- 从0开始入手到上手一个新的框架,应该怎么展开?
- flask这种轻量级的框架与django这种的重量级框架的区别?
- 针对web开发过程中,常见的数据库ORM的操作。
- 跟着flask学习过程的过程中,自己去了解一个新的框架(sanic,FastAPI)
旧的框架(同步为主):django,flask和 (异步)tornado,(异步)twisted
新的框架(异步为主):sanic,FastAPI,django3.0(从同步到异步改造过程中),flask2.0(从同步到异步改造过程中)
Sanic:https://sanic.readthedocs.io/en/stable/
FastAPI:https://fastapi.tiangolo.com/

Flask
Flask诞生于2010年,是Armin ronacher(人名)用 Python 语言基于 Werkzeug 工具箱编写的轻量级Web开发框架。
Flask 本身相当于一个内核,其他几乎所有的功能都要用到扩展(邮件扩展Flask-Mail,用户认证Flask-Login,数据库Flask-SQLAlchemy),都需要用第三方的扩展来实现。比如可以用 Flask 扩展加入ORM、窗体验证工具,文件上传、身份验证等。Flask 没有默认使用的数据库,你可以选择 MySQL,也可以用 NoSQL。
其 WSGI 工具箱采用 Werkzeug(路由模块),模板引擎则使用 Jinja2。Itsdangrous,click这两个也是 Flask 框架的核心。
官网: https://flask.palletsprojects.com/en/2.0.x/
官方文档: http://docs.jinkan.org/docs/flask/(文档比较旧,仅做参考。当然2.0版本的flask和1.0版本的flask区别不大.)
Flask常用第三方扩展包:
- Flask-SQLalchemy:操作数据库,ORM;
- Flask-script:终端脚本工具,脚手架; ( 淘汰,官方内置了一个全局命令:Flask )
- Flask-migrate:管理迁移数据库;
- Flask-Session:Session存储方式指定;
- Flask-Mail:邮件;
- Flask-Login:认证用户状态;(django内置Auth模块,用于实现用户登录退出,)
- Flask-OpenID:认证, OAuth;(三方授权,)
- Flask-RESTful:开发REST API的工具;
- Flask JSON-RPC: 开发json-rpc远程服务[过程]调用
- Flask-Bable:提供国际化和本地化支持,翻译;
- Flask-Moment:本地化日期和时间
- Flask-Admin:简单而可扩展的管理接口的框架
- Flask-Bootstrap:集成前端Twitter Bootstrap框架(前后端分离,基本不用这玩意)
- Flask-WTF:表单;(前后端分离,基本不用这玩意)
- marshmallow:序列化(django restframework内置了)
可以通过 https://pypi.org/search/?c=Framework+%3A%3A+Flask 查看更多flask官方推荐的扩展
准备
1
2
3
4
5
6
7
|
# anaconda创建虚拟环境
conda create -n flask python=3.8
# 进入/切换到指定名称的虚拟环境,如果不带任何参数,则默认回到全局环境base中。
# conda activate <虚拟环境名称>
conda activate flask
# 退出当前虚拟环境
conda deactivate
|
安装flask,则以下命令:
pip install flask -i https://pypi.douban.com/simple
创建flask项目
与django不同,flask不会提供任何的自动操作,所以需要手动创建项目目录,需要手动创建启动项目的管理文件
例如,创建项目目录 flaskdemo,在目录中创建manage.py.在pycharm中打开项目并指定上面创建的虚拟环境
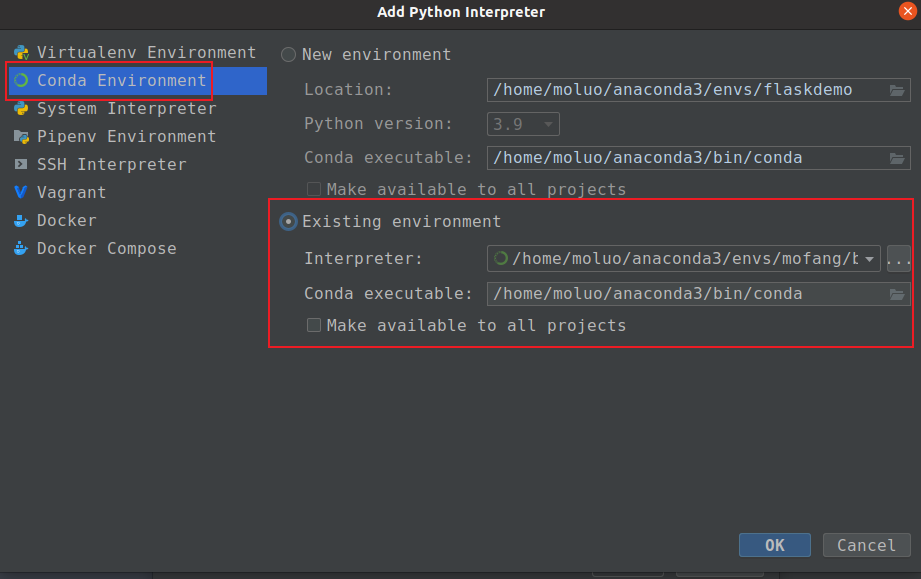
创建一个flask框架的启动文件。名字可以是app.py/run.py/main.py/index.py/manage.py/start.py
manage.py,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
from flask import Flask
# 应用实例对象
app = Flask(__name__)
# 编写函数视图
@app.route("/")
def index():
return "hello, flask!!!<br>hello, python"
@app.route("/login")
def login():
return "login form"
if __name__ == '__main__':
# 启动项目的web应用程序
# app.run(host="0.0.0.0",port=5000, debug=True)
app.run() # 默认值, host="127.0.0.1",port=5000, debug=False
|
代码分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 导入Flask类
from flask import Flask
"""
Flask类的实例化参数:
import_name Flask程序所在的包(模块),传 __name__ 就可以
其可以决定 Flask 在访问静态文件时查找的路径
static_path 静态文件存储访问路径(不推荐使用,使用 static_url_path 代替)
static_url_path 静态文件url访问路径,可以不传,默认为:/ + static_folder
static_folder 静态文件存储的文件夹,可以不传,默认为 static
template_folder 模板文件存储的文件夹,可以不传,默认为 templates
"""
app = Flask(__name__)
# 编写路由视图
# flask的路由是通过给视图添加装饰器的方式进行编写的。当然也可以分离到另一个文件中。
# flask的视图函数,flask中默认允许通过return返回html格式数据给客户端。
@app.route('/')
def index():
# 返回值如果是字符串,被自动作为参数传递给response对象进行实例化返回客户端
return "hello, flask!!!<br>hello, python"
# 指定服务器IP和端口
if __name__ == '__main__':
# 运行flask
app.run(host="0.0.0.0", port=5000)
|
路由的基本定义
路由和视图的名称必须全局唯一,不能出现重复,否则报错。
1
2
3
4
|
# 指定访问路径为 demo1
@app.route('/demo1')
def demo1():
return 'demo1'
|
什么是路由?
路由就是一种映射关系。是绑定应用程序(视图)和url地址的一种一对一的映射关系!我们在开发过程中,编写项目时所使用的路由往往是指代了框架/项目中用于完成路由功能的类,这个类一般就是路由类,简称路由。
url中可以传递路由参数, 2种方式
路由参数就是url路径的一部分。
接收任意路由参数
1
2
3
4
|
# 路由传递参数[没有限定类型]
@app.route('/user/<user_id>')
def user_info(user_id):
return f'hello {user_id}'
|
接收限定类型参数
限定路由参数的类型,flask系统自带转换器编写在werkzeug/routing.py文件中。底部可以看到以下字典:
1
2
3
4
5
6
7
8
9
|
DEFAULT_CONVERTERS = {
"default": UnicodeConverter,
"string": UnicodeConverter,
"any": AnyConverter,
"path": PathConverter,
"int": IntegerConverter,
"float": FloatConverter,
"uuid": UUIDConverter,
}
|
系统自带的转换器具体使用方式在每种转换器的注释代码中有写,请留意每种转换器初始化的参数。
| 转换器名称 |
描述 |
| string |
默认类型,接受不带斜杠的任何文本 |
| int |
接受正整数 |
| float |
接受正浮点值 |
| path |
接收string但也接受斜线 |
| uuid |
接受UUID(通用唯一识别码)字符串 xxxx-xxxx-xxxxx-xxxxx |
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
# 限定类型传递路由参数
# flask内置的所有路由转换器是由werkzeug.routing的DEFAULT_CONVERTERS字典进行配置的。
# flask的所有路由转换器,本质上就是路由经过正则来进行匹配获取参数值的。所有的路由转换器都必须直接或间接继承于BaseConverter路由转换器基类
from flask import Flask
# 应用实例对象
app = Flask(__name__)
# 路由
@app.route(rule='/demo1')
def demo1():
return 'demo1'
# 路由参数[不限定数据类型]
@app.route('/user/<user_id>')
def user(user_id): # 必须在视图方法中,通过变量名来接受参数
return f'hello {user_id}'
# 路由参数[限定数据类型]
@app.route("/sms1/<int:num>")
def sms1(num):
return f"发送短信{num}条"
@app.route("/sms2/<int(min=1, max=100):num>")
def sms2(num):
return f"发送短信{num}条"
@app.route("/sms3/<string(minlength=11, maxlength=11):mobile>")
def sms3(mobile):
return f"发送短信给手机号:{mobile}"
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
自定义路由参数转换器
也叫正则匹配路由参数.
