入客户性别:")
fmt.Scan(&gender)
var age int8
fmt.Print("请输入客户年龄:")
fmt.Scan(&age)
var email string
fmt.Print("请输入客户邮箱:")
fmt.Scan(&email)
// 后端接口调用,实现添加学生的逻辑
cv.CS.AddCustomer(name, gender, age, email)
goOn := cv.nextChoice()
if !goOn {
break
}
}
}
func (cv *CustomerView) ListView() {
for true {
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表开始----------------------------")
for _, customer := range cv.CS.ListCustomer() {
fmt.Printf("\u001B[1;39;45m编号:%-8d 姓名:%-8s 性别:%-8s 年龄:%-8d 邮箱:%-10s \u001B[0m\n",
customer.Cid, customer.Name, customer.Gender, customer.Age, customer.Email)
}
fmt.Printf("\033[1;32;40m%s\033[0m\n", "----------------------------------客户列表完成----------------------------")
goOn := cv.nextChoice()
if !goOn {
break
}
}
}
func (cv *CustomerView) UpdateView() {
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改开始----------------------------")
for true {
var updateCid int
fmt.Print("请输入更新客户编号(-1退出):")
fmt.Scan(&updateCid)
if updateCid == -1 {
return
}
updateIndex := cv.CS.FindById(updateCid)
if updateIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
updateCustomer := cv.CS.FindCustomer(updateCid)
// 引导用户输入
var name string
fmt.Printf("请输入客户姓名(%s):", updateCustomer.Name)
fmt.Scanln(&name)
var gender string
fmt.Printf("请输入客户性别(%s):", updateCustomer.Gender)
fmt.Scanln(&gender)
var age int8
fmt.Printf("请输入客户年龄(%d):", updateCustomer.Age)
fmt.Scanln(&age)
var email string
fmt.Printf("请输入客户邮箱(%s):", updateCustomer.Email)
fmt.Scanln(&email)
// 后端接口调用
cv.CS.UpdateCustomer(updateCustomer, name, age, gender, email)
fmt.Printf("\033[1;36;40m%s\033[0m\n", "---------------------------客户修改完成----------------------------")
goOn := cv.nextChoice()
if !goOn {
break
}
}
}
func (cv *CustomerView) DeleteView() {
for true {
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户开始----------------------------")
var delCid int
fmt.Print("请输入删除客户编号:")
fmt.Scan(&delCid)
delIndex := cv.CS.FindById(delCid)
if delIndex == -1 {
fmt.Println("删除失败,输入的编号ID不存在")
continue
}
cv.CS.DeleteCustomer(delIndex)
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------删除客户完成----------------------")
goOn := cv.nextChoice()
if !goOn {
break
}
}
}
func (cv *CustomerView) KeepView() {
cv.CS.KeepCustomers()
fmt.Printf("\033[1;31;40m%s\033[0m\n", "---------------------------保存完成----------------------")
}
func (cv *CustomerView) MainView() {
for true {
fmt.Printf("\033[1;30;42m%s\033[0m\n", `
----------------客户信息管理系统--------------
1、添加客户
2、查看客户
3、更新客户
4、删除客户
5、保存
6、退出
-------------------------------------------
`)
fmt.Printf("\033[1;38;40m%s\033[0m", "请输入选择【1-5】:")
stdin := bufio.NewReader(os.Stdin)
fmt.Fscan(stdin, &cv.Choice)
switch cv.Choice {
case 1:
cv.AddView()
case 2:
cv.ListView()
case 3:
cv.UpdateView()
case 4:
cv.DeleteView()
case 5:
cv.KeepView()
case 6:
os.Exit(0)
default:
fmt.Println("按要求输入数字,请重新输入")
}
}
}
|
main包main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
package main
import "customerSys2/view"
import "customerSys2/service"
func main() {
cv := view.CustomerView{
Choice: 0,
CS: service.NewCustomerService(),
}
cv.MainView()
}
|
十三、网络编程
网络编程:使用编程语言实现多台计算机的通信。
13.1、网络三要素
网络编程三要素:
(1)IP地址:网络中每一台计算机的唯一标识,通过IP地址找到指定的计算机。
(2)端口:用于标识进程的逻辑地址,通过端口找到指定进程。
(3)协议:定义通信规则,符合协议则可以通信,不符合不能通信。一般有TCP协议和UDP协议。
(1)IP地址
计算机分布在世界各地,要想和它们通信,必须要知道确切的位置。确定计算机位置的方式有多种,IP 地址是最常用的,例如,114.114.114.114 是国内第一个、全球第三个开放的 DNS 服务地址,127.0.0.1 是本机地址。
其实,我们的计算机并不知道 IP 地址对应的地理位置,当要通信时,只是将 IP 地址封装到要发送的数据包中,交给路由器去处理。路由器有非常智能和高效的算法,很快就会找到目标计算机,并将数据包传递给它,完成一次单向通信。
目前大部分软件使用 IPv4 地址,但 IPv6 也正在被人们接受,尤其是在教育网中,已经大量使用。
(2)端口
有了 IP 地址,虽然可以找到目标计算机,但仍然不能进行通信。一台计算机可以同时提供多种网络服务,例如Web服务、FTP服务(文件传输服务)、SMTP服务(邮箱服务)等,仅有 IP 地址,计算机虽然可以正确接收到数据包,但是却不知道要将数据包交给哪个网络程序来处理,所以通信失败。
为了区分不同的网络程序,计算机会为每个网络程序分配一个独一无二的端口号(Port Number),例如,Web服务的端口号是 80,FTP 服务的端口号是 21,SMTP 服务的端口号是 25。
端口(Port)是一个虚拟的、逻辑上的概念。可以将端口理解为一道门,数据通过这道门流入流出,每道门有不同的编号,就是端口号。如下图所示:
(3)协议
协议(Protocol)就是网络通信的约定,通信的双方必须都遵守才能正常收发数据。协议有很多种,例如 TCP、UDP、IP 等,通信的双方必须使用同一协议才能通信。协议是一种规范,由计算机组织制定,规定了很多细节,例如,如何建立连接,如何相互识别等。
协议仅仅是一种规范,必须由计算机软件来实现。例如 IP 协议规定了如何找到目标计算机,那么各个开发商在开发自己的软件时就必须遵守该协议,不能另起炉灶。
所谓协议族(Protocol Family),就是一组协议(多个协议)的统称。最常用的是 TCP/IP 协议族,它包含了 TCP、IP、UDP、Telnet、FTP、SMTP 等上百个互为关联的协议,由于 TCP、IP 是两种常用的底层协议,所以把它们统称为 TCP/IP 协议族。
(4)数据传输方式
计算机之间有很多数据传输方式,各有优缺点,常用的有两种:SOCK_STREAM 和 SOCK_DGRAM。
-
SOCK_STREAM 表示面向连接的数据传输方式。数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送,但效率相对较慢。常见的 http 协议就使用 SOCK_STREAM 传输数据,因为要确保数据的正确性,否则网页不能正常解析。
-
SOCK_DGRAM 表示无连接的数据传输方式。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。因为 SOCK_DGRAM 所做的校验工作少,所以效率比 SOCK_STREAM 高。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
注意:SOCK_DGRAM 没有想象中的糟糕,不会频繁的丢失数据,数据错误只是小概率事件。
有可能多种协议使用同一种数据传输方式,所以在 socket 编程中,需要同时指明数据传输方式和协议。
综上所述:IP地址和端口能够在广袤的互联网中定位到要通信的程序,协议和数据传输方式规定了如何传输数据,有了这些,两台计算机就可以通信了。
13.2、TCP协议
(1)OSI模型
如果你读过计算机专业,或者学习过网络通信,那你一定听说过 OSI 模型,它曾无数次让你头大。OSI 是 Open System Interconnection 的缩写,译为“开放式系统互联”。
OSI 模型把网络通信的工作分为 7 层,从下到上分别是物理层、数据链路层、网络层、传输层、会话层、表示层和应用层。
这个网络模型究竟是干什么呢?简而言之就是进行数据封装的。
当另一台计算机接收到数据包时,会从网络接口层再一层一层往上传输,每传输一层就拆开一层包装,直到最后的应用层,就得到了最原始的数据,这才是程序要使用的数据。
(2)TCP报文格式
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的通信协议,数据在传输前要建立连接,传输完毕后还要断开连接。
客户端在收发数据前要使用 connect() 函数和服务器建立连接。建立连接的目的是保证IP地址、端口、物理链路等正确无误,为数据的传输开辟通道。
TCP建立连接时要传输三个数据包,俗称三次握手(Three-way Handshaking)。可以形象的比喻为下面的对话:
- [Shake 1] 套接字A:“你好,套接字B,我这里有数据要传送给你,建立连接吧。”
- [Shake 2] 套接字B:“好的,我这边已准备就绪。”
- [Shake 3] 套接字A:“谢谢你受理我的请求。”
-
序号:Seq(Sequence Number)序号占32位,用来标识从计算机A发送到计算机B的数据包的序号,计算机发送数据时对此进行标记。
-
确认号:Ack(Acknowledge Number)确认号占32位,客户端和服务器端都可以发送,Ack = Seq + 1。
-
标志位:每个标志位占用1Bit,共有6个,分别为 URG、ACK、PSH、RST、SYN、FIN,具体含义如下:
1
2
3
4
5
6
|
// URG:紧急指针(urgent pointer)有效。
// ACK:确认序号有效。
// PSH:接收方应该尽快将这个报文交给应用层。
// RST:重置连接。
// SYN:建立一个新连接。
// FIN:断开一个连接。
|
(3)TCP/IP三次握手
使用 connect() 建立连接时,客户端和服务器端会相互发送三个数据包,请看下图:
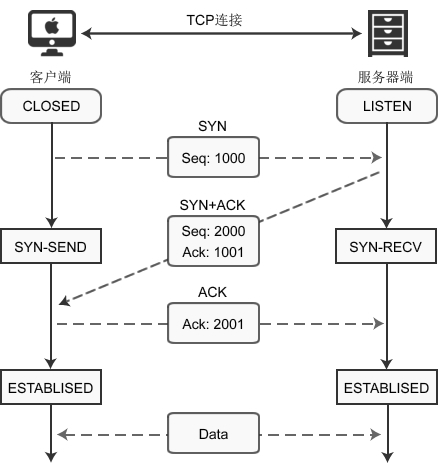
客户端调用 socket() 创建套接字后,因为没有建立连接,所以套接字处于CLOSED状态;服务器端调用 listen() 函数后,套接字进入LISTEN状态,开始监听客户端请求。这个时候,客户端开始发起请求:
-
当客户端调用 connect() 函数后,TCP协议会组建一个数据包,并设置 SYN 标志位,表示该数据包是用来建立同步连接的。同时生成一个随机数字 1000,填充“序号(Seq)”字段,表示该数据包的序号。完成这些工作,开始向服务器端发送数据包,客户端就进入了SYN-SEND状态。
-
服务器端收到数据包,检测到已经设置了 SYN 标志位,就知道这是客户端发来的建立连接的“请求包”。服务器端也会组建一个数据包,并设置 SYN 和 ACK 标志位,SYN 表示该数据包用来建立连接,ACK 用来确认收到了刚才客户端发送的数据包。 服务器生成一个随机数 2000,填充“序号(Seq)”字段。2000 和客户端数据包没有关系。服务器将客户端数据包序号(1000)加1,得到1001,并用这个数字填充“确认号(Ack)”字段。服务器将数据包发出,进入SYN-RECV状态。
-
客户端收到数据包,检测到已经设置了 SYN 和 ACK 标志位,就知道这是服务器发来的“确认包”。客户端会检测“确认号(Ack)”字段,看它的值是否为 1000+1,如果是就说明连接建立成功。接下来,客户端会继续组建数据包,并设置 ACK 标志位,表示客户端正确接收了服务器发来的“确认包”。同时,将刚才服务器发来的数据包序号(2000)加1,得到 2001,并用这个数字来填充“确认(Ack)”字段。客户端将数据包发出,进入ESTABLISED状态,表示连接已经成功建立。
-
服务器端收到数据包,检测到已经设置了 ACK 标志位,就知道这是客户端发来的“确认包”。服务器会检测“确认号(Ack)”字段,看它的值是否为 2000+1,如果是就说明连接建立成功,服务器进入ESTABLISED状态。至此,客户端和服务器都进入了ESTABLISED状态,连接建立成功,接下来就可以收发数据了。
注意:三次握手的关键是要确认对方收到了自己的数据包,这个目标就是通过“确认号(Ack)”字段实现的。计算机会记录下自己发送的数据包序号 Seq,待收到对方的数据包后,检测“确认号(Ack)”字段,看Ack = Seq + 1是否成立,如果成立说明对方正确收到了自己的数据包
(4)TCP/IP四次挥手
建立连接非常重要,它是数据正确传输的前提;断开连接同样重要,它让计算机释放不再使用的资源。如果连接不能正常断开,不仅会造成数据传输错误,还会导致套接字不能关闭,持续占用资源,如果并发量高,服务器压力堪忧。
建立连接需要三次握手,断开连接需要四次握手,可以形象的比喻为下面的对话:
- [Shake 1] 套接字A:“任务处理完毕,我希望断开连接。”
- [Shake 2] 套接字B:“哦,是吗?请稍等,我准备一下。”
- 等待片刻后……
- [Shake 3] 套接字B:“我准备好了,可以断开连接了。”
- [Shake 4] 套接字A:“好的,谢谢合作。”
下图演示了客户端主动断开连接的场景:
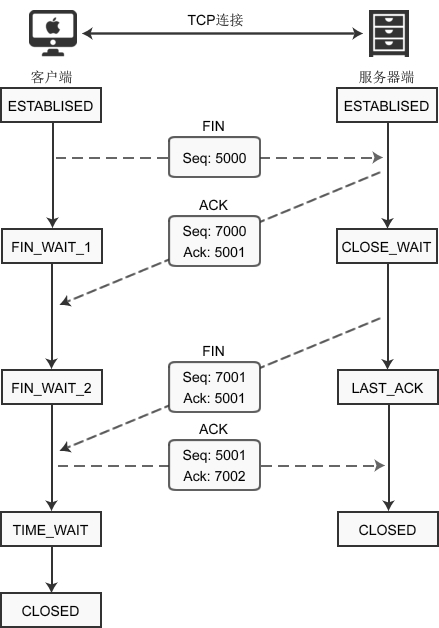
建立连接后,客户端和服务器都处于ESTABLISED状态。这时,客户端发起断开连接的请求:
-
客户端调用 close() 函数后,向服务器发送 FIN 数据包,进入FIN_WAIT_1状态。FIN 是 Finish 的缩写,表示完成任务需要断开连接。
-
服务器收到数据包后,检测到设置了 FIN 标志位,知道要断开连接,于是向客户端发送“确认包”,进入CLOSE_WAIT状态。注意:服务器收到请求后并不是立即断开连接,而是先向客户端发送“确认包”,告诉它我知道了,我需要准备一下才能断开连接。
-
客户端收到“确认包”后进入FIN_WAIT_2状态,等待服务器准备完毕后再次发送数据包。
-
等待片刻后,服务器准备完毕,可以断开连接,于是再主动向客户端发送 FIN 包,告诉它我准备好了,断开连接吧。然后进入LAST_ACK状态。
-
客户端收到服务器的 FIN 包后,再向服务器发送 ACK 包,告诉它你断开连接吧。然后进入TIME_WAIT状态。
-
服务器收到客户端的 ACK 包后,就断开连接,关闭套接字,进入CLOSED状态。
注意:关于 TIME_WAIT 状态的说明
客户端最后一次发送 ACK包后进入 TIME_WAIT 状态,而不是直接进入 CLOSED 状态关闭连接,这是为什么呢?