在 web 开发中,可能会出现限制用户访问规则的场景,那么这个时候就需要用到正则匹配,根据自己的规则去限定请求参数再进行访问
具体实现步骤为:
- 导入转换器基类BaseConverter:在 Flask 中,所有的路由的匹配规则都是使用转换器对象进行记录
- 自定义转换器:自定义类继承于转换器基类BaseConverter
- 添加转换器到默认的转换器字典中
- 使用自定义转换器实现自定义匹配规则
代码实现
1
|
from werkzeug.routing import BaseConverter
|
1
2
3
4
5
6
7
|
# 自定义正则转换器
from werkzeug.routing import BaseConverter
class RegexConverter(BaseConverter):
def __init__(self,map,*args):
super().__init__(map)
# 正则参数
self.regex = args[0]
|
- 添加转换器到默认的转换器字典中,并指定转换器使用时名字为: re
1
2
|
# 将自定义转换器添加到转换器字典中,并指定转换器使用时名字为: re
app.url_map.converters['re'] = RegexConverter
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# 自定义路由转换器
from werkzeug.routing import BaseConverter
class RegexConverter(BaseConverter):
def __init__(self,map,*args):
super().__init__(map)
# 正则参数
self.regex = args[0]
# 将自定义转换器添加到转换器字典中,并指定转换器使用时名字为: re
app.url_map.converters['re'] = RegexConverter
# 正则匹配路由
@app.route("/sms/<re('1[3-9]\d{9}'):mobile>")
def sms(mobile):
return f"mobile={mobile}"
|
运行测试:http://127.0.0.1:5000/login/1311111111 ,如果访问的url不符合规则,会提示找不到页面
课堂代码:
routing.py,代码:
1
2
3
4
5
6
7
8
9
|
from werkzeug.routing import BaseConverter
class RegexConverter(BaseConverter):
"""自定义路由转换器,支持采用正则参数"""
def __init__(self,map, *args):
super().__init__(map)
# 正则参数
self.regex = args[0]
|
manage.py,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
from flask import Flask
from routing import RegexConverter
# 应用实例对象
app = Flask(__name__)
# 注册路由转换到app实例对象,并给转换器声明一个调用别名re
app.url_map.converters['re'] = RegexConverter
# 路由参数[自定义路由转换器,自己编写限定规则]
@app.route("/sms/<re('1[3-9]\d{9}'):mobile>")
def sms(mobile):
return f"发送短信给手机号:{mobile}"
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
限定http请求方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
|
import json
from urllib.parse import parse_qs
from flask import Flask, request
# 应用实例对象
app = Flask(__name__)
# 限制客户端的http请求方法
# 没有指定route的第二个参数时,默认 methods = ["get"]
@app.route("/")
def index():
return f"默认首页"
# 注意这里与django不一样,flask并没有默认没有内置csrf攻击防范,flask-wtf
@app.route("/student/add/", methods=["post"])
def student():
# request对象时flask启动以后,就默认提供的全局对象,这个全局对象,只能用于客户端的请求,在每次客户端发送请求过来的时候,
# request对象中的属性数据都会被重新赋值。
print(request)
"""打印效果:
<Request 'http://127.0.0.1:5000/student/add/' [POST]>
"""
# 获取http请求动作/请求方法
print(request.method)
"""打印效果:
POST
"""
# 获取请求体信息
print(request.data)
"""
打印效果:
b'{\n "username":"xaoming",\n "description":"\xe6\x88\x91\xe6\x98\xaf\xe4\xb8\xad\xe5\x9b\xbd\xe4\xba\xba\xef\xbc\x8c\xe6\x88\x91\xe6\x9d\xa5\xe8\x87\xaa\xe5\x8c\x97\xe4\xba\xac\xe3\x80\x82" \n}'
"""
# 解析json数据
data = json.loads(request.data)
print(data)
"""打印效果:
{'username': 'xaoming', 'description': '我是中国人,我来自北京。'}
"""
# 获取查询字符串
print(request.query_string)
"""打印效果:
b'uid=100&lve=shopping&lve=code'
"""
# 解析原生的查询字符串
query = parse_qs(request.query_string.decode())
print(query)
"""打印效果:
{'uid': ['100'], 'lve': ['shopping', 'code']}
"""
# 获取客户端的访问路径
print(request.path)
"""打印效果:
/student/add/
"""
return f"添加学生信息"
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
终端运行Flask项目
1
2
3
4
5
6
|
# 1. 找到创建flask应用的模块路径,例如:manage.py
# 则ubuntu等Linux下的终端:
export FLASK_APP=manage.py
# 2. 在当前虚拟环境中,如果安装了flask模块,则可以使用全局命令flask run,即可运行flask项目
flask run # 采用默认的127.0.0.1 和 5000端口运行项目
flask run --host=0.0.0.0 --port=8088 # 可以改绑定域名IP和端口
|
http的请求与响应
请求
文档: https://flask.palletsprojects.com/en/2.0.x/api/#flask.Request
- request:flask中代表当前请求的
request 对象
- 作用:在视图函数中取出本次客户端的请求数据
- 导入:
from flask import request
- 代码位置:
-
代理类 from flask.app import Request ---> from flask.globals.Request
-
源码类:from flask.wrappers.Request
-
基类:from werkzeug.wrappers import Request as RequestBase
request,常用的属性如下:
| 属性 |
说明 |
类型 |
| data |
记录请求体的数据,并转换为字符串只要是通过其他属性无法识别转换的请求体数据最终都是保留到data属性中例如:有些公司开发小程序,原生IOS或者安卓,这一类客户端有时候发送过来的数据就不一样是普通的表单,查询字符串或ajax |
bytes类型 |
| form |
记录请求中的html表单数据 |
ImmutableMultiDict |
| args |
记录请求中的查询字符串,也可以是query_string |
ImmutableMultiDict |
| cookies |
记录请求中的cookie信息 |
Dict |
| headers |
记录请求中的请求头 |
ImmutableMultiDict |
| method |
记录请求使用的HTTP方法 |
GET/POST |
| url |
记录请求的URL地址 |
string |
| files |
记录请求上传的文件列表 |
ImmutableMultiDict |
| json |
记录ajax请求的json数据 |
json |
获取请求中各项数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
|
from flask import Flask, request
app = Flask(import_name=__name__)
# 配置类
class Config(object):
DEBUG = True # 开启调试模式
# 加载配置
app.config.from_object(Config)
@app.route("/",methods=["get"])
def index():
print(request) # 请求对象
print(request.__dir__()) # 请求对象 dir(request)
return "<h1>返回结果</h1>"
# 请求处理
""" 获取查询字符串 """
@app.route(rule="/args",methods=["post","get","delete","put","patch"])
def args():
# url1 /args?name=xiaoming&age=12
# url2 /args?name=xiaoming&age=12&lve=ball&lve=shopping
print(request.args) # 获取查询字符串所有数据,并返回有序字典
"""
url1: ImmutableMultiDict([('name', 'xiaoming'), ('age', '12')])
url2: ImmutableMultiDict([('name', 'xiaoming'), ('age', '12'), ('lve', 'ball'), ('lve', 'shopping')])
备注:
from werkzeug.datastructures import ImmutableMultiDict
ImmutableMultiDict是一个由flask封装的字典类,主要是为了解决一个key对应多个value的需求,所以在字典dict的基础上继承了操作,并提供了一些其他的方法而已。
格式:
ImmutableMultiDict([('键', '值'), ('键', '值')])
字典本身不支持同名键的,ImmutableMultiDict类解决了键同名问题
操作ImmutableMultiDict,完全可以操作字典操作,同时还提供了get,getlist方法,获取指定键的1个值或多个值
"""
print(request.args.get("name"))
"""
url1: xiaoming
url2: xiaoming
"""
print(request.args.get("lve"))
"""
url1: None
url2: ball
"""