1
2
3
4
5
6
7
8
|
/*
TCP 是面向连接的传输方式,必须保证数据能够正确到达目标机器,不能丢失或出错,而网络是不稳定的,随时可能会毁坏数据,所以机器A每次向机器B发送数据包后,都要求机器B”确认“,回传ACK包,告诉机器A我收到了,这样机器A才能知道数据传送成功了。
如果机器B没有回传ACK包,机器A会重新发送,直到机器B回传ACK包。
客户端最后一次向服务器回传ACK包时,有可能会因为网络问题导致服务器收不到,服务器会再次发送 FIN 包,如果这时客户端完全关闭了连接,那么服务器无论如何也收不到ACK包了,所以客户端需要等待片刻、确认对方收到ACK包后才能进入CLOSED状态。
那么,要等待多久呢?数据包在网络中是有生存时间的,超过这个时间还未到达目标主机就会被丢弃,并通知源主机。
这称为报文最大生存时间(MSL,Maximum Segment Lifetime)。
TIME_WAIT 要等待 2MSL 才会进入 CLOSED 状态。ACK 包到达服务器需要 MSL 时间,服务器重传 FIN 包也需要 MSL 时间,2MSL 是数据包往返的最大时间,如果 2MSL 后还未收到服务器重传的 FIN 包,就说明服务器已经收到了 ACK 包。
*/
|
13.3、socket介绍
13.3.1、什么是 socket?
socket 的原意是“插座”,在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
我们把插头插到插座上就能从电网获得电力供应,同样,为了与远程计算机进行数据传输,需要连接到因特网,而 socket 就是用来连接到因特网的工具。

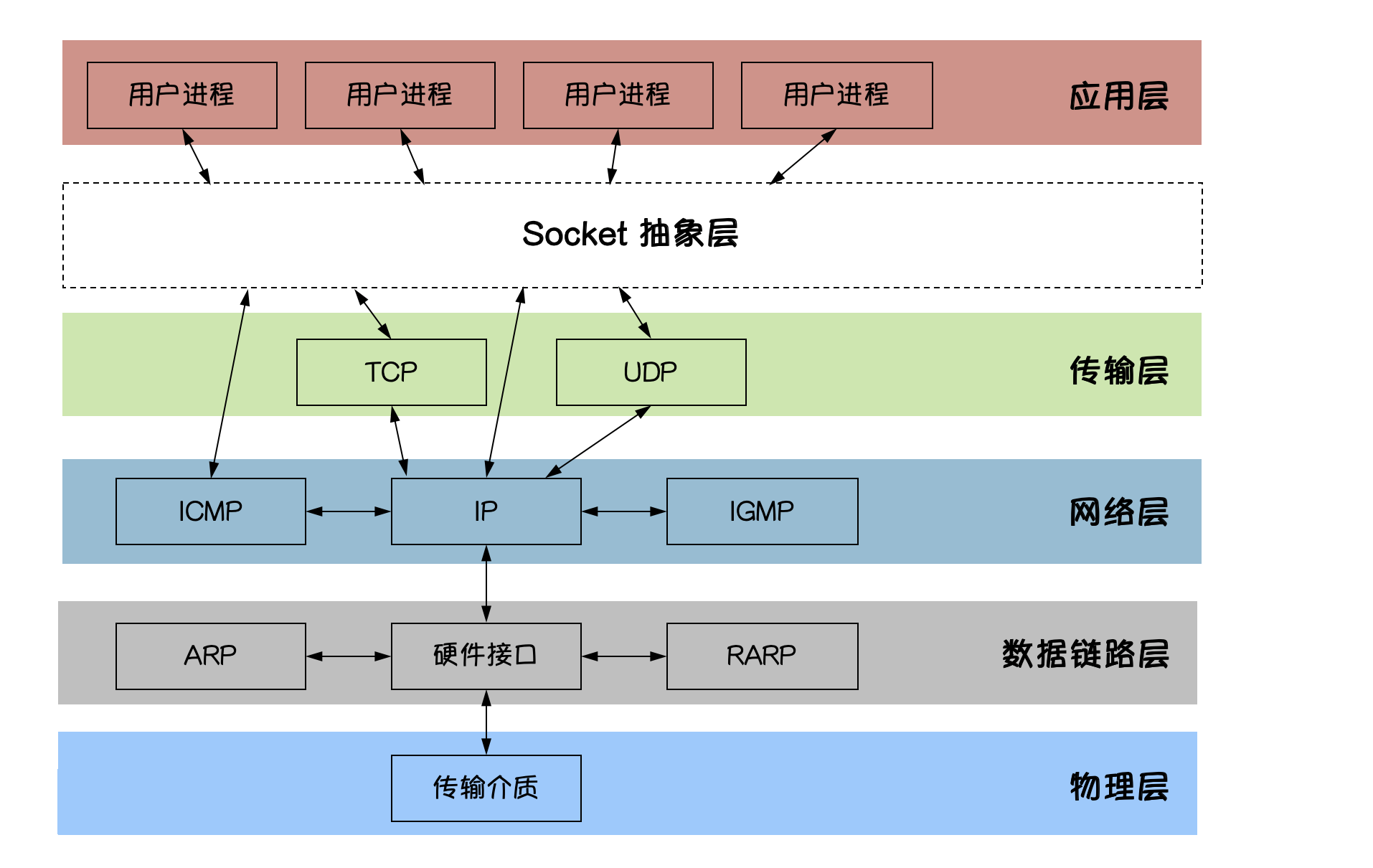
13.3.2、socket缓冲区与阻塞
1、socket缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
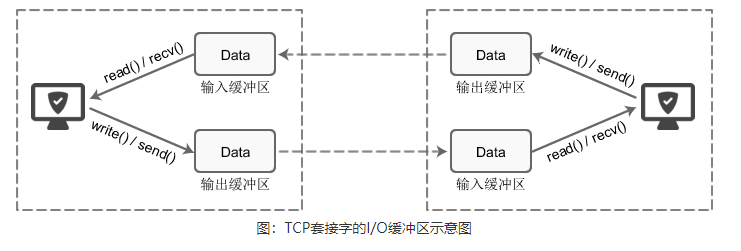
这些I/O缓冲区特性可整理如下:
- I/O缓冲区在每个TCP套接字中单独存在;
- I/O缓冲区在创建套接字时自动生成;
- 即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
- 关闭套接字将丢失输入缓冲区中的数据。
输入输出缓冲区的默认大小一般都是 8K!
2、阻塞模式
对于TCP套接字(默认情况下),当使用send() 发送数据时:
(1) 首先会检查缓冲区,如果缓冲区的可用空间长度小于要发送的数据,那么 send() 会被阻塞(暂停执行),直到缓冲区中的数据被发 送到目标机器,腾出足够的空间,才唤醒 send() 函数继续写入数据。
(2) 如果TCP协议正在向网络发送数据,那么输出缓冲区会被锁定,不允许写入,send() 也会被阻塞,直到数据发送完毕缓冲区解锁, send() 才会被唤醒。
(3) 如果要写入的数据大于缓冲区的最大长度,那么将分批写入。
(4) 直到所有数据被写入缓冲区 send() 才能返回。
当使用recv() 读取数据时:
(1) 首先会检查缓冲区,如果缓冲区中有数据,那么就读取,否则函数会被阻塞,直到网络上有数据到来。
(2) 如果要读取的数据长度小于缓冲区中的数据长度,那么就不能一次性将缓冲区中的所有数据读出,剩余数据将不断积压,直到有 recv() 函数再次读取。
(3) 直到读取到数据后 recv() 函数才会返回,否则就一直被阻塞。
TCP套接字默认情况下是阻塞模式,也是最常用的。当然你也可以更改为非阻塞模式,后续我们会讲解。
13.3.3、TCP的粘包问题
上节我们讲到了socket缓冲区和数据的传递过程,可以看到数据的接收和发送是无关的,read()/recv() 函数不管数据发送了多少次,都会尽可能多的接收数据。也就是说,read()/recv() 和 write()/send() 的执行次数可能不同。
例如,write()/send() 重复执行三次,每次都发送字符串"abc”,那么目标机器上的 read()/recv() 可能分三次接收,每次都接收"abc";也可能分两次接收,第一次接收"abcab",第二次接收"cabc";也可能一次就接收到字符串"abcabcabc"。
这就是数据的“粘包”问题,客户端发送的多个数据包被当做一个数据包接收。也称数据的无边界性,read()/recv() 函数不知道数据包的开始或结束标志(实际上也没有任何开始或结束标志),只把它们当做连续的数据流来处理。
13.4、基于Go的socket代码实现
13.4.1、 聊天案例
服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
package main
import (
"fmt"
"net"
"strings"
)
func main() {
// 1.创建TCP服务端监听
listenner, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println(err)
return
}
defer listenner.Close()
// 2.服务端不断等待请求处理
for {
// 阻塞等待客户端连接
conn, err := listenner.Accept()
if err != nil {
fmt.Println(err)
continue
}
go ClientConn(conn)
}
}
// 处理服务端逻辑
func ClientConn(conn net.Conn) {
defer conn.Close()
// 获取客户端地址
ipAddr := conn.RemoteAddr().String()
fmt.Println(ipAddr, "连接成功")
// 缓冲区
buf := make([]byte, 1024)
for {
// n是读取的长度
// time.Sleep(time.Second*10) // 粘包
n, err := conn.Read(buf)
if err != nil {
fmt.Println(err)
return
}
// 切出有效数据
result := buf[:n]
fmt.Printf("接收到数据,来自[%s] [%d]:%s\n", ipAddr, n, string(result))
// 接收到exit,退出连接
if string(result) == "exit" {
fmt.Println(ipAddr, "退出连接")
return
}
// 回复客户端
conn.Write([]byte(strings.ToUpper(string(result))))
}
}
|
聊天案例客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
package main
import (
"fmt"
"net"
)
func main() {
// 1.连接服务端
conn, err := net.Dial("tcp", "127.0.0.1:8888")
if err != nil {
fmt.Println(err)
return
}
defer conn.Close()
// 缓冲区
for {
buf := make([]byte, 1024)
fmt.Printf("请输入发送的内容:")
fmt.Scan(&buf)
fmt.Printf("发送的内容:%s\n", string(buf))
// 发送数据
conn.Write(buf)
//conn.Write(buf) // 粘包
//conn.Write(buf) // 粘包
// 接收服务端返回信息
res := make([]byte, 1024)
n, err := conn.Read(res)
if err != nil {
fmt.Println(err)
return
}
result := res[:n]
fmt.Printf("接收到数据:%s\n", string(result))
}
}
|
13.4.2、 ssh案例
服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
package main
import (
"fmt"
"github.com/axgle/mahonia"
"net"
"os/exec"
)
func main() {
// 1.创建TCP服务端监听
listenner, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println(err)
return
}
defer listenner.Close()
for true {
// 阻塞等待客户端连接
conn, err := listenner.Accept()
if err != nil {
fmt.Println(err)
return
}
go ClientConn(conn)
}
}
// 处理服务端逻辑
func ClientConn(conn net.Conn) {
defer conn.Close()
// 获取客户端地址
ipAddr := conn.RemoteAddr().String()
fmt.Println(ipAddr, "连接成功")
for true {
// 缓冲区
data := make([]byte, 1024)
// n是读取的长度
n, err := conn.Read(data)
fmt.Println("命令字节数",n)
if err != nil {
fmt.Println(err)
return
}
// 切出有效数据
data = data[:n]
fmt.Printf("接收到命令,来自[%s] [%d]:%s\n", ipAddr, n, string(data))
// 接收到exit,退出连接
if string(data) == "exit" {
fmt.Println(ipAddr, "退出连接")
return
}
// 回复客户端
cmd := exec.Command("cmd","/C",string(data))
// 执行命令,并返回结果
output,err := cmd.Output()
if err != nil {
panic(err)
}
fmt.Println("命令结果字节数:",len(output))
dec := mahonia.NewDecoder("gbk")
_, cdata, _ := dec.Translate(output, true)
result := string(cdata)
fmt.Println(result)
conn.Write([]byte(string(result)))
}
}
|
客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
// 1.连接服务端
conn, err := net.Dial("tcp", "127.0.0.1:8888")
if err != nil {
fmt.Println(err)
return
}
defer conn.Close()
// 缓冲区
for true {
reader := bufio.NewReader(os.Stdin) // 从标准输入生成读对象
fmt.Println("输入执行命令>>>")
text, _ := reader.ReadString('\n') // 读到换行
text = strings.TrimSpace(text)
fmt.Println("text",text)
// 发送数据
conn.Write([]byte(text))
// 接收服务端返回信息
res := make([]byte, 100000) // 如何解决大文件传输问题呢?看下面的文件上传案例
n, err := conn.Read(res)
if err != nil {
fmt.Println("err:",err)
return
}
fmt.Println("n",n)
result := res[:n]
fmt.Printf("接收到数据:%s\n", string(result))
}
}
|
13.4.3、上传文件案例
服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
package main
import (
"bufio"
"fmt"
"net"
"os"
"strconv"
"strings"
)
func main() {
// 1.创建TCP服务端监听
listenner, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println(err)
return
}
defer listenner.Close()
for true {
// 阻塞等待客户端连接
conn, err := listenner.Accept()
if err != nil {
fmt.Println(err)
return
}
go ClientConn(conn)
}
}
// 处理服务端逻辑
func ClientConn(conn net.Conn) {
defer conn.Close()
// 获取客户端地址
ipAddr := conn.RemoteAddr().String()
fmt.Println(ipAddr, "连接成功")
for true {
// 缓冲区
infoByte := make([]byte, 1024)
// n是读取的长度
n, err := conn.Read(infoByte)
if err != nil {
fmt.Println(err)
return
}
//
nameAndSize := strings.Split(string(infoByte[:n])," ")
fileSize, err := strconv.Atoi(nameAndSize[1])
fileName := nameAndSize[0]
// 读数据和写文件
file, err := os.OpenFile(fileName, os.O_CREATE|os.O_WRONLY|os.O_TRUNC, 0666)
writer := bufio.NewWriter(file)
// 循环接收数据
var readSize = 0
fmt.Println(readSize, fileSize)
for readSize < fileSize {
data := make([]byte, 1024)
// n是读取的长度
n, _ := conn.Read(data)
fmt.Println("n", n)
_, _ = writer.WriteString(string(data[:n]))
readSize += len(data)
}
_ = writer.Flush()
fmt.Println("上传成功!")
}
}
|
客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
package main
import (
"bufio"
"fmt"
"io"
"net"
"os"
"strconv"
"strings"
)
func main() {
// 1.连接服务端
conn, err := net.Dial("tcp", "127.0.0.1:8888")
if err != nil {
fmt.Println(err)
return
}
defer conn.Close()
// 缓冲区
for true {
reader := bufio.NewReader(os.Stdin) // 从标准输入生成读对象
fmt.Println("输入执行命令>>>")
text, _ := reader.ReadString('\n') // 读到换行
text = strings.TrimSpace(text)
path := strings.Split(text," ")[1]
//打开文件
file, _ := os.Open(path)
// 获取文件大小
reader = bufio.NewReader(file)
f, _ := os.Stat(path)
// 发送文件大小
fsize := f.Size()
// 获取文件名称
fname := f.Name()
strInt64 := strconv.FormatInt(fsize, 10)
_, _ = conn.Write([]byte(fname+" "+strInt64))
// 发送文件数据
for {
// (1) 按行都字符串
bytes, err := reader.ReadBytes('\n') // 读取到换行符为止,读取内容包括换行符
// 发送数据
_, _ = conn.Write(bytes)
if err == io.EOF { //io.EOF 读取到了文件的末尾
// fmt.Println("读取到文件末尾!")
break
}
}
fmt.Println("上传成功")
}
}
|
13.5、web开发
13.5.1、http协议
(1)简介
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于万维网(WWW:World Wide Web )服务器与本地浏览器之间传输超文本的传送协议。HTTP是一个属于应用层的面向对象的协议,由于其简捷、快速的方式,适用于分布式超媒体信息系统。它于1990年提出,经过几年的使用与发展,得到不断地完善和扩展。HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
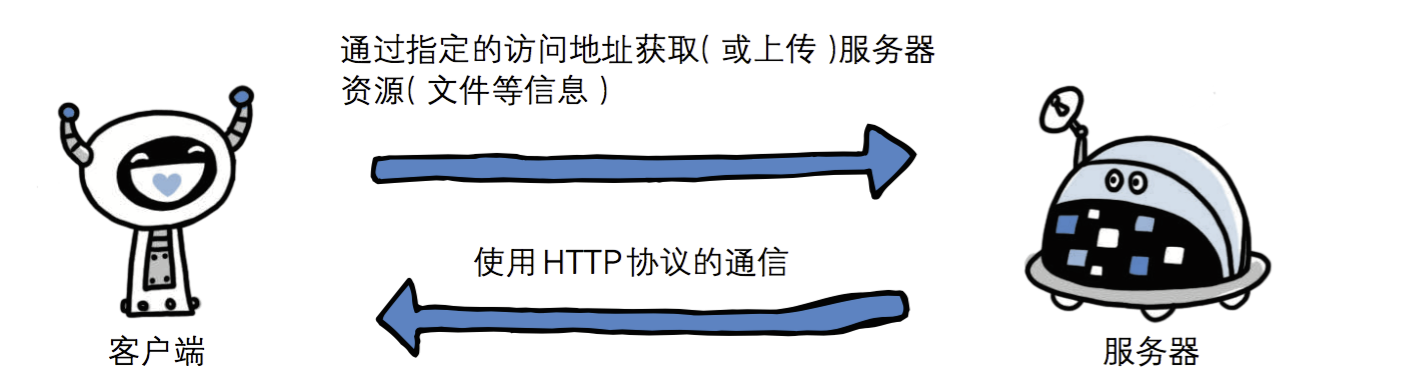
(2) http协议特性
(1) 基于TCP/IP协议
http协议是基于TCP/IP协议之上的应用层协议。
(2) 基于请求-响应模式
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并 返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有 接收到请求之前不会发送响应
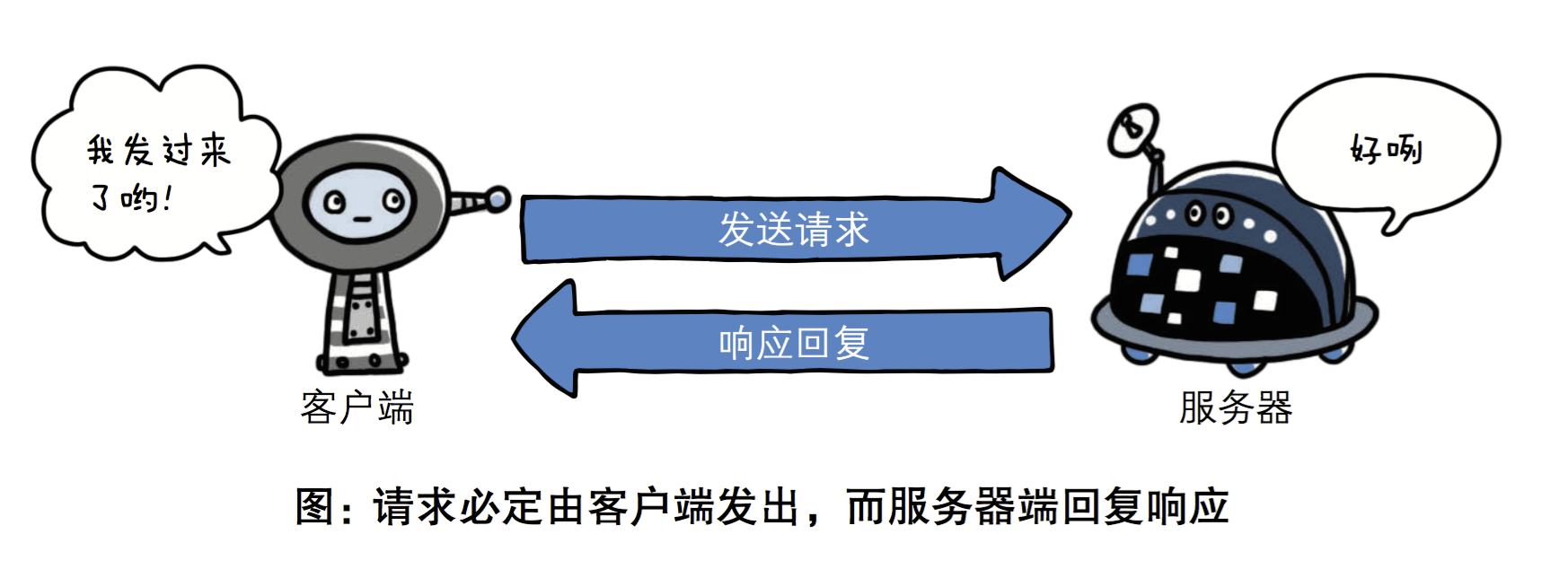
(3) 无状态保存
HTTP是一种不保存状态,即无状态(stateless)协议。HTTP协议 自身不对请求和响应之间的通信状态进行保存。也就是说在HTTP这个 级别,协议对于发送过的请求或响应都不做持久化处理。
使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产 生。协议本身并不保留之前一切的请求或响应报文的信息。这是为了更快地处理大量事务,确保协议的可伸缩性,而特意把HTTP协议设计成 如此简单的。
可是,随着Web的不断发展,因无状态而导致业务处理变得棘手 的情况增多了。比如,用户登录到一家购物网站,即使他跳转到该站的 其他页面后,也需要能继续保持登录状态。针对这个实例,网站为了能 够掌握是谁送出的请求,需要保存用户的状态。HTTP/1.1虽然是无状态协议,但为了实现期望的保持状态功能, 于是引入了Cookie技术。有了Cookie再用HTTP协议通信,就可以管 理状态了。有关Cookie的详细内容稍后讲解。
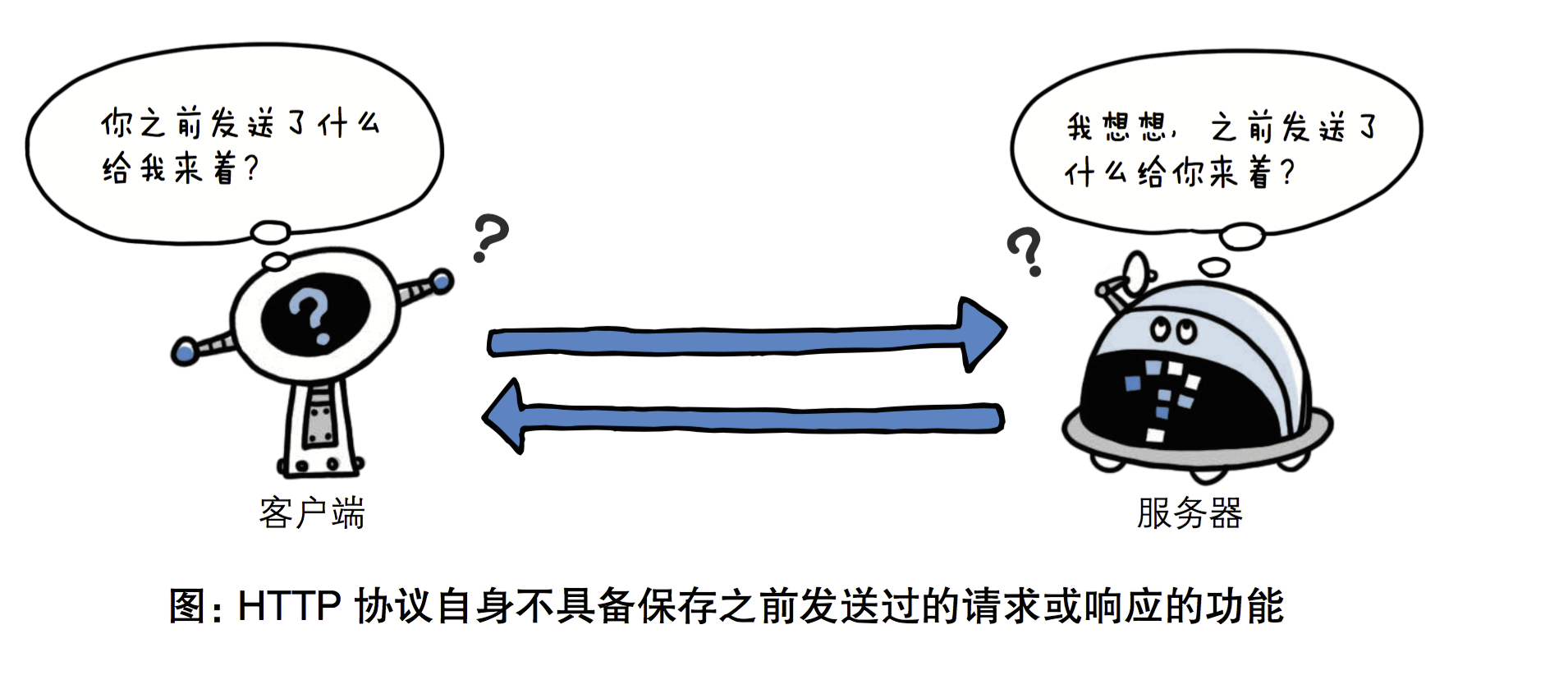
(4) 无连接
无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
(3)14.1.3 、http请求协议与响应协议
http协议包含由浏览器发送数据到服务器需要遵循的请求协议与服务器发送数据到浏览器需要遵循的请求协议。用于HTTP协议交互的信被为HTTP报文。请求端(客户端)的HTTP报文 做请求报文,响应端(服务器端)的 做响应报文。HTTP报文本身是由多行数据构成的字文本。
(1) 请求协议
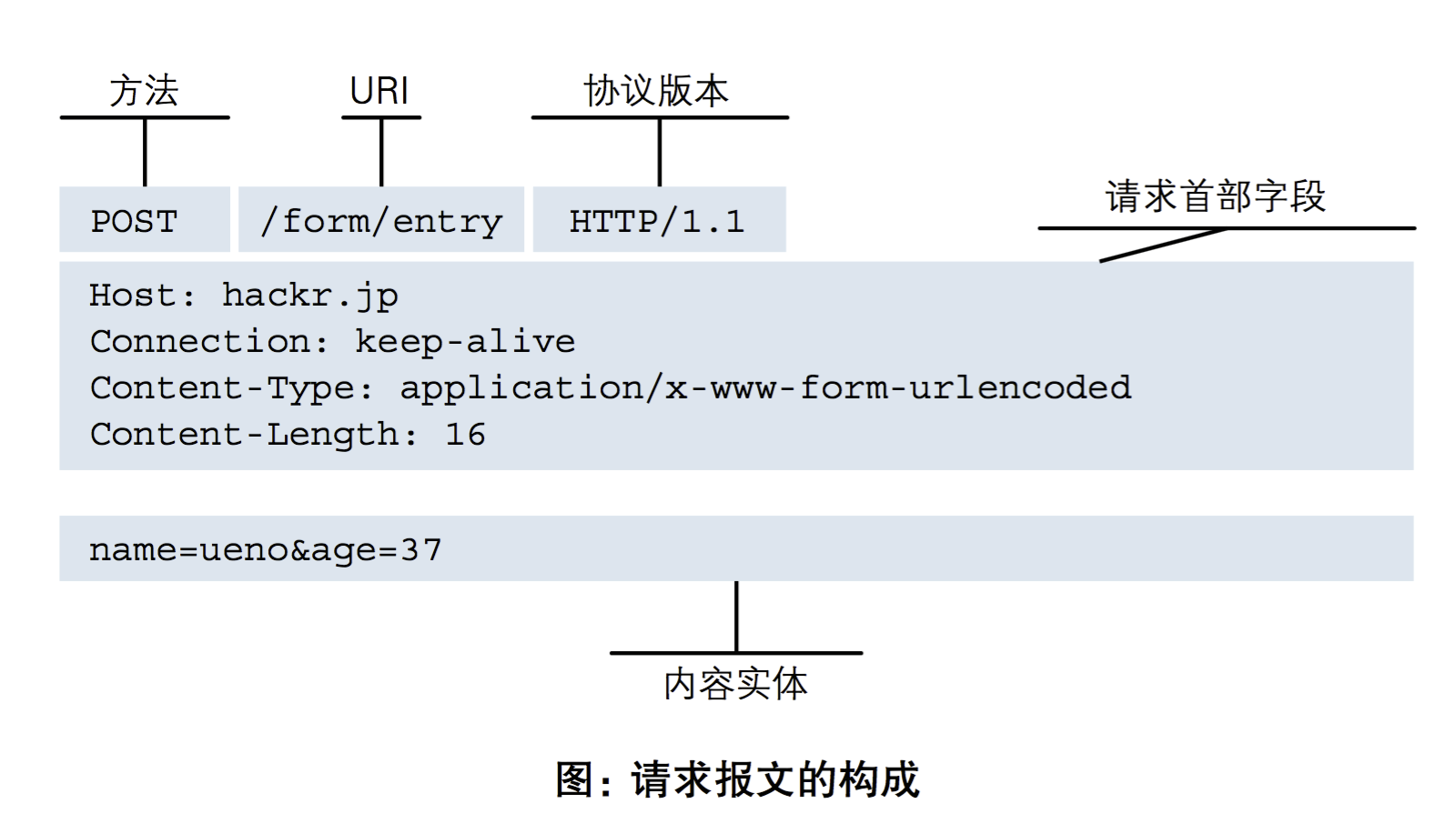
请求方式: get与post请求
- GET提交的数据会放在URL之后,以?分割URL和传输数据,参数之间以&相连,如EditBook?name=test1&id=123456. POST方法是把提交的数据放在HTTP包的请求体中.
- GET提交的数据大小有限制(因为浏览器对URL的长度有限制),而POST方法提交的数据没有限制
(2) 响应协议

响应状态码:状态码的职 是当客户端向服务器端发送请求时, 返回的请求 结果。借助状态码,用户可以知道服务器端是正常 理了请求,还是出 现了 。状态码如200 OK,以3位数字和原因 成。数字中的 一位指定了响应 别,后两位无分 。响应 别有以5种。
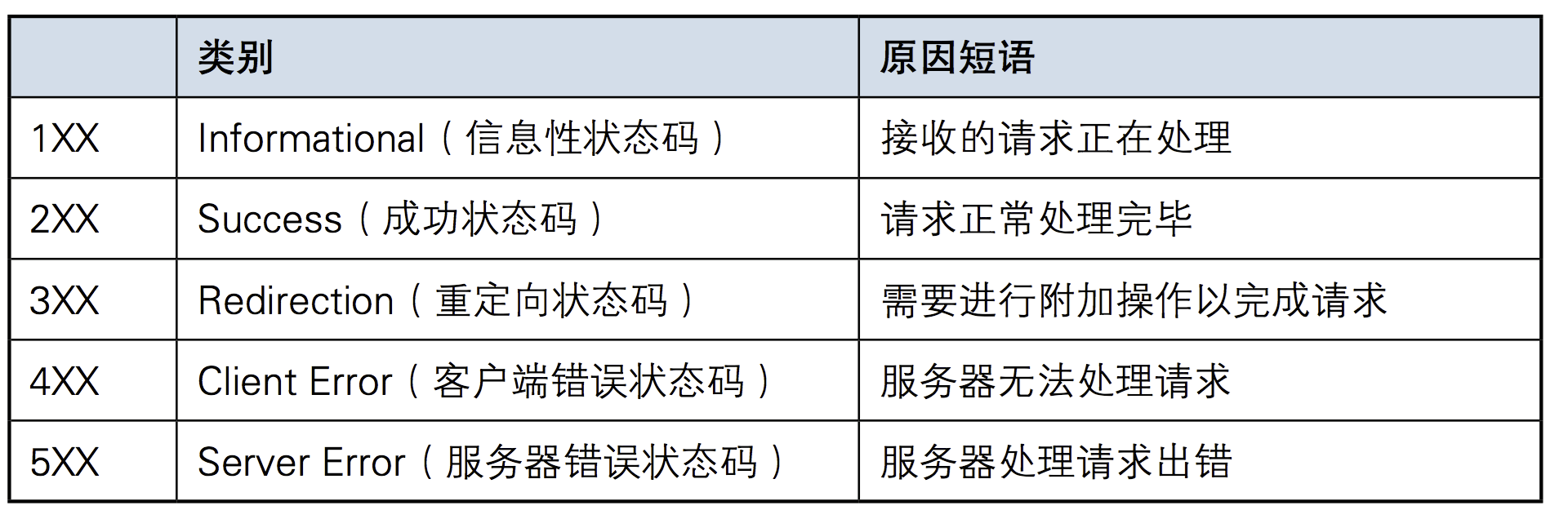
图片来自于《图解HTTP》
13.5.2、基于net库的web应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
package main
import (
"fmt"
"net"
)
func main() {
listenner, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println(err)
return
}
defer listenner.Close()