print(request.args.getlist("lve"))
"""
url1: []
url2: ['ball', 'shopping']
"""
# print(request.args["love"])
"""
报错:KeyError: 'love'
"""
# 当所有参数都是单个值的情况下,使用to_dict()
print(request.args.to_dict())
"""
url1: {'name': 'xiaoming', 'age': '12'}
url2: {'name': 'xiaoming', 'age': '12', 'lve': 'ball'}
"""
# 当所有参数中,有部分参数是多个值的情况下,使用to_dict(flat=False)
print(request.args.to_dict(flat=False))
"""
url1: {'name': ['xiaoming'], 'age': ['12']}
url2: {'name': ['xiaoming'], 'age': ['12'], 'lve': ['ball', 'shopping']}
"""
return "获取查询字符串参数,不限制http请求"
""" 获取请求体数据 """
@app.route(rule="/data", methods=["post", "put", "patch"])
def data():
# 获取原生的请求体数据[当request对象的其他属性没法接受请求体数据时,会把数据保留在data中,如果有request对象的属性处理了请求体数据,则data就不再保留]
print(request.data)
print(request.get_data())
"""
1. 没有上传任何数据:
b''
2. 上传json数据
b'{\n "username": "xiaoming",\n "age": 16\n}'
3. 上传表单数据
b''
"""
# 接收表单上传的数据
print(request.form)
"""
ImmutableMultiDict([('username', 'xiaoming'), ('age', '16')])
"""
# 接收ajax上传的json数据
print(request.json) # {'username': 'xiaoming', 'age': 16}
print(request.is_json) # True
print(request.get_json()) # {'username': 'xiaoming', 'age': 16}
# 上传文件列表 HTML必须以<form method="post" enctype="multipart/form-data"> # 表单属性才能上传文件
print(request.files)
"""
ImmutableMultiDict([('avatar', <FileStorage: '2.jpg' ('image/jpeg')>)])
"""
# 接受上传文件
avatar = request.files["avatar"]
print(avatar)
"""
<FileStorage: '2.jpg' ('image/jpeg')>
from werkzeug.datastructures import FileStorage
FileStorage,上传文件处理对象,flask封装的一个上传文件处理对象,可以允许我们直接调用对应的方法进行文件的存储处理,
也可以结合其他的ORM模块像djangoORM那样通过模型操作对上传自动存储处理
"""
# 处理上传文件[一般不会这么做!!!]
from pathlib import Path
save_path = str(Path(__file__).parent / "uploads/avatar.jpeg")
avatar.save(save_path)
# 获取请求头信息
print(request.headers) # 获取全部的而请求头信息
print(request.headers.get("Host")) # 127.0.0.1:5000
# 获取自定义请求头
print(request.headers.get("company")) # python,不存在的键的结果:None,存在则得到就是值,
print(request.headers["company"]) # python,不存在的键会导致报错
# 获取请求方法
print( request.method) # POST
# 本次请求的url地址
print( request.url) # http://127.0.0.1:5000/data
print( request.path ) # /data
return "ok"
if __name__ == '__main__':
app.run()
|
响应
flask默认支持2种响应方式:
数据响应: 默认响应html文本,也可以返回 JSON格式,或其他格式
页面响应: 重定向
url_for 视图之间的跳转
响应的时候,flask也支持自定义http响应状态码
响应html文本
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from flask import Flask, make_response
from flask.wrappers import Response
# 应用实例对象
app = Flask(__name__)
@app.route("/")
def index():
# 默认返回的就是HTML代码,在flask内部调用视图时,得到的返回值会被flask判断类型,
# 如果类型不是response对象,则视图的返回值会被作为response对象的实例参数返回客户端
# return f"默认首页", 201, {"company": "python-35"}
# return make_response(f"默认首页",201, {"company": "python-35"})
return Response(f"默认首页",201, {"company": "python-35"})
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
返回JSON数据
在 Flask 中可以直接使用 jsonify 生成一个 JSON 的响应
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
from flask import Flask, make_response, jsonify
from flask.wrappers import Response
# 应用实例对象
app = Flask(__name__)
@app.route("/json")
def json():
"""返回json数据"""
# """返回json格式数据,返回json字典"""
# data = {"name":"xiaoming","age":16}
# return data
# """返回json格式数据,返回各种json数据,包括列表"""
data = [
{"id": 1, "username": "liulaoshi", "age": 18},
{"id": 2, "username": "liulaoshi", "age": 17},
{"id": 3, "username": "liulaoshi", "age": 16},
{"id": 4, "username": "liulaoshi", "age": 15},
]
return jsonify(data)
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
flask中返回json 数据,都是flask的jsonify方法返回就可以了,直接return只能返回字典格式的json数据。
重定向
重定向到站点地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from flask import Flask, redirect
# 应用实例对象
app = Flask(__name__)
@app.route("/")
def index():
"""页面跳转"""
"""
301: 永久重定向,页面已经没有了,站点没有了,永久转移了。
302:临时重定向,一般验证失败、访问需要权限的页面进行登录跳转时,都是属于临时跳转。
"""
# redirect函数就是response对象的页面跳转的封装
# response = redirect("http://www.qq.com", 302)
# redirect的原理,最终还是借助Resonse对象来实现:
response = "", 302, {"Location": "http://www.163.com"}
return response
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
重定向到自己写的视图函数
可以直接填写自己 url 路径
也可以使用 url_for 生成指定视图函数所对应的 url
from flask import url_for
1
2
3
4
5
6
7
8
9
|
@app.route("/info")
def info():
return "info"
@app.route("/user")
def user():
url = url_for("info")
print(url)
return redirect(url)
|
重定向到带有路径参数的视图函数
在 url_for 函数中传入参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from flask import Flask, redirect, url_for
# 应用实例对象
app = Flask(__name__)
@app.route("/demo/<int:mob>")
def mobile(mob):
print(mob)
return f"mobile={mob}"
@app.route("/sms")
def sms():
"""携带路径参数进行站内跳转"""
# url_for("视图方法名", 路由路径参数)
url = url_for("mobile", mob=13312345678)
print(url)
return redirect(url)
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
自定义状态码和响应头
在 Flask 中,可以很方便的返回自定义状态码,以实现不符合 http 协议的状态码,例如:status code: 666
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from flask import Flask, redirect, url_for, make_response, Response
# 应用实例对象
app = Flask(__name__)
@app.route("/rep")
def rep():
"""常用以下写法"""
return "ok", 201, {"Company":"python-35"}
# """原理"""
# response = make_response("ok", 201, {"Company": "python-35"})
# return response
#
# """原理"""
# response = Response("ok")
# response.headers["Company"] = "oldboy" # 自定义响应头
# response.status_code = 201 # 自定义响应状态码
# return response
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
http的会话控制
所谓的会话(session),就是客户端浏览器和服务端网站之间一次完整的交互过程.
会话的开始是在用户通过浏览器第一次访问服务端网站开始.
会话的结束时在用户通过关闭浏览器以后,与服务端断开.