// 2.服务端不断等待请求处理
for {
// 阻塞等待客户端连接
conn, err := listenner.Accept()
if err != nil {
fmt.Println(err)
continue
}
buf := make([]byte, 1024)
n, err := conn.Read(buf)
fmt.Println("n",n)
conn.Write([]byte("HTTP/1.1 200 OK\r\n\r\n<h1>Welcome to Web World!</h1>"))
}
}
|
13.5.3、基于http库的web应用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
package main
import (
"fmt"
"net/http"
)
func foo (w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello Yuan")
}
func main() {
http.HandleFunc("/hi", foo)
http.ListenAndServe(":8090", nil)
}
|
十四、并发编程
有人把Go语言比作 21 世纪的C语言,第一是因为Go语言设计简单,第二则是因为 21 世纪最重要的就是并发程序设计,而 Go 从语言层面就支持并发。同时实现了自动垃圾回收机制。Go语言的并发机制运用起来非常简便,在启动并发的方式上直接添加了语言级的关键字就可以实现,和其他编程语言相比更加轻量。
14.1、并发技术
14.1.1、操作系统的进程、线程发展
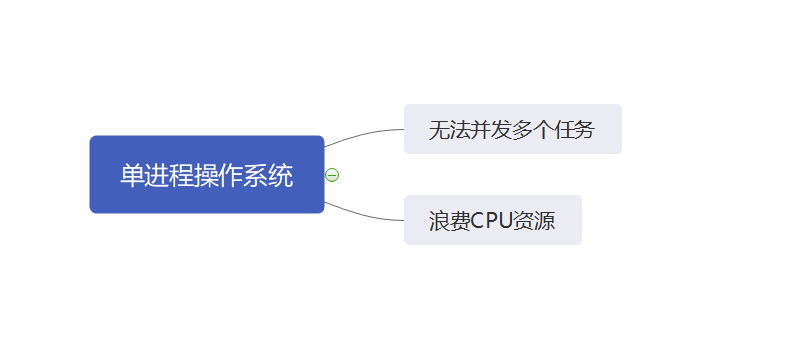
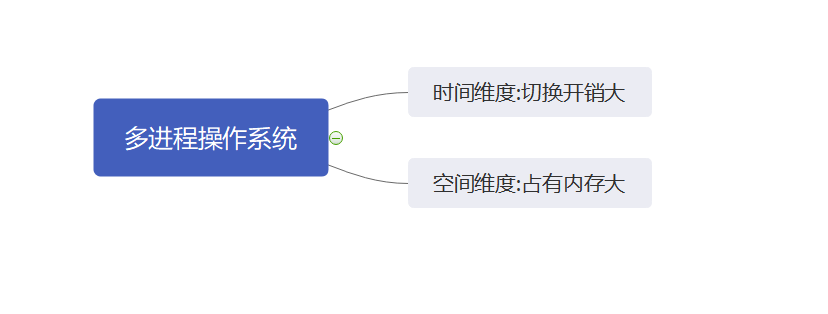
14.1.2、进程概念
我们都知道计算机的核心是CPU,它承担了所有的计算任务;而操作系统是计算机的管理者,它负责任务的调度、资源的分配和管理,统领整个计算机硬件;应用程序则是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。
进程是一种抽象的概念,从来没有统一的标准定义。进程一般由程序、数据集合和进程控制块三部分组成。
- 程序用于描述进程要完成的功能,是控制进程执行的指令集;
- 数据集合是程序在执行时所需要的数据和工作区;
- 程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
进程具有的特征:
- 动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
- 并发性:任何进程都可以同其他进程一起并发执行;
- 独立性:进程是系统进行资源分配和调度的一个独立单位;
- 结构性:进程由程序、数据和进程控制块三部分组成。
14.1.3、线程的概念
在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。
后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程。
线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
14.1.4、任务调度
线程是什么?要理解这个概念,需要先了解一下操作系统的一些相关概念。大部分操作系统(如Windows、Linux)的任务调度是采用时间片轮转的抢占式调度方式。
在一个进程中,当一个线程任务执行几毫秒后,会由操作系统的内核(负责管理各个任务)进行调度,通过硬件的计数器中断处理器,让该线程强制暂停并将该线程的寄存器放入内存中,通过查看线程列表决定接下来执行哪一个线程,并从内存中恢复该线程的寄存器,最后恢复该线程的执行,从而去执行下一个任务。
上述过程中,任务执行的那一小段时间叫做时间片,任务正在执行时的状态叫运行状态,被暂停的线程任务状态叫做就绪状态,意为等待下一个属于它的时间片的到来。
这种方式保证了每个线程轮流执行,由于CPU的执行效率非常高,时间片非常短,在各个任务之间快速地切换,给人的感觉就是多个任务在“同时进行”,这也就是我们所说的并发。
14.1.5、进程与线程的区别
前面讲了进程与线程,但可能你还觉得迷糊,感觉他们很类似。的确,进程与线程有着千丝万缕的关系,下面就让我们一起来理一理:
- 线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
- 一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;
- 进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
14.1.6、线程的生命周期
当线程的数量小于处理器的数量时,线程的并发是真正的并发,不同的线程运行在不同的处理器上。但当线程的数量大于处理器的数量时,线程的并发会受到一些阻碍,此时并不是真正的并发,因为此时至少有一个处理器会运行多个线程。
在单个处理器运行多个线程时,并发是一种模拟出来的状态。操作系统采用时间片轮转的方式轮流执行每一个线程。现在,几乎所有的现代操作系统采用的都是时间片轮转的抢占式调度方式,如我们熟悉的Unix、Linux、Windows及macOS等流行的操作系统。
我们知道线程是程序执行的最小单位,也是任务执行的最小单位。在早期只有进程的操作系统中,进程有五种状态,创建、就绪、运行、阻塞(等待)、退出。早期的进程相当于现在的只有单个线程的进程,那么现在的多线程也有五种状态,现在的多线程的生命周期与早期进程的生命周期类似。
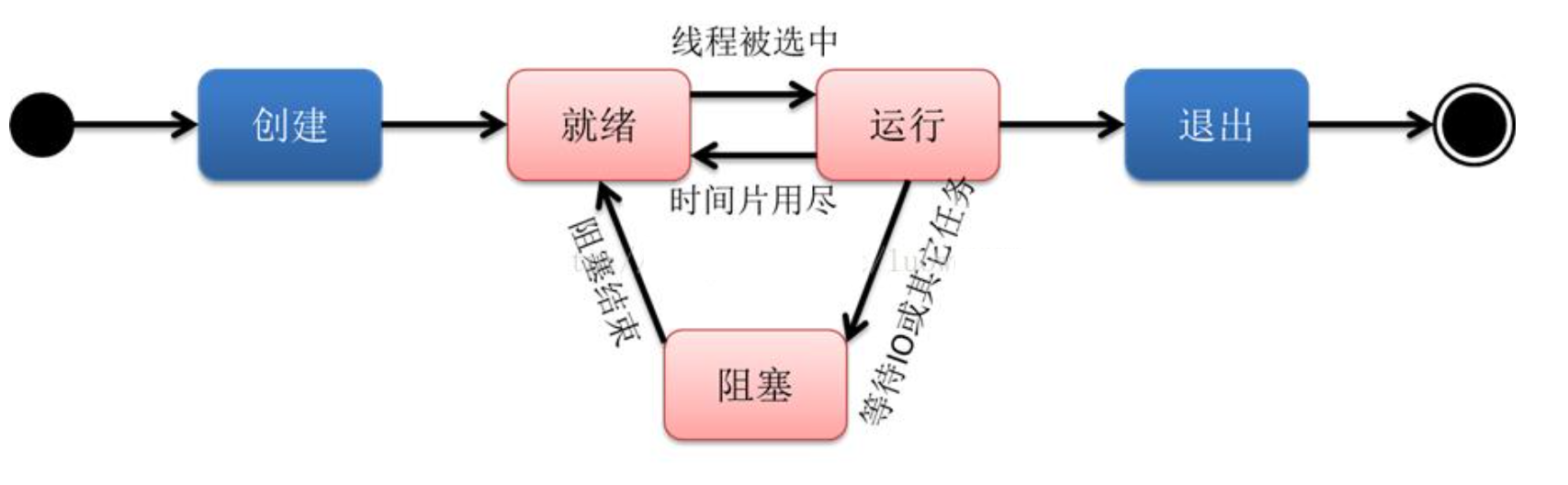
1
2
3
4
5
6
7
|
线程的生命周期
# 创建:一个新的线程被创建,等待该线程被调用执行;
# 就绪:时间片已用完,此线程被强制暂停,等待下一个属于它的时间片到来;
# 运行:此线程正在执行,正在占用时间片;
# 阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
# 退出:一个线程完成任务或者其他终止条件发生,该线程终止进入退出状态,退出状态释放该线程所分配的资源。
|
14.1.7、协程(Coroutines)