所谓的会话控制,就是在客户端浏览器和服务端网站之间,进行多次http请求响应之间,记录、跟踪和识别用户的信息而已。
因为 http 是一种无状态协议,浏览器请求服务器是无状态的。
无状态:指一次用户请求时,浏览器、服务器无法知道之前这个用户做过什么,每次请求都是一次新的请求。
无状态原因:浏览器与服务器是使用 socket 套接字进行通信的,服务器将请求结果返回给浏览器之后,会关闭当前的 socket 连接,而且客户端也会在处理页面完毕之后销毁页面对象。
有时需要保持下来用户浏览的状态,比如用户是否登录过,浏览过哪些商品等
实现状态保持主要有两种方式:
- 在客户端存储信息使用
Cookie(废弃),token[jwt,oauth]
- 在服务器端存储信息使用
Session
Cookie
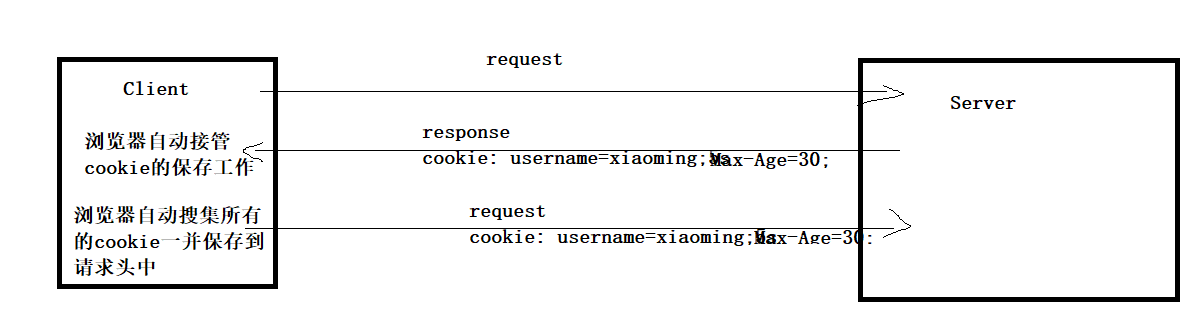
Cookie是由服务器端生成,发送给客户端浏览器,浏览器会将Cookie的key/value保存,下次请求同一网站时就发送该Cookie给服务器(前提是浏览器设置为启用cookie)。Cookie的key/value可以由服务器端自己定义。
使用场景: 登录状态, 浏览历史, 网站足迹,购物车 [不登录也可以使用购物车]
Cookie是存储在浏览器中的一段纯文本信息,建议不要存储敏感信息如密码,因为电脑上的浏览器可能被其它人使用
Cookie基于域名安全,不同域名的Cookie是不能互相访问的
如访问fuguang.com时向浏览器中写了Cookie信息,使用同一浏览器访问baidu.com时,无法访问到fuguang.com写的Cookie信息,只能获取到baidu.com的Cookie信息。
浏览器的同源策略针对cookie也有限制作用.
当浏览器请求某网站时,浏览器会自动将本网站下所有Cookie信息随着http请求提交给服务器,所以在request中可以读取Cookie信息
设置cookie
设置cookie需要通过flask的Response响应对象来进行设置,由响应对象会提供了方法set_cookie给我们可以快速设置cookie信息。
1
2
3
4
5
6
7
|
@app.route("/set_cookie")
def set_cookie():
"""设置cookie,通过response传递到客户端进行保存"""
response = make_response('默认首页')
response.set_cookie('username', 'xiaoming') # session会话期有效,关闭浏览器后当前cookie就会被删除
response.set_cookie('user', 'xiaoming', max_age=30 ) # 指定有效时间,过期以后浏览器删除cookie,max_age=150秒
return response
|
获取cookie
1
2
3
4
5
6
7
8
|
@app.route("/get_cookie")
def get_cookie():
"""获取来自客户端的cookie"""
print(request.cookies) # ImmutableMultiDict([])
username = request.cookies.get('username') # 没有值则返回None
user = request.cookies.get('user') # 没有值则返回None
print(f"username={username},user={user}") # username=xiaoming,user=xiaoming
return "get cookie"
|
删除cookie
1
2
3
4
5
6
7
8
|
@app.route("/del_cookie")
def del_cookie():
"""删除cookie,重新设置cookie的时间,让浏览器自己根据有效期来删除"""
response = make_response('del cookie')
# 删除操作肯定是在浏览器完成的,所以我们重置下cookie名称的对饮有效时间为0,此时cookie的值已经不重要了。
response.set_cookie('user', '', max_age=0)
response.set_cookie('username', '', max_age=0)
return response
|
Session
对于敏感、重要的信息,建议要存储在服务器端,不能存储在浏览器中,如手机号、验证码等信息
在服务器端进行状态保持的方案就是Session
Session依赖于Cookie,session的ID一般默认通过cookie来保存到客户端。名字一般叫:sessionid
flask中的session需要加密,所以使用session之前必须配置SECRET_KEY选项,否则报错.
session的有效期默认是会话期,会话结束了,session就废弃了。
如果将来希望session的生命周期延长,可以通过修改cookie中的sessionID的有效期来完成配置。
设置session
1
2
3
4
5
6
7
8
9
|
@app.route("/set_session")
def set_session():
"""设置session"""
session['username'] = 'xiaoming'
session['info'] = {
"name": "xiaohong",
"age": 16,
}
return "set_session"
|
可以通过客户端浏览器中的sessionid观察,其实默认情况下,flask中的session数据会被加密保存到cookie中的。当然,将来,我们可以采用flask-session模块把数据转存到其他的存储设备,例如:redis中。
获取session
1
2
3
4
5
6
|
@app.route("/get_session")
def get_session():
"""获取session"""
print(session.get('username'))
print(session.get('info'))
return "get session"
|
删除session
1
2
3
4
5
6
7
8
|
@app.route("/del_session")
def del_session():
"""删除session,键如果不存在,则会抛出异常,所以删除之前需要判断键是否存在。"""
if "username" in session:
session.pop("username")
if "info" in session:
session.pop("info")
return "del_session"
|
使用过程中,session是依赖于Cookie的,所以当cookie在客户端被删除时,对应的session就无法被使用了。
请求钩子[hook]
在客户端和服务器交互的过程中,有些准备工作或扫尾工作需要处理,比如:
- 在项目运行开始时,建立数据库连接;
- 在客户端请求开始时,根据需求进行权限校验;
- 在请求结束视图返回数据时,指定数据的交互格式;
为了让每个视图函数避免编写重复功能的代码,Flask提供了通用设置的功能,即请求钩子。
请求钩子是通过装饰器的形式实现,Flask支持如下四种请求钩子(注意:钩子的装饰器名字是固定):
- before_first_request
- 在处理第一个请求前执行[项目刚运行第一次被客户端请求时执行的钩子]
- before_request
- 在每一次请求前执行[项目运行后,每一次接收到客户端的request请求都会执行一次]
- 如果在某修饰的函数中返回了一个响应,视图函数将不再被调用
- after_request
- 如果没有抛出错误,在每次请求后执行
- 接受一个参数:视图函数作出的响应
- 在此函数中可以对响应值在返回之前做最后一步修改处理
- 需要将参数中的响应在此参数中进行返回
- teardown_request:
- 在每一次请求后执行
- 接受一个参数:错误信息,如果有相关错误抛出
- 需要设置flask的配置DEBUG=False,teardown_request才会接受到异常对象。
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
from flask import Flask, session
# 应用实例对象
app = Flask(__name__)
"""给app单独设置配置项"""
# 设置秘钥
app.config["SECRET_KEY"] = "my SECRET KEY"
@app.before_first_request
def before_first_request():
"""
这个钩子会在项目启动后第一次被用户访问时执行
可以编写一些初始化项目的代码,例如,数据库初始化,加载一些可以延后引入的全局配置
"""
print("----before_first_request----")
print("系统初始化的时候,执行这个钩子方法")
print("会在接收到第一个客户端请求时,执行这里的代码")
@app.before_request
def before_request():
"""
这个钩子会在每次客户端访问视图的时候执行
# 可以在请求之前进行用户的身份识别,以及对于本次访问的用户权限等进行判断。..
"""
print("----before_request----")
print("每一次接收到客户端请求时,执行这个钩子方法")
print("一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据")
@app.after_request
def after_request(response):
print("----after_request----")
print("在处理请求以后,执行这个钩子方法")
print("一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作")
response.headers["Content-Type"] = "application/json"
response.headers["Company"] = "python oldboy..."