协程,英文Coroutines,是一种基于线程之上,但又比线程更加轻量级的存在,这种由程序员自己写程序来管理的轻量级线程叫做『用户空间线程』,具有对内核来说不可见的特性。因为是自主开辟的异步任务,所以很多人也更喜欢叫它们纤程(Fiber),或者绿色线程(GreenThread)。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
协程解决的是线程的切换开销和内存开销的问题
1
2
3
|
* 用户空间 首先是在用户空间, 避免内核态和用户态的切换导致的成本。
* 由语言或者框架层调度
* 更小的栈空间允许创建大量实例(百万级别)
|
14.1.8、三种线程模型
无论语言层面何种并发模型,到了操作系统层面,一定是以线程的形态存在的。而操作系统根据资源访问权限的不同,体系架构可分为用户空间和内核空间;内核空间主要操作访问CPU资源、I/O资源、内存资源等硬件资源,为上层应用程序提供最基本的基础资源,用户空间呢就是上层应用程序的固定活动空间,用户空间不可以直接访问资源,必须通过“系统调用”、“库函数”或“Shell脚本”来调用内核空间提供的资源。我们现在的计算机语言,可以狭义的认为是一种“软件”,它们中所谓的“线程”,往往是用户态的线程,和操作系统本身内核态的线程(简称KSE),还是有区别的。
一、用户级线程模型(M : 1)
将多个用户级线程映射到一个内核级线程,线程管理在用户空间完成。此模式中,用户级线程对操作系统不可见(即透明)。
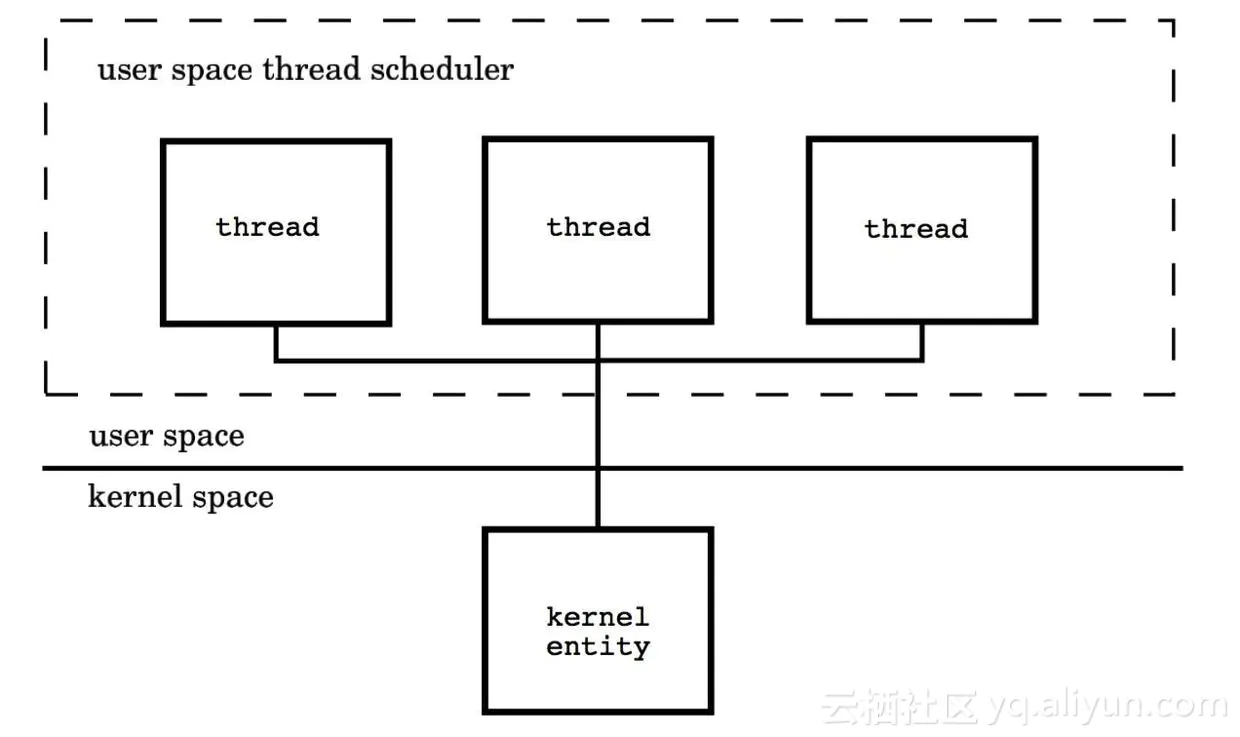
优点:
这种模型的好处是线程上下文切换都发生在用户空间,避免的模态切换(mode switch),从而对于性能有积极的影响。
缺点:
- 无法利用多核资源:协程的本质是个单线程,它不能同时将 单个CPU 的多个核用上,协程需要和进程配合才能运行在多CPU上.当然我们日常所编写的绝大部分应用都没有这个必要,除非是cpu密集型应用。
- 进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序
二、内核级线程模型(1:1)
将每个用户级线程映射到一个内核级线程。
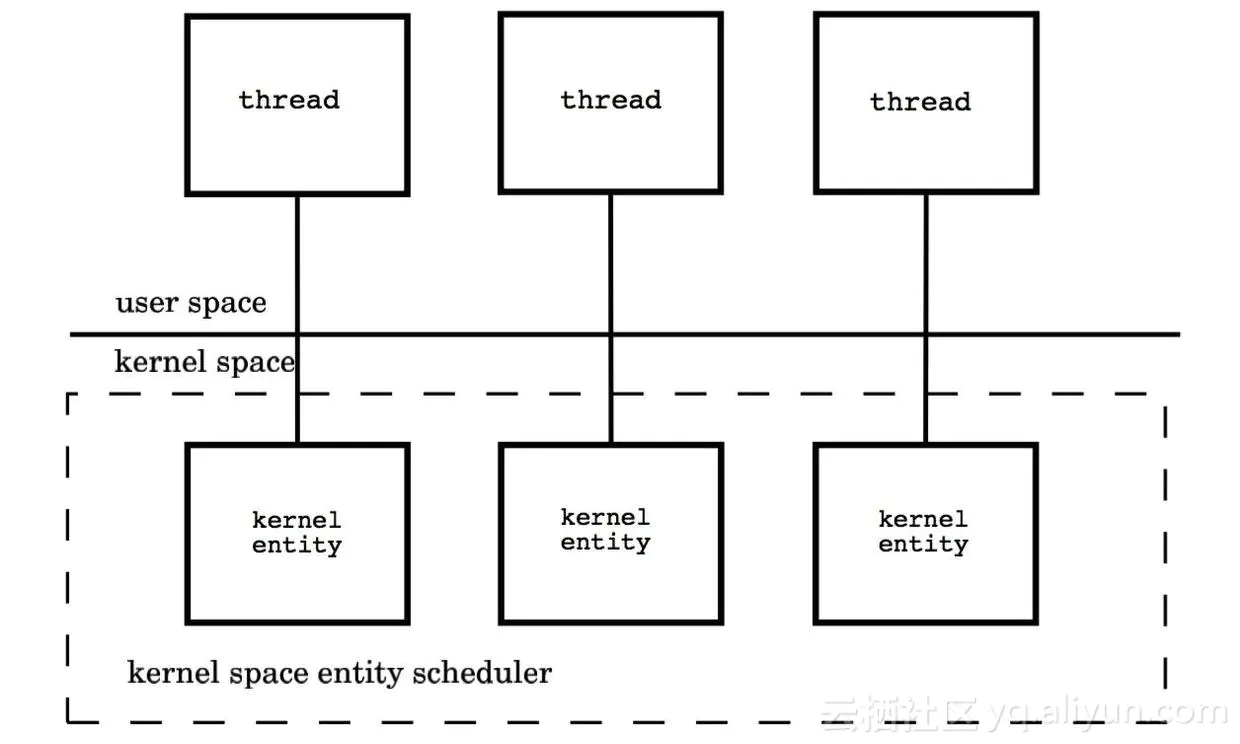
每个线程由内核调度器独立的调度,所以如果一个线程阻塞则不影响其他的线程。
优点:在多核处理器的硬件的支持下,内核空间线程模型支持了真正的并行,当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。
三、两级线程模型(M:N)
内核线程和用户线程的数量比为 M : N,内核用户空间综合了前两种的优点。
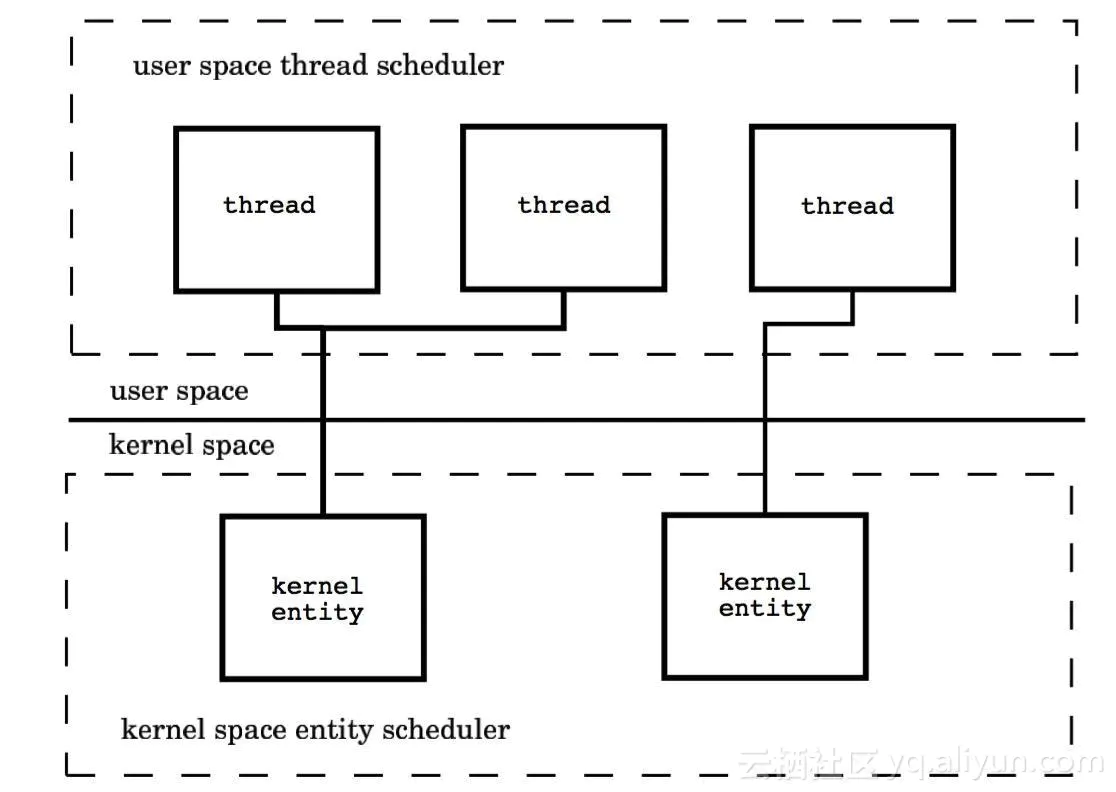
一个进程中可以对应多个内核级线程,但是进程中的线程不和内核线程一一对应;这种线程模型会先创建多个内核级线程,然后用自身的用户级线程去对应创建的多个内核级线程,自身的用户级线程需要本身程序去调度,内核级的线程交给操作系统内核去调度。这使得大部分的线程上下文切换都发生在用户空间,而多个内核线程又可以充分利用处理器资源。
Go语言的线程模型就是一种特殊的两级线程模型(GPM调度模型)。
14.2、goroutine的基本使用
14.2.1、goroutine的基本语法
goroutine 是 Go语言中的轻量级线程实现,由 Go 运行时(runtime)管理。Go 程序会智能地将 goroutine 中的任务合理地分配给每个 CPU。Go 程序从 main 包的 main() 函数开始,在程序启动时,Go 程序就会为 main() 函数创建一个默认的 goroutine。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"fmt"
"time"
)
func foo() {
fmt.Println("foo")
time.Sleep(time.Second)
fmt.Println("foo end")
}
func bar() {
fmt.Println("bar")
time.Sleep(time.Second*2)
fmt.Println("bar end")
}
func main() {
go foo()
bar()
}
|
14.2.2、sync.WaitGroup
Go语言中可以使用sync.WaitGroup来实现并发任务的同步。 sync.WaitGroup有以下几个方法:
| 方法名 |
功能 |
| (wg * WaitGroup) Add(delta int) |
计数器+delta |
| (wg *WaitGroup) Done() |
计数器-1 |
| (wg *WaitGroup) Wait() |
阻塞直到计数器变为0 |
sync.WaitGroup内部维护着一个计数器,计数器的值可以增加和减少。例如当我们启动了N 个并发任务时,就将计数器值增加N。每个任务完成时通过调用Done()方法将计数器减1。通过调用Wait()来等待并发任务执行完,当计数器值为0时,表示所有并发任务已经完成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func foo() {
defer wg.Done()
fmt.Println("foo")
time.Sleep(time.Second)
fmt.Println("foo end")
}
func bar() {
defer wg.Done()
fmt.Println("bar")
time.Sleep(time.Second*2)
fmt.Println("bar end")
}
func main() {
start:=time.Now()
wg.Add(2)
go foo()
go bar()
wg.Wait()
fmt.Println("程序结束,运行时间为",time.Now().Sub(start))
}
|
14.2.3、GOMAXPROCS
Go运行时的调度器使用GOMAXPROCS参数来确定需要使用多少个OS线程来同时执行Go代码。默认值是机器上的CPU核心数。例如在一个8核心的机器上,调度器会把Go代码同时调度到8个OS线程上(GOMAXPROCS是m:n调度中的n)。
Go语言中可以通过runtime.GOMAXPROCS()函数设置当前程序并发时占用的CPU逻辑核心数。
Go1.5版本之前,默认使用的是单核心执行。Go1.5版本之后,默认使用全部的CPU逻辑核心数。
我们可以通过将任务分配到不同的CPU逻辑核心上实现并行的效果,这里举个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