# 必须返回response参数
return response
@app.teardown_request
def teardown_request(exc):
print("----teardown_request----")
print("在每一次请求以后,执行这个钩子方法")
print("如果有异常错误,则会传递错误异常对象到当前方法的参数中")
# 在项目关闭了DEBUG模式以后,则异常信息就会被传递到exc中,我们可以记录异常信息到日志文件中
print(f"错误提示:{exc}") # 异常提示
@app.route("/")
def index():
print("-----------视图函数执行了---------------")
return "ok"
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=False)
|
- 在第1次请求时的打印(关闭DEBUG模式,视图代码正确执行,没有异常的情况):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
----before_first_request----
系统初始化的时候,执行这个钩子方法
会在接收到第一个客户端请求时,执行这里的代码
----before_request----
每一次接收到客户端请求时,执行这个钩子方法
一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据
-----------视图函数执行了---------------
----after_request----
在处理请求以后,执行这个钩子方法
一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作
----teardown_request----
在每一次请求以后,执行这个钩子方法
如果有异常错误,则会传递错误异常对象到当前方法的参数中
错误提示:None
|
- 在第2次请求时的打印(关闭DEBUG模式,视图代码正确执行,没有异常的情况):
1
2
3
4
5
6
7
8
9
10
11
|
----before_request----
每一次接收到客户端请求时,执行这个钩子方法
一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据
-----------视图函数执行了---------------
----after_request----
在处理请求以后,执行这个钩子方法
一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作
----teardown_request----
在每一次请求以后,执行这个钩子方法
如果有异常错误,则会传递错误异常对象到当前方法的参数中
错误提示:None
|
在第1次请求时的打印(关闭DEBUG模式,视图执行错误,有异常的情况):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
----before_first_request----
系统初始化的时候,执行这个钩子方法
会在接收到第一个客户端请求时,执行这里的代码
----before_request----
每一次接收到客户端请求时,执行这个钩子方法
一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据
-----------视图函数执行了---------------
----after_request----
在处理请求以后,执行这个钩子方法
一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作
----teardown_request----
在每一次请求以后,执行这个钩子方法
如果有异常错误,则会传递错误异常对象到当前方法的参数中
错误提示:division by zero
|
在第1次请求时的打印(关闭DEBUG模式,视图执行有异常的情况):
1
2
3
4
5
6
7
8
9
10
11
|
----before_request----
每一次接收到客户端请求时,执行这个钩子方法
一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据
-----------视图函数执行了---------------
----after_request----
在处理请求以后,执行这个钩子方法
一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作
----teardown_request----
在每一次请求以后,执行这个钩子方法
如果有异常错误,则会传递错误异常对象到当前方法的参数中
错误提示:division by zero
|
钩子装饰器装饰了多个函数的执行顺序如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
from flask import Flask, session
# 应用实例对象
app = Flask(__name__)
"""给app单独设置配置项"""
# 设置秘钥
app.config["SECRET_KEY"] = "my SECRET KEY"
@app.before_first_request
def before_first_request():
"""
这个钩子会在项目启动后第一次被用户访问时执行
可以编写一些初始化项目的代码,例如,数据库初始化,加载一些可以延后引入的全局配置
"""
print("----before_first_request----")
print("系统初始化的时候,执行这个钩子方法")
print("会在接收到第一个客户端请求时,执行这里的代码")
@app.before_request
def before_request():
"""
这个钩子会在每次客户端访问视图的时候执行
# 可以在请求之前进行用户的身份识别,以及对于本次访问的用户权限等进行判断。..
"""
print("----before_request----")
print("每一次接收到客户端请求时,执行这个钩子方法")
print("一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据")
@app.after_request
def after_request1(response):
print("----after_request1----")
print("在处理请求以后,执行这个钩子方法")
print("一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作")
response.headers["Content-Type"] = "application/json"
response.headers["Company"] = "python oldboy..."
# 必须返回response参数
return response
@app.after_request
def after_request2(response):
print("----after_request2----")
# 必须返回response参数
return response
@app.after_request
def after_request3(response):
print("----after_request3----")
# 必须返回response参数
return response
@app.teardown_request
def teardown_request(exc):
print("----teardown_request----")
print("在每一次请求以后,执行这个钩子方法")
print("如果有异常错误,则会传递错误异常对象到当前方法的参数中")
# 在项目关闭了DEBUG模式以后,则异常信息就会被传递到exc中,我们可以记录异常信息到日志文件中
print(f"错误提示:{exc}") # 异常提示
@app.route("/")
def index():
print("-----------视图函数执行了---------------")
return "ok"
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=False)
|
执行效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
----before_first_request----
系统初始化的时候,执行这个钩子方法
会在接收到第一个客户端请求时,执行这里的代码
----before_request----
每一次接收到客户端请求时,执行这个钩子方法
一般可以用来判断权限,或者转换路由参数或者预处理客户端请求的数据
-----------视图函数执行了---------------
----after_request3----
----after_request2----
----after_request1----
在处理请求以后,执行这个钩子方法
一般可以用于记录会员/管理员的操作历史,浏览历史,清理收尾的工作
----teardown_request----
在每一次请求以后,执行这个钩子方法
如果有异常错误,则会传递错误异常对象到当前方法的参数中
错误提示:None
|
结论:后装饰的先执行。
异常抛出和捕获
主动抛出HTTP异常
- abort 方法
- 抛出一个给定状态代码的 HTTPException 或者 指定响应,例如想要用一个页面未找到异常来终止请求,你可以调用 abort(404)
- 参数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
from flask import Flask,abort,request
app = Flask(import_name=__name__)
# 配置类
class Config(object):
DEBUG = True # 开启调试模式
# 加载配置
app.config.from_object(Config)
@app.route("/")
def index():
# try:
# 1/0
# except:
# abort(500)
username = request.args.get("username")
if username is None:
abort(400)
return "ok"
if __name__ == '__main__':
app.run()
|
abort,只能抛出 HTTP 协议的错误状态码,一般用于权限等页面上错误的展示提示.
abort 在有些公司里面不会被使用,往往在业务错误的时候使用raise进行抛出错误类型,而不是抛出http异常。
捕获错误
- app.errorhandler 装饰器
- 注册一个错误处理程序,当程序抛出指定错误状态码的时候,就会调用该装饰器所装饰的方法
- 参数:
- code_or_exception – HTTP的错误状态码或指定异常
- 例如统一处理状态码为500的错误给用户友好的提示:
1
2
3
|
@app.errorhandler(500)
def internal_server_error(e):
return '服务器搬家了'
|
1
2
3
|
@app.errorhandler(ZeroDivisionError)
def zero_division_error(e):
return '除数不能为0'
|
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
from flask import Flask, request, abort
# 应用实例对象
app = Flask(__name__)
class APIError(Exception):
pass
"""异常抛出"""
@app.route("/")
def index():
username = request.args.get("username")
if username is None:
abort(400)
if username != "xiaoming":
raise APIError
return "ok"
@app.errorhandler(400)
def internal_server_error(e):
return {
"errno": 400,
"errmsg": "参数有误!",
}
@app.errorhandler(APIError)
def api_error(e):
return {
"errno": 500,
"errmsg": "接口访问有误!",
}
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
context
执行上下文:即语境,语意,在程序中可以理解为在代码执行到某一行时,根据之前代码所做的操作以及下文即将要执行的逻辑,可以决定在当前时刻下可以使用到的变量,或者可以完成的事情。
Flask中上下文对象:相当于一个容器,保存了 Flask 程序运行过程中的一些信息[变量、函数、类与对象等信息]。
Flask中有两种上下文,请求上下文(request context)和应用上下文(application context)。
- application 指的就是当你调用
app = Flask(__name__)创建的这个对象app;
- request 指的是每次
http请求发生时,WSGI server(比如gunicorn/uwsgi)调用Flask.__call__()之后,在Flask对象内部创建的Request对象;
- application 表示用于响应WSGI请求的应用本身,request 表示服务端每次响应客户单的http请求;
- application的生命周期大于request,一个application存活期间,可能发生多次http请求,所以也就会有多个request
请求上下文(request context)
思考:在视图函数中,如何取到当前请求的相关数据?比如:请求地址,请求方式,cookie等等
在 flask 中,可以直接在视图函数中使用 request 这个对象进行获取相关数据,而 request 就是请求上下文提供的对象,保存了当前本次请求的相关数据,请求上下文对象有:request、session
所以每次客户端不同的请求,得到的request和session的对象都是同一个,但是内部的数据都是不一样的。
- request
- 封装了HTTP请求的内容,针对的是http请求。举例:user = request.args.get(‘user’),获取的是get请求的参数。
- session
- 用来记录请求会话中的信息,针对的是用户信息。举例:session[’name’] = user.id,可以记录用户信息。还可以通过session.get(’name’)获取用户信息。
请求上下文提供的变量/属性/方法/函数/类与对象,只能在视图中或者被视图调用的地方使用
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from flask import Flask, request
# 应用实例对象
app = Flask(__name__)
@app.route("/")
def index():
print(request, id(request))
return "ok"
# 此处报错,不能写在视图调用之外的地方
print(request.args) # Working outside of request context. 工作在了请求上下文之外了!!!