package main
import (
"fmt"
"runtime"
"sync"
)
var wg sync.WaitGroup
func foo() {
for i := 1; i < 10; i++ {
fmt.Println("A:", i)
//time.Sleep(time.Millisecond*20)
}
wg.Done()
}
func bar() {
for i := 1; i < 10; i++ {
fmt.Println("B:", i)
//time.Sleep(time.Millisecond*30)
}
wg.Done()
}
func main() {
wg.Add(2)
fmt.Println(runtime.NumCPU())
runtime.GOMAXPROCS(1)// 改为4
go foo()
go bar()
wg.Wait()
}
|
14.3、GPM调度器
GPM是GO语言运行时(runtime)层面得实现,是go语言自己实现得一套调度系统 区别于操作系统调度得OS线程
M指的是Machine,一个M直接关联了一个内核线程。由操作系统管理。
P指的是”processor”,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。它负责衔接M和G的调度上下文,将等待执行的G与M对接。
G指的是Goroutine,其实本质上也是一种轻量级的线程。包括了调用栈,重要的调度信息,例如channel等。
P的数量由环境变量中的GOMAXPROCS决定,通常来说它是和核心数对应,例如在4Core的服务器上回启动4个线程。G会有很多个,每个P会将Goroutine从一个就绪的队列中做Pop操作,为了减小锁的竞争,通常情况下每个P会负责一个队列。
Goroutine调度策略
每次调用go的时候,都会:
1
2
3
4
5
6
7
|
/*
A、创建一个G对象,加入到本地队列或者全局队列
B、如果有空闲的P,则创建一个M
C、M会启动一个底层线程,循环执行能找到的G任务
D、G任务的执行顺序是先从本地队列找,本地没有则从全局队列找(一次性转移(全局G个数/P个数)个,再去其它P中找(一次性转移一半)。
E、G任务执行是按照队列顺序(即调用go的顺序)执行的。
*/
|
创建一个M过程如下:
1
2
3
4
5
|
/*
A、先找到一个空闲的P,如果没有则直接返回。
B、调用系统API创建线程,不同的操作系统调用方法不一样。
C、 在创建的线程里循环执行G任务
*/
|
如果一个系统调用或者G任务执行太长,会一直占用内核空间线程,由于本地队列的G任务是顺序执行的,其它G任务就会阻塞。因此,Go程序启动的时候,会专门创建一个线程sysmon,用来监控和管理,sysmon内部是一个循环:
1
2
3
4
5
6
|
/*
A、记录所有P的G任务计数schedtick,schedtick会在每执行一个G任务后递增。
B、如果检查到 schedtick一直没有递增,说明P一直在执行同一个G任务,如果超过一定的时间(10ms),在G任务的栈信息里面加一个标记。
C、G任务在执行的时候,如果遇到非内联函数调用,就会检查一次标记,然后中断自己,把自己加到队列末尾,执行下一个G。
D、如果没有遇到非内联函数(有时候正常的小函数会被优化成内联函数)调用,会一直执行G任务,直到goroutine自己结束;如果goroutine是死循环,并且GOMAXPROCS=1,阻塞。
*/
|
(1) 局部优先调度
(2) steal working
(3) 阻塞调度
(4) 抢占式调度
14.4、数据安全与锁
14.4.1、互斥锁
互斥锁是一种常用的控制共享资源访问的方法,它能够保证同时只有一个goroutine可以访问共享资源。Go语言中使用sync包的Mutex类型来实现互斥锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
var lock sync.Mutex
var x = 0
func add() {
//lock.Lock()
x++
//lock.Unlock()
wg.Done()
}
func main() {
wg.Add(1000)
for i:=0;i<1000 ;i++ {
go add()
}
wg.Wait()
fmt.Println(x)
}
|
使用互斥锁能够保证同一时间有且只有一个goroutine进入临界区,其他的goroutine则在等待锁;当互斥锁释放后,等待的goroutine才可以获取锁进入临界区,多个goroutine同时等待一个锁时,唤醒的策略是随机的。
14.4.2、读写锁
在读多写少的环境中,可以优先使用读写互斥锁(sync.RWMutex),它比互斥锁更加高效。sync 包中的 RWMutex 提供了读写互斥锁的封装。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
package main
import (
"fmt"
"sync"
"time"
)
// 效率对比
// 声明读写锁
var rwlock sync.RWMutex
var mutex sync.Mutex
var wg sync.WaitGroup
// 全局变量
var x int
// 写数据
func write() {
//mutex.Lock()
rwlock.Lock()
x += 1
fmt.Println("x",x)
time.Sleep(10 * time.Millisecond)
//mutex.Unlock()
rwlock.Unlock()
wg.Done()
}
func read(i int) {
//mutex.Lock()
rwlock.RLock()
time.Sleep(time.Millisecond)
fmt.Println(x)
//mutex.Unlock()
rwlock.RUnlock()
wg.Done()
}
// 互斥锁执行时间:18533117400
// 读写锁执行时间:1312065700
func main() {
start := time.Now()
wg.Add(1)
go write()
for i := 0; i < 1000; i++ {
wg.Add(1)
go read(i)
}
wg.Wait()
fmt.Println("运行时间:", time.Now().Sub(start))
}
|
14.4.3、map锁
Go语言中内置的map不是并发安全的.
并发读是安全的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
m := make(map[int]int)
// 添一些假数据
for i := 0; i < 5; i++ {
m[i] = i*i
}
// 遍历打印
for i := 0; i < 5; i++ {
wg.Add(1)
go func(x int) {
fmt.Println(m[x], "\t")
wg.Done()
}(i)
}
wg.Wait()
fmt.Println(m)
}
|
并发写则不安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
package main
import (
"fmt"
"sync"
)
func main() {
wg := sync.WaitGroup{}
//m := make(map[int]int)
var m = sync.Map{}
// 并发写
for i := 0; i < 100; i++ {
wg.Add(1)
go func(i int) {
defer wg.Done()
m.Store(i,i*i)
}(i)
}
wg.Wait()
fmt.Println(m.Load(1))
fmt.Println(m.Load(2))
}
|
14.4.4、原子性操作
AddXxx():加减操作
CompareAndSwapXxx():比较并交换
LoadXxx():读取操作
StoreXxx():写入操作
SwapXxx():交换操作
原子操作与互斥锁性能对比:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
// 效率对比
// 原子操作需要接收int32或int64
var x int32
var wg sync.WaitGroup
var mutex sync.Mutex
// 互斥锁操作
func add1() {
for i := 0; i < 500; i++ {
mutex.Lock()
x += 1
mutex.Unlock()
}
wg.Done()
}
// 原子操作
func add2() {
for i := 0; i < 500; i++ {
atomic.AddInt32(&x, 1)
}
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10000; i++ {
wg.Add(1)
go add1()
//go add2()
}
wg.Wait()
fmt.Println("x:", x)
fmt.Println("执行时间:", time.Now().Sub(start))
}
|
14.5、channel(管道)
channel一个类型管道,通过它可以在goroutine之间发送和接收消息。它是Golang在语言层面提供的goroutine间的通信方式。Go依赖于成为CSP的并发模型,通过Channel实现这种同步模式。Golang并发的核心哲学是不要通过共享内存进行通信。
在地铁站、食堂、洗手间等公共场所人很多的情况下,大家养成了排队的习惯,目的也是避免拥挤、插队导致的低效的资源使用和交换过程。代码与数据也是如此,多个 goroutine 为了争抢数据,势必造成执行的低效率,使用队列的方式是最高效的,channel 就是一种队列一样的结构。
Go语言中的通道(channel)是一种特殊的类型。在任何时候,同时只能有一个 goroutine 访问通道进行发送和获取数据。goroutine 间通过通道就可以通信。通道像一个传送带或者队列,总是遵循先入先出(First In First Out)的规则,保证收发数据的顺序。
14.5.1、声明创建通道
通道本身需要一个类型进行修饰,就像切片类型需要标识元素类型。通道的元素类型就是在其内部传输的数据类型,声明如下:
通道是引用类型,需要使用 make 进行创建,格式如下:
1
2
|
通道实例 := make(chan 数据类型) // 不带缓冲的chan
通道实例 := make(chan 数据类型,数量) // 带缓冲的chan
|
14.5.2、channel基本操作
1
2
3
4
5
|
ch := make(chan 数据类型)
// 向通道发送数据
ch <- 值
// 从通道接收数据
<- ch
|
示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
package main
import "fmt"
type Stu struct {
Name string
age int
}
func main() {
// 案例1
ch := make(chan int, 10)
fmt.Println(len(ch), cap(ch))
ch <- 1
ch <- 2
ch <- 3
fmt.Println(<-ch) // FIFO
fmt.Println(<-ch)
fmt.Println(<-ch)
// 案例2
ch2 := make(chan interface{}, 3)
ch2 <- 100
ch2 <- "hello"
ch2 <- Stu{"yuan", 22}
fmt.Println(<-ch2)
fmt.Println(<-ch2)
fmt.Println(<-ch2)
// s := <-ch2
//fmt.Println(s.Name)
// fmt.Println(s.(Stu).Name)
// 案例3
ch3 := make(chan int, 3)
x := 10
ch3 <- x // 值拷贝
x = 20
fmt.Println(<-ch3)
ch4 := make(chan *int, 3)
y := 20
ch4 <- &y
y = 30
p := <-ch4
fmt.Println(*p)
}
|
14.5.3、chan是引用类型
通道的结构hchan,源码再src/runtime/chan.go下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
type hchan struct {
qcount uint // total data in the queue 当前队列里还剩余元素个数
dataqsiz uint // size of the circular queue 环形队列长度,即缓冲区的大小,即make(chan T,N) 中的N
buf unsafe.Pointer // points to an array of dataqsiz elements 环形队列指针
elemsize uint16 //每个元素的大小
closed uint32 //标识当前通道是否处于关闭状态,创建通道后,该字段设置0,即打开通道;通道调用close将其设置为1,通道关闭
elemtype *_type // element type 元素类型,用于数据传递过程中的赋值
sendx uint // send index 环形缓冲区的状态字段,它只是缓冲区的当前索引-支持数组,它可以从中发送数据
recvx uint // receive index 环形缓冲区的状态字段,它只是缓冲区当前索引-支持数组,它可以从中接受数据
recvq waitq // list of recv waiters 等待读消息的goroutine队列
sendq waitq // list of send waiters 等待写消息的goroutine队列
// lock protects all fields in hchan, as well as several
// fields in sudogs blocked on this channel.
//
// Do not change another G's status while holding this lock
// (in particular, do not ready a G), as this can deadlock
// with stack shrinking.
lock mutex //互斥锁,为每个读写操作锁定通道,因为发送和接受必须是互斥操作
}
// sudog 代表goroutine
type waitq struct {
first *sudog
last *sudog
}
|
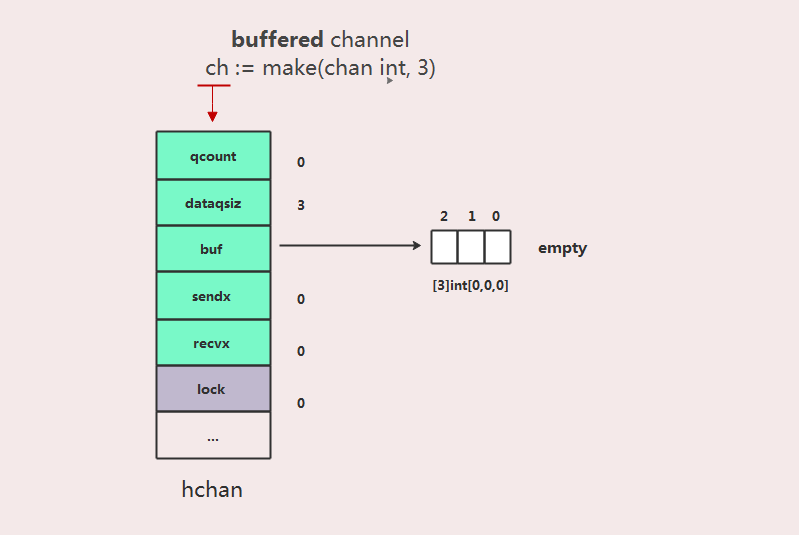
han内部实现了一个环形队列作为其缓冲区,队列的长度是创建chan时指定的。
环形队列
下图展示了一个可缓存6个元素的channel示意图:
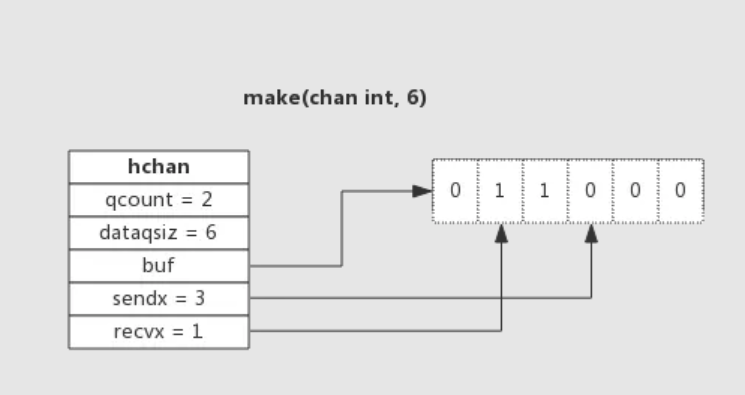
- dataqsiz指示了队列长度为6,即可缓存6个元素;
- buf指向队列的内存,队列中还剩余两个元素;
- qcount表示队列中还有两个元素(len(chan)可查询chan的队列元素个数);
- sendx指示后续写入的数据存储的位置,取值[0, 6);
- recvx指示从该位置读取数据, 取值[0, 6);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import "fmt"
func foo(c chan int) {
c <- 50
}
func main() {
// 引用类型
var ch5 = make(chan int, 3)
var ch6 = ch5
ch5 <- 100
ch5 <- 200
fmt.Println(<-ch6)
fmt.Println(<-ch5)
var ch7 = make(chan int, 3)
foo(ch7)
fmt.Println(<-ch7)
}
|
14.5.4、管道的关闭与循环
当向通道中发送完数据时,我们可以通过close函数来关闭通道。关闭 channel 非常简单,直接使用Go语言内置的 close() 函数即可,关闭后的通道只可读不可写。
1
2
3
4
5
6
7
8
|
ch3 := make(chan int, 10)
ch3 <- 1
ch3 <- 2
ch3 <- 3
close(ch3)
fmt.Println(<-ch3)
ch3 <- 4
|
如果不close掉channel是会发生死锁的,原因是当for循环读完channel后会继续尝试读取下一个,而由于channel没有写入的协程且没关闭,会一直阻塞形成死锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 10)
ch <- 1
ch <- 2
ch <- 3
// 方式1
go func() {
time.Sleep(time.Second * 10)
ch <- 4
}()
for v := range ch {
fmt.Println(v, len(ch))
// 读取完所有值后,ch的sendq中没有groutine
if len(ch) == 0 { // 如果现有数据量为0,跳出循环
break
}
}
close(ch)
for i := range ch {
fmt.Println(i)
}
}
|
在介绍了如何关闭 channel 之后,我们就多了一个问题:如何判断一个 channel 是否已经被关闭?我们可以在读取的时候使用多重返回值的方式:
这个用法与 map 中的按键获取 value 的过程比较类似,只需要看第二个 bool 返回值即可,如果返回值是 false 则表示 ch 已经被关闭。
生产者消费者模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package main
import (
"fmt"
"sync"
"time"
)
func producer(ch chan int) {
for i := 1; i < 11; i++ {
ch <- i
fmt.Println("插入值",i)
}
wg.Done()
}
func consumer(ch chan int) {
for i := 1; i < 11; i++ {
time.Sleep(time.Second)
fmt.Println("取出值",<-ch)
}
wg.Done()
}
var wg sync.WaitGroup
func main() {
ch := make(chan int, 100)
wg.Add(2)
go producer(ch)
go consumer(ch)
wg.Wait()
fmt.Println("process end")
}
|
14.5.5、缓冲通道
- 无缓冲的通道是指在接收前没有能力保存任何值的通道
- 有缓冲的通道是一种在被接收前能存储一个或者多个值的通道
无缓冲的通道又称为阻塞的通道。我们来看一下下面的代码:
1
2
3
4
5
|
func main() {
ch := make(chan int)
ch <- 10
fmt.Println("发送成功")
}
|
上面这段代码能够通过编译,但是执行的时候会出现以下错误:
1
2
3
4
5
|
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [chan send]:
main.main()
.../src/github.com/Q1mi/studygo/day06/channel02/main.go:8 +0x54
|
为什么会出现deadlock错误呢?
因为我们使用ch := make(chan int)创建的是无缓冲的通道,无缓冲的通道只有在有人接收值的时候才能发送值。简单来说就是无缓冲的通道必须有接收才能发送。
1
2
3
4
5
6
7
8
9
10
|
func recv(c chan int) {
ret := <-c
fmt.Println("接收成功", ret)
}
func main() {
ch := make(chan int)
go recv(ch) // 启用goroutine从通道接收值
ch <- 10
fmt.Println("发送成功")
}
|
无缓冲通道上的发送操作会阻塞,直到另一个goroutine在该通道上执行接收操作,这时值才能发送成功,两个goroutine将继续执行。相反,如果接收操作先执行,接收方的goroutine将阻塞,直到另一个goroutine在该通道上发送一个值。
使用无缓冲通道进行通信将导致发送和接收的goroutine同步化。因此,无缓冲通道也被称为同步通道。
have a try:生产者消费者模型案例改为无缓冲通道的运行结果?