if __name__ == '__main__':
# 启动项目的web应用程序
app.run(host="0.0.0.0", port=5000, debug=True)
|
应用上下文(application context)
它的字面意思是 应用上下文,但它不是一直存在的,它只是request context 中操作当前falsk应用对象 app 的代理(人),所谓local proxy。它的作用主要是帮助 request 获取当前的flask应用相关的信息,它是伴 request 而生,随 request 而灭的。
应用上下文对象有:current_app,g
current_app
应用程序上下文,用于存储flask应用实例对象中的变量,可以通过current_app.name打印当前app的名称,也可以在current_app中存储一些变量,例如:
- 应用的启动脚本是哪个文件,启动时指定了哪些参数
- 加载了哪些配置文件,导入了哪些配置
- 连接了哪个数据库
- 有哪些可以调用的工具类、常量
- 当前flask应用在哪个机器上,哪个IP上运行,内存多大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
from flask import Flask,request,session,current_app,g
# 初始化
app = Flask(import_name=__name__)
# 声明和加载配置
class Config():
DEBUG = True
app.config.from_object(Config)
# 编写路由视图
@app.route(rule='/')
def index():
# 应用上下文提供给我们使用的变量,也是只能在视图或者被视图调用的地方进行使用,
# 但是应用上下文的所有数据来源于于app,每个视图中的应用上下文基本一样
print(current_app.config) # 获取当前项目的所有配置信息
print(current_app.url_map) # 获取当前项目的所有路由信息
return "<h1>hello world!</h1>"
if __name__ == '__main__':
# 运行flask
app.run(host="0.0.0.0")
|
g变量
g 作为 flask 程序全局的一个临时变量,充当者中间媒介的作用,我们可以通过它传递一些数据,g 保存的是当前请求的全局变量,不同的请求会有不同的全局变量,通过不同的thread id区别
1
|
g.name='abc' # name是举例,实际要保存什么数据到g变量中,可以根据业务而定,你可以任意的数据进去
|
注意:不同的请求,会有不同的全局变量g
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
from flask import Flask,request,session,current_app,g
# 初始化
app = Flask(import_name=__name__)
# 声明和加载配置
class Config():
DEBUG = True
app.config.from_object(Config)
@app.before_request
def before_request():
g.name = "root"
def get_two_func():
name = g.name
print("g.name=%s" % name)
def get_one_func():
get_two_func()
# 编写路由视图
@app.route(rule='/')
def index():
# 请求上下文提供的变量/属性/方法/函数/类与对象,只能在视图中或者被视图调用的地方使用
# 请求上下文里面信息来源于每次客户端的请求,所以每个视图中请求上下文的信息都不一样
# print(session)
# 应用上下文提供给我们使用的变量,也是只能在视图或者被视图调用的地方进行使用,
# 但是应用上下文的所有数据来源于于app,每个视图中的应用上下文基本一样
print(current_app.config) # 获取当前项目的所有配置信息
print(current_app.url_map) # 获取当前项目的所有路由信息
get_one_func()
return "<h1>hello world!</h1>"
if __name__ == '__main__':
# 运行flask
app.run(host="0.0.0.0")
|
两者区别:
-
请求上下文:保存了客户端和服务器交互的数据,一般来自于客户端。
-
应用上下文:flask 应用程序运行过程中,保存的一些配置信息,比如路由列表,程序名、数据库连接、应用信息等
应用上下文提供的对象,可以直接在请求上下文中使用,但是如果在请求上下文之外调用,则需要使用
with app.app_context()创建一个应用上下文环境才能调用。
终端脚本命令
在flask1.1版本之前版本中都是采用flask-script模块来执行终端脚本命令,flask2.0版本以后不再使用这个模块了,因为存在兼容性问题。
flask1.0的终端命令使用
flask-script模块的作用可以让我们通过终端来控制flask项目的运行,类似于django的manage.py
安装命令:
1
2
|
pip install -U flask==1.1.4
pip install flask-script -i https://pypi.douban.com/simple
|
集成 Flask-Script到flask应用中,创建一个主应用程序,一般我们叫manage.py/run.py/main.py都行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from flask import Flas
app = Flask(__name__)
"""使用flask_script启动项目"""
from flask_script import Manager
manage = Manager(app)
@app.route('/')
def index():
return 'hello world'
if __name__ == "__main__":
manager.run()
|
启动终端脚本的命令:
1
2
3
4
5
6
|
# 端口和域名不写,默认为127.0.0.1:5000
python run.py runserver
# 通过-h设置启动域名,-p设置启动端口 -d
python run.py runserver -h0.0.0.0 -p8888 # 关闭debug模式
python run.py runserver -h0.0.0.0 -p8888 -d # 开启debug模式
|
自定义终端命令
Flask-Script 还可以为当前应用程序添加脚本命令
1
2
3
4
|
1. 引入Command命令基类
2. 创建命令类必须直接或间接继承Command,并在内部实现run方法或者__call__()方法,
同时如果有自定义的其他参数,则必须实现get_options或者option_list
3. 使用flask_script应用对象manage.add_command对命令类进行注册,并设置调用终端别名。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
|
from flask import Flask
from flask_script import Manager, Command, Option
app = Flask(import_name=__name__)
"""使用flask_script启动项目"""
manage = Manager(app)
# 配置类
class Config(object):
DEBUG = True # 开启调试模式
# 加载配置
app.config.from_object(Config)
class PrintCommand(Command):
"""命令的相关描述: 打印数据"""
def get_options(self):
options = (
# Option('简写选项名', '全拼选项名', dest='变量名', type=数据类型, default="默认值"),
Option('-h', '--host', dest='host', type=str, default="127.0.0.1"),
Option('-q', '--quit', dest='quit', type=str, default="退出"),
Option('-p', '--port', dest='port', type=int, default=8000),
)
return options
# 也可以使用option_list来替代get_options
# option_list = (
# Option('-h', '--host', dest='host', default="127.0.0.1"),
# Option('-q', '--quit', dest='quit', default="退出",type=str),
# Option('-p', '--port', dest='port', type=int, default="7000"),
# )
# 没有flask的应用实例对象---->app对象
# def run(self, host, port, quit):
# print("测试命令")
# print(f"self.host={host}")
# print(f"self.port={port}")
# print(f"self.quit={quit}")
def __call__(self, app, *args, **kwargs): # 会自动传递当前flask实例对象进来
print("测试命令")
print(kwargs)
print(f"self.host={kwargs['host']}")
print(f"self.port={kwargs['port']}")
print(f"self.quit={kwargs['quit']}")
# manage.add_command("终端命令名称", 命令类)
manage.add_command("print", PrintCommand)
@app.route("/")
def index():
return "ok"
if __name__ == '__main__':
manage.run()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
(flask) moluo@ubuntu:~/Desktop/flaskdemo$ python 4-manage-自定义终端命令.py print -h=0.0.0.0 -p 8000
测试命令
self.host=0.0.0.0
self.port=8000
self.quit=exit
(flask) moluo@ubuntu:~/Desktop/flaskdemo$ python 4-manage-自定义终端命令.py print -h=0.0.0.0 -p 8000 -q exit
测试命令
self.host=0.0.0.0
self.port=8000
self.quit=exit
(flask) moluo@ubuntu:~/Desktop/flaskdemo$ python 4-manage-自定义终端命令.py print -h=0.0.0.0 -p 8000 -q=exit
测试命令
{'host': '0.0.0.0', 'quit': 'exit', 'port': 8000}
self.host=0.0.0.0
self.port=8000
self.quit=exit
|
flask2.0的终端命令使用
flask0.11.0版本以后,flask内部集成了一个Click模块,这个模块是终端命令模块,可以让我们直接通过Click的装饰器,编写和运行一些终端命令。在flask2.0版本已经不能使用flask-script模块了,所以需要改成使用Click模块来运行和自定义管理终端命令了。
文档地址:https://dormousehole.readthedocs.io/en/latest/cli.html#id10
click文档:https://click.palletsprojects.com/en/8.0.x/
1
|
pip install -U flask==2.0.1
|
安装了flask2.0以后,当前项目所在的python环境就提供了一个全局的flask命令,这个flask命令是Click提供的。
1
2
3
4
5
6
7
8
9
10
|
# 要使用Click提供的终端命令flask,必须先在环境变量中声明当前flask项目的实例对象所在的程序启动文件。
# 例如:manage.py中使用了 app = Flask(__name__),则manage.py就是程序启动文件
# 使用flask终端命令之前,可以配置2个环境变量。
# 指定入口文件,开发中入口文件名一般:app.py/run.py/main.py/index.py/manage.py/start.py
export FLASK_APP=manage.py
# 指定项目所在环境
export FLASK_ENV=development # 开发环境,默认开启DEBUG模式
# export FLASK_ENV=production # 生成环境,默认关闭DEBUG模式
|
默认情况下,flask命令提供的子命令。
1
2
3
4
|
flask routes # 显示当前项目中所有路由信息
flask run # 把flask项目运行在内置的测试服务器下
# flask run --host=0.0.0.0 --port=5055
flask shell # 基于项目的应用上下文提供终端交互界面,可以进行代码测试。
|
Click自定义终端命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import click
from flask import Flask
app = Flask(__name__)
# 自定义终端命令
@app.cli.command("faker") # 假设这个用于生成测试数据
@click.argument("data", default="user") # data表示生成数据的类型[参数argument是命令调用时的必填参数]
@click.option('-n', 'number', default=1, help='Number of create data.') # num表示测试数据的生成数量[选项option是命令调用时的可选参数]
def faker_command(data, number):
"""添加测试用户信息"""
print("添加测试用户信息")
print(f"data={data}")
print(f"number={number}")
@app.route("/")
def index():
return "ok"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
"""
flask faker --help
flask faker -n10 user
flask faker user
"""
|
终端下的运行效果:
1
2
3
4
5
6
7
8
9
10
11
12
|
(flask) moluo@ubuntu:~/Desktop/flaskdemo$ flask faker -n10 user
添加测试用户信息
data=user
number=10
(flask) moluo@ubuntu:~/Desktop/flaskdemo$ flask faker user
添加测试用户信息
data=user
number=1
(flask) moluo@ubuntu:~/Desktop/flaskdemo$ flask faker
添加测试用户信息
data=user
number=1
|
练习:
1. flask2.0的终端下,输入 python manage.py startapp home 则可以在当前目录下创建以下目录和文件
flaskdemo/
└── home
├── views.py
├── models.py
├── urls.py
└── test.py
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
import click, os
from flask import Flask
app = Flask(__name__)
# 自定义终端命令
@app.cli.command("startapp")
@click.option('-n', 'name', help='app name')
def startapp(name):
"""生成模块目录"""
if not name:
print(f"name参数为必填参数!")
return
if os.path.isdir(name):
print(f"当前{name}目录已存在!请先处理完成以后再创建。")
return
os.mkdir(name)
open(f"{name}/views.py", "w")
open(f"{name}/models.py", "w")
open(f"{name}/urls.py", "w")
open(f"{name}/test.py", "w")
print(f"{name}目录模块已创建完成!")
@app.route("/")
def index():
return "ok"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
"""
flask startapp -n home
"""
|
Jinja2模板引擎
Flask内置的模板语言Jinja2,它的设计思想来源于 Django 的模板引擎DTP(Django Template),并扩展了其语法和一系列强大的功能。
- Flask提供的 render_template 函数封装了该模板引擎Jinja2
- render_template 函数的第一个参数是模板的文件名,后面的参数都是键值对,表示模板中变量对应的数据值。
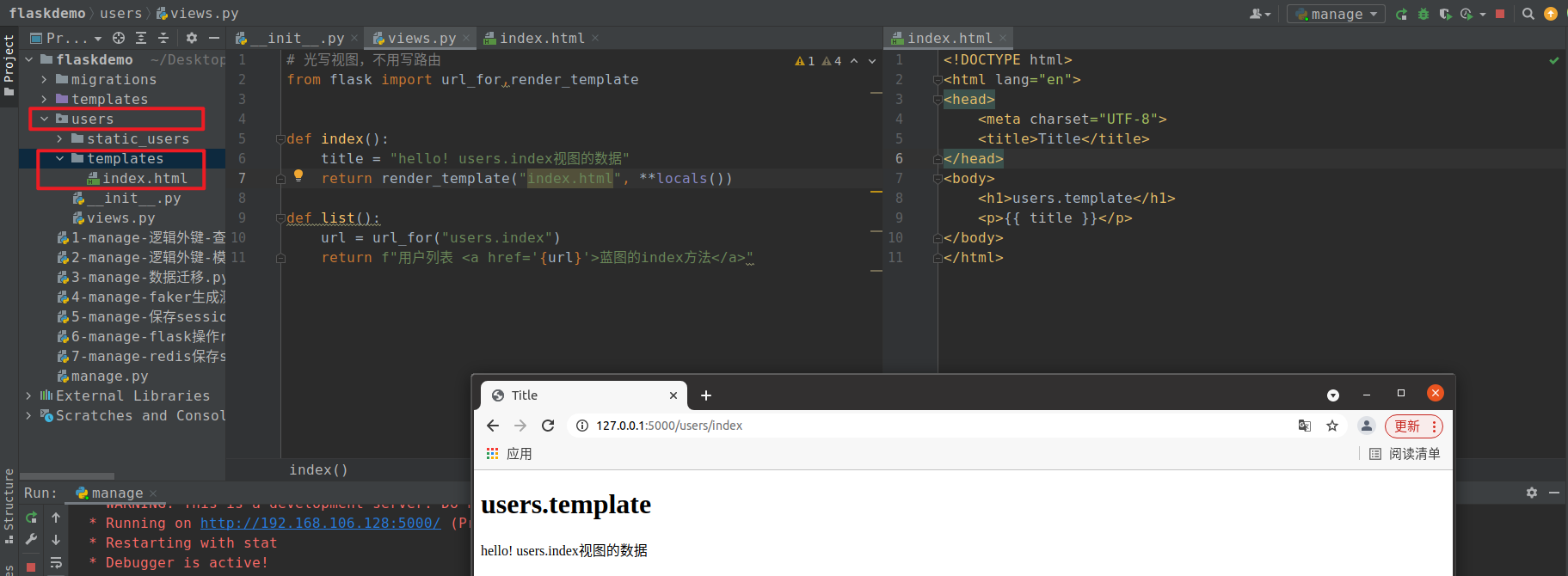
模板基本使用
-
在flask应用对象创建的时候,设置或者保留template_folder参数,创建模板目录
1
|
app = Flask(__name__,template_folder='templates')
|
-
在项目下手动创建 templates 文件夹,用于存放所有的模板文件,并在目录下创建一个模板html文件 index.html
1
2
3
4
5
6
7
8
9
10
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
</head>
<body>
<h1>{{ title }}!!</h1>
</body>
</html>
|
-
在视图函数设置渲染模板并设置模板数据
1
2
3
4
5
6
7
8
9
10
11
12
13
|
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
@app.route("/")
def index():
title = "我的flask"
return render_template("index.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
输出变量
{{ 变量名 }},这种 {{ }} 语法叫做 变量代码块
视图代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
import click
from flask import Flask,render_template
# flask开发小型的项目,直接在当前flask应用配置即可。手动创建模板目录。
# flask开发中大型项目,直接在当前flask的每一个子应用(蓝图)下构建目录。
app = Flask(import_name=__name__, template_folder="templates")
# 配置类
class Config(object):
DEBUG = True # 开启调试模式
# 加载配置
app.config.from_object(Config)
@app.route("/")
def index():
title = "站点标题"
user_list = [
{"id":1, "name": "xiaoming", "age":16},
{"id":2, "name": "xiaoming", "age":16},
{"id":3, "name": "xiaoming", "age":16},
]
return render_template("index.html", **locals())
if __name__ == '__main__':
app.run()
|
模板代码
1
2
3
4
5
6
7
8
9
10
11
12
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{title}}</title>
</head>
<body>
<h1>{{title}}</h1>
<p>{{ user_list.0 }}</p>
<p>{{ user_list.0.name }}</p>
</body>
</html>
|
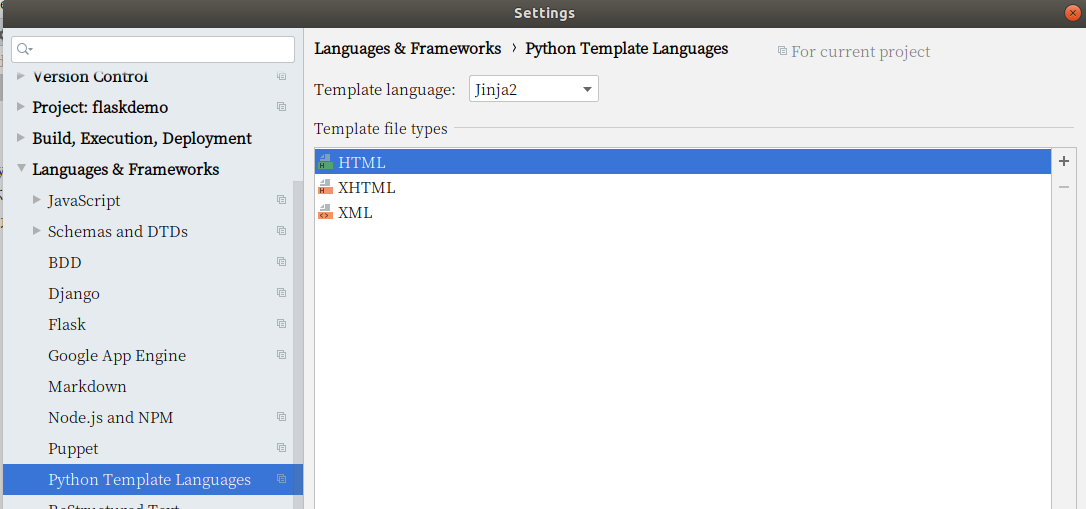
pycharm中设置当前项目的模板语言:
files/settings/languages & frameworks/python template languages。
设置下拉框为jinja2,保存
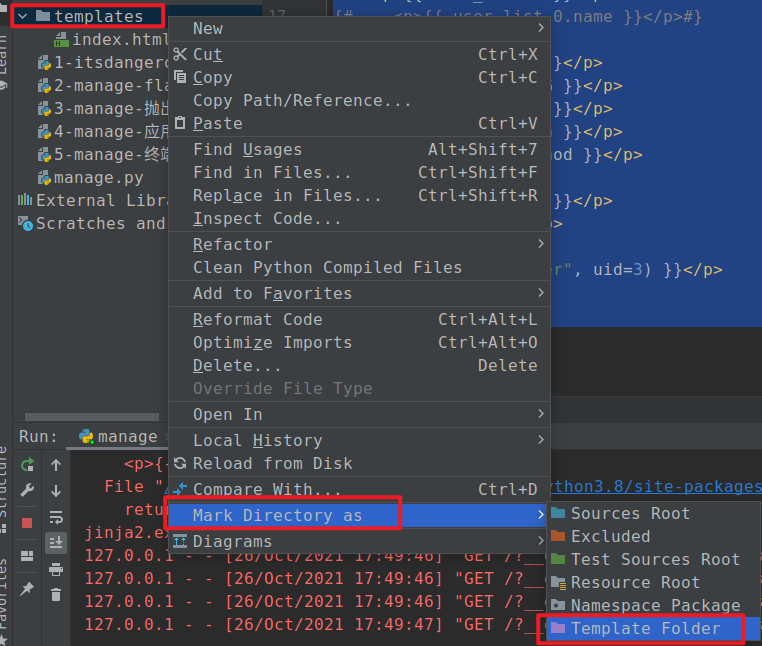
设置指定目录为模板目录,鼠标右键->Mark Directory as …-> Template Folder
Jinja2 模版中的变量代码块可以是任意 Python 类型或者对象,只要它能够被 Python 的 __str__ 方法或者str()转换为一个字符串就可以,比如,可以通过下面的方式显示一个字典或者列表中的某个元素:
视图代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
@app.route("/")
def index():
title = "我的flask"
data_list = ["a", "b", "c"]
data_dict = {
"name": "xiaoming",
"id": 100,
}
user_list = [
{"id":1, "name": "xiaoming", "age":16},
{"id":2, "name": "xiaoming", "age":16},
{"id":3, "name": "xiaoming", "age":16},
]
return render_template("index.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
模板代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
</head>
<body>
<h1>{{ title }}!!</h1>
<p>{{ data_list }}</p>
<p>{{ data_list.1 }}</p>
<p>{{ data_list[-1]}}</p>
<p>{{ data_list | last }}</p>
<p>{{ data_list | first }}</p>
<p>{{ data_dict }}</p>
<p>{{ data_dict.name }}</p>
<p>{{ user_list.0 }}</p>
<p>{{ user_list.0.name }}</p>