14.5.6、死锁(deadlock)
案例1
当程序一直在等待从信道里读取数据,而此时并没有人会往信道中写入数据。此时程序就会陷入死循环,造成死锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func main() {
pipline := make(chan int)
wg.Add(2)
go func() {
defer wg.Done()
for i := 0; i < 10; i++ {
time.Sleep(time.Second)
pipline <- i
}
close(pipline) // 关闭chan,循环chan的协程就可以退出循环了,否则因为chan的sendq为空陷入deadlock
}()
go func() {
defer wg.Done()
for v := range pipline {
fmt.Println("v:", v)
}
}()
wg.Wait()
}
|
解决方法很简单,只要在发送完数据后,手动关闭信道,告诉 range 信道已经关闭,无需等待就行。
案例2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func recv(c chan interface{}) {
defer wg.Done()
for true {
time.Sleep(time.Second)
ret := <-c
if ret == "exit"{
close(c)
break
}
fmt.Println("接收成功", ret)
}
}
func send(c chan interface{}) {
defer wg.Done()
for i:=0;i<10;i++{
c<- i
}
c<- "exit"
// time.Sleep(time.Second*10) // 写的协程结束,导致死锁
}
func main() {
ch := make(chan interface{})
wg.Add(2)
go recv(ch) // 启用goroutine从通道接收值
go send(ch) // 启用goroutine从通道接收值
wg.Wait()
fmt.Println("end")
}
|
14.5.7、单向通道
Go语言的类型系统提供了单方向的 channel 类型,顾名思义,单向 channel 就是只能用于写入或者只能用于读取数据。当然 channel 本身必然是同时支持读写的,否则根本没法用。
我们在将一个 channel 变量传递到一个函数时,可以通过将其指定为单向 channel 变量,从而限制该函数中可以对此 channel 的操作,比如只能往这个 channel 中写入数据,或者只能从这个 channel 读取数据。
单向 channel 变量的声明非常简单,只能写入数据的通道类型为chan<-,只能读取数据的通道类型为<-chan,格式如下:
1
2
|
var 通道实例 chan<- 元素类型 // 只能写入数据的通道
var 通道实例 <-chan 元素类型 // 只能读取数据的通道
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
package main
import (
"fmt"
"sync"
"time"
)
func producer(ch chan<- int) {
for i := 1; i < 11; i++ {
ch <- i
fmt.Println("插入值", i)
}
wg.Done()
}
func consumer(ch <-chan int) {
for i := 1; i < 11; i++ {
time.Sleep(time.Second)
fmt.Println("取出值", <-ch)
}
wg.Done()
}
var wg sync.WaitGroup
func main() {
ch := make(chan int)
wg.Add(2)
go producer(ch)
go consumer(ch)
wg.Wait()
fmt.Println("end")
}
|
14.5.8、select语句
golang中的select语句格式如下
1
2
3
4
5
6
7
8
|
select {
case <-ch1:
// 如果从 ch1 信道成功接收数据,则执行该分支代码
case ch2 <- 1:
// 如果成功向 ch2 信道成功发送数据,则执行该分支代码
default:
// 如果上面都没有成功,则进入 default 分支处理流程
}
|
可以看到select的语法结构有点类似于switch,但又有些不同。select里的case后面并不带判断条件,而是一个信道的操作,不同于switch里的case,对于从其它语言转过来的开发者来说有些需要特别注意的地方。golang 的 select 就是监听 IO 操作,当 IO 操作发生时,触发相应的动作每个case语句里必须是一个IO操作,确切的说,应该是一个面向channel的IO操作。
注:Go 语言的 select 语句借鉴自 Unix 的 select() 函数,在 Unix 中,可以通过调用 select() 函数来监控一系列的文件句柄,一旦其中一个文件句柄发生了 IO 动作,该 select() 调用就会被返回(C 语言中就是这么做的),后来该机制也被用于实现高并发的 Socket 服务器程序。Go 语言直接在语言级别支持 select关键字,用于处理并发编程中通道之间异步 IO 通信问题。
注意:如果 ch1 或者 ch2 信道都阻塞的话,就会立即进入 default 分支,并不会阻塞。但是如果没有 default 语句,则会阻塞直到某个信道操作成功为止。
(1)select语句只能用于信道的读写操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
package main
import "fmt"
func main() {
size := 10
ch1 := make(chan int, size)
for i := 0; i < size; i++ {
ch1 <- 1
}
ch2 := make(chan int, size+1)
for i := 0; i < size; i++ {
ch2 <- 2
}
// select中的case语句是随机执行的
select {
case a := <-ch1:
fmt.Println("a", a)
case b := <-ch2:
fmt.Println("b", b)
case ch2 <- 200:
fmt.Println("插值成功")
default: // 如果 ch1 和 ch2 信道都阻塞的话,就会立即进入default分支
fmt.Println("default")
}
}
|
(2)超时用法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int)
go func(c chan int) {
// 修改时间后,再查看执行结果
time.Sleep(time.Second * 3)
ch <- 1
}(ch)
select {
case v := <-ch:
fmt.Print(v)
case <-time.After(2 * time.Second): // 等待 2s
fmt.Println("no case ok")
}
}
|
(3)空select
空select指的是内部不包含任何case,例如:
空的 select 语句会直接阻塞当前的goroutine,使得该goroutine进入无法被唤醒的永久休眠状态。
14.6、并发案例
14.6.1、聊天室案例
服务器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
package main
import (
"encoding/json"
"fmt"
"net"
"strings"
)
//保存用户信息的结构体
type Client struct {
Chan chan []byte //传递用户数据
Addr string //客户端的IP
}
// 消息类型
type Msg struct {
Content string // 消息内容
User string // 消息发布者
}
var onlineClients = make(map[string]Client) //保存所有用户 {"Addr":{"Addr":Addr,"Chan":Chan}}
var broadcast = make(chan Msg) // 广播管道
//监听broadcast通道中的数据,一旦有数据,循环写入每一个Client的Chan中,进而是每一个客户端收到该广播数据
func MessageManager() {
for {
msg := <-broadcast //读取message通道中的数据,如果通道中没有数据,就会一直等待。
for _, client := range onlineClients {
msgBytes, _ := json.Marshal(msg)
client.Chan <- msgBytes
}
}
}
//监听该客户端的管道,一旦有广播数据,写入socket管道,发给客户端
func WriteMsgToClient(conn net.Conn, client Client) {
for {
msgBytes := <-client.Chan //读取C通道中的数据,如果没有数据,就会一直等待
_, _ = conn.Write(msgBytes) //把json字节串数据输出到客户端
}
}
//监听该客户端的socket管道,一旦有数据,写入broadcast管道,进而发给每一个客户端
func read(conn net.Conn) {
for true {
data := make([]byte, 1024)
n, _ := conn.Read(data)
content := strings.TrimSpace(string(data[:n]))
broadcast <- Msg{Content: content, User: conn.RemoteAddr().String()}
fmt.Printf("%s发来消息:%s\n", conn.RemoteAddr().String(), content)
}
}
//为每一个客户端开启协程处理函数
func HandleConnect(conn net.Conn) {
//把客户端的用户信息保存在map对象
addr := conn.RemoteAddr().String() //获取客户端的IP
fmt.Printf("来自客户端【%s】的连接\n", addr)
//把用户信息封装成Client
client := Client{make(chan []byte), addr}
onlineClients[addr] = client
//向所有用户广播消息
content := client.Addr + "已上线!"
broadcast <- Msg{Content: content, User: "系统消息"}
//启动WriteMsgToClient的Go程
go read(conn)
go WriteMsgToClient(conn, client)
}
//主协程
func main() {
fmt.Println("聊天室服务端启动了...")
//创建一个监听器
listener, err := net.Listen("tcp", "127.0.0.1:8080")
if err != nil {
fmt.Println("net.Listen err: ", err)
return //结束主协程
}
//负责监听广播通道中的数据
go MessageManager()
for {
conn, err := listener.Accept() //阻塞方法,监听客户端的连接
if err != nil {
fmt.Println("listener.Accept err: ", err)
continue //结束当次循环
}
go HandleConnect(conn)
}
}
|
客户端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
package main
import (
"bufio"
"encoding/json"
"fmt"
"net"
"os"
"sync"
)
// 消息类型
type Msg struct {
Content string // 消息内容
User string // 消息发布者
}
func read(conn net.Conn) {
for {
res := make([]byte, 1024)
n, err := conn.Read(res)
if err != nil {
fmt.Println(err)
return
}
result := res[:n]
var msg Msg
json.Unmarshal(result,&msg)
fmt.Printf("[%s]:%s\n",msg.User,msg.Content)
}
}
func write(conn net.Conn){
for true {
reader := bufio.NewReader(os.Stdin) // 从标准输入生成读对象
content, _ := reader.ReadBytes('\n') // 读到换行
// 发送数据
conn.Write(content)
}
}
var wg sync.WaitGroup
func main() {
// 1.连接服务端
conn, err := net.Dial("tcp", "127.0.0.1:8080")
if err != nil {
fmt.Println(err)
return
}
defer conn.Close()
go read(conn)
write(conn)
}
|
14.6.2、爬虫案例
(1)爬虫程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
package main
import (
"fmt"
"io/ioutil"
"net/http"
)
func main() {
resp, err := http.Get("http://www.baidu.com")
if err != nil {
fmt.Println("err", err)
}
data, _ := ioutil.ReadAll(resp.Body)
ioutil.WriteFile("baidu.html", data, 0666)
}
|
(2)正则匹配
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
package main
import (
"fmt"
"regexp"
)
func main() {
const (
cityListReg = `<a href="(.*?)">(.*?)</a>`
)
contents := `<a href="http://www.baidu.com">百度</a> <a href="http://www.jd.com">京东</a>`
compile := regexp.MustCompile(cityListReg)
submatch := compile.FindAllSubmatch([]byte(contents), -1)
for _, m := range submatch {
//fmt.Println("url:", string(m[1]), "city:", string(m[2]))
fmt.Println("content match:", string(m[0]), string(m[1]), string(m[2]))
}
}
|
(3)爬虫斗图案例版本1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
|
package main
import (
"fmt"
"io/ioutil"
"net/http"
"regexp"
"strconv"
"strings"
"time"
)
var pageNum = 3
var reImg = `data-original="(https?://img.pkdoutu.com/production/uploads/image/[\s\S]+?.(jpg|png|jpeg|gif|null))`
var SliceImageUrls []string
func main() {
// 构建起始时间
start := time.Now().Unix()
// 2.爬虫协程:d多个协程向管道添加图片链接
for i := 1; i <= pageNum; i++ {
fmt.Println("i", i)
getImgUrls("https://www.pkdoutu.com/photo/list/?page=" + strconv.Itoa(i))
}
ConsumerImgUrl()
end := time.Now().Unix()
fmt.Println("总计用时:", end-start)
}
// 处理异常
func HandleError(err error) {
if err != nil {
fmt.Println("err:", err)
return
}
}
func ConsumerImgUrl() {
for _, url := range SliceImageUrls {
fmt.Println("url:::", url)
DownloadImg(url)
}
}
func getImgUrls(pageUrl string) {
// 获取页面字符串
pageStr := string(spiderData(pageUrl))
// 根据正则匹配筛选到符合要求的img的URL
re := regexp.MustCompile(reImg)
results := re.FindAllSubmatch([]byte(pageStr), -1)
for _, item := range results {
SliceImageUrls = append(SliceImageUrls, string(item[1]))
}
}
func getFileName(url string) string {
// 1.获取文件名和文件应该存哪
// lastIndex是最后一个/的位置
lastIndex := strings.LastIndex(url, "/")
filename := url[lastIndex+1:]
// 创建时间戳,防止重名
timePre := strconv.Itoa(int(time.Now().UnixNano()))
filename = "Doutu/" + timePre + "_" + filename
fmt.Println("filename", filename)
return filename
}
// 爬虫网络数据
func spiderData(_url string) []byte {
// 发送请求
fmt.Println("_url", _url)
resp, err := http.Get(_url)
if err != nil {
HandleError(err)
}
defer resp.Body.Close()
// 接数据
data, _ := ioutil.ReadAll(resp.Body)
return data
}
// DownloadImg 下载图片
func DownloadImg(url string) {
filename := getFileName(url)
// 2.保存文件
data := spiderData(url)
// 写文件
err := ioutil.WriteFile(filename, data, 0666)
if err != nil {
fmt.Printf("%s 下载失败 \n", filename)
HandleError(err)
}
fmt.Printf("%s 下载成功 \n", filename)
}
|
(4)爬虫斗图案例版本2
补充知识点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
package main
import (
"fmt"
"net/http"
"sync"
)
var wg sync.WaitGroup
func main() {
var c = make(chan int, 5)
wg.Add(1)
go func() {
defer wg.Done()
c <- 1
c <- 2
c <- 3
close(c)
}()
wg.Add(1)
go func() {
defer wg.Done()
for i := range c {
fmt.Println(i)
}
}()
wg.Wait()
fmt.Println("end")
}
func foo(_url string) {
res, _ := http.Get(_url)
defer res.Body.Close()
}
|
很神奇的现象,存在一个包含http.Get的函数,即使没有执行,也会使range c出现阻塞而不是死锁!!!
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
package main
import (
"fmt"
"io/ioutil"
"net/http"
"regexp"
"strconv"
"strings"
"sync"
"time"
)
var waitGroup sync.WaitGroup
var chanImageUrls = make(chan string, 10000)
var pageNum = 10
var reImg = `data-original="(https?://img.pkdoutu.com/production/uploads/image/[\s\S]+?.(jpg|png|jpeg|gif|null))`
var chanTask = make(chan string, pageNum)
func CheckProducerDone() {
var count int
for {
url := <-chanTask
fmt.Printf("%s 完成了爬取任务", url)
count++
if count == pageNum {
// 生产者完成生产任务,关闭数据管道,消费者遍历完管道数据会自动退出循环
close(chanImageUrls)
// 完成任务,跳出循环
break
}
}
}
func main() {
// 构建起始时间
start := time.Now().Unix()
// 2.爬虫协程:d多个协程向管道添加图片链接
for i := 1; i <= pageNum; i++ {
fmt.Println("i", i)
waitGroup.Add(1)
go getImgUrls("https://www.pkdoutu.com/photo/list/?page=" + strconv.Itoa(i))
}
go CheckProducerDone()
waitGroup.Add(1)
go ConsumerImgUrl()
waitGroup.Wait()
end := time.Now().Unix()
fmt.Println("总计用时:", end-start)
}
// 处理异常
func HandleError(err error) {
if err != nil {
fmt.Println("err:", err)
return
}
}
func ConsumerImgUrl() {
defer waitGroup.Done()
for i := 0; i < 10; i++ {
waitGroup.Add(1)
go func() {
defer waitGroup.Done()
for url := range chanImageUrls {
fmt.Println("url:::", url)
DownloadImg(url)
}
}()
}
}
func getImgUrls(pageUrl string) {
waitGroup.Done()
// 获取页面字符串
pageBytes := spiderData(pageUrl)
// 根据正则匹配筛选到符合要求的img的URL
re := regexp.MustCompile(reImg)
results := re.FindAllSubmatch(pageBytes, -1)
for _, item := range results {
chanImageUrls <- string(item[1])
}
fmt.Println("len chanImageUrls", len(chanImageUrls))
chanTask <- pageUrl
}
func getFileName(url string) string {
// 1.获取文件名和文件应该存哪
// lastIndex是最后一个/的位置
lastIndex := strings.LastIndex(url, "/")
filename := url[lastIndex+1:]
// 创建时间戳,防止重名
timePre := strconv.Itoa(int(time.Now().UnixNano()))
filename = "Doutu/" + timePre + "_" + filename
fmt.Println("filename", filename)
return filename
}
// 爬虫网络数据
func spiderData(_url string) []byte {
// 发送请求
fmt.Println("_url", _url)
resp, err := http.Get(_url)
if err != nil {
HandleError(err)
}
defer resp.Body.Close()
// 接数据
data, _ := ioutil.ReadAll(resp.Body)
return data
}
// DownloadImg 下载图片
func DownloadImg(url string) {
filename := getFileName(url)
// 2.保存文件
data := spiderData(url)
// 写文件
err := ioutil.WriteFile(filename, data, 0666)
if err != nil {
fmt.Printf("%s 下载失败 \n", filename)
HandleError(err)
}
fmt.Printf("%s 下载成功 \n", filename)
}
|