</body>
</html>
|
使用 {# #} 进行注释,注释的内容不会在html中被渲染出来
1
2
3
4
5
6
7
8
9
10
|
{# <h1>{{ title }}!!</h1>#}
{# <p>{{ data_list }}</p>#}
{# <p>{{ data_list.1 }}</p>#}
<p>{{ data_list[-1]}}</p>
<p>{{ data_list | last }}</p>
<p>{{ data_list | first }}</p>
<p>{{ data_dict }}</p>
<p>{{ data_dict.name }}</p>
<p>{{ user_list.0 }}</p>
{# <p>{{ user_list.0.name }}</p>#}
|
模板中特有的变量和函数
你可以在自己的模板中访问一些 Flask 默认内置的函数和对象
config
你可以从模板中直接访问Flask当前的config对象:
1
2
|
<p>{{ config.ENV }}</p>
<p>{{ config.DEBUG }}</p>
|
request
就是flask中代表当前请求的request对象:
1
2
3
|
<p>{{ request.url }}</p>
<p>{{ request.path }}</p>
<p>{{ request.method }}</p>
|
session
为Flask的session对象,显示session数据
1
2
|
{{session.new}}
False
|
g变量
在视图函数中设置g变量的 name 属性的值,然后在模板中直接可以取出
url_for()
url_for会根据传入的路由器函数名,返回该路由对应的URL,在模板中始终使用url_for()就可以安全的修改路由绑定的URL,则不比担心模板中渲染出错的链接:
如果我们定义的路由URL是带有参数的,则可以把它们作为关键字参数传入url_for(),Flask会把他们填充进最终生成的URL中:
1
2
3
|
{{ url_for('index', id=1)}}
/index/1 {# /index/<int:id> id被声明成路由参数 #}
/index?id=1 {# /index id被声明成路由参数 #}
|
课堂代码:
主程序 manage.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
from flask import Flask, render_template,g
app = Flask(__name__, template_folder="templates")
@app.route("/")
def index():
g.name = "xiaohei"
title = "我的flask"
data_list = ["a", "b", "c"]
data_dict = {
"name": "xiaoming",
"id": 100,
}
user_list = [
{"id":1, "name": "xiaoming", "age":16},
{"id":2, "name": "xiaoming", "age":16},
{"id":3, "name": "xiaoming", "age":16},
]
return render_template("index.html", **locals())
@app.route("/user/<int:uid>")
def user(uid):
print(uid)
return f"uid={uid}"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
模板 templates/index.html:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
</head>
<body>
{# <h1>{{ title }}!!</h1>#}
{# <p>{{ data_list }}</p>#}
{# <p>{{ data_list.1 }}</p>#}
<p>{{ data_list[-1]}}</p>
<p>{{ data_list | last }}</p>
<p>{{ data_list | first }}</p>
<p>{{ data_dict }}</p>
<p>{{ data_dict.name }}</p>
<p>{{ user_list.0 }}</p>
{# <p>{{ user_list.0.name }}</p>#}
<p>{{ config.ENV }}</p>
<p>{{ config.DEBUG }}</p>
<p>{{ request.url }}</p>
<p>{{ request.path }}</p>
<p>{{ request.method }}</p>
<p>{{ session.new }}</p>
<p>{{ g.name }}</p>
<p>{{ url_for("user", uid=3) }}</p> {# /user/3 #}
</body>
</html>
|
流程控制
主要包含两个:
1
2
|
- if/elif /else / endif
- for / endfor
|
if语句
Jinja2 语法中的if语句跟 Python 中的 if 语句相似,后面的布尔值或返回布尔值的表达式将决定代码中的哪个流程会被执行.
用 {%%} 定义的控制代码块,可以实现一些语言层次的功能,比如循环或者if语句
视图代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
import random
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
@app.route("/")
def index():
data = random.randint(1,100)
return render_template("index6.html", **locals())
@app.route("/user/<int:uid>")
def user(uid):
print(uid)
return f"uid={uid}"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
index.html,模板代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{% if data < 60 %}
<p>本次生成的数字不及格!</p>
{% else %}
<p>本次生成的数字及格了!</p>
{% endif %}
{% if data < 60 %}
<p>本次生成的数字不及格!</p>
{% elif data <80 %}
<p>本次生成的数字一般般,不算高!</p>
{% else %}
<p>本次生成的数字超过80,非常好!</p>
{% endif %}
</body>
</html>
|
循环语句
- 我们可以在 Jinja2 中使用循环来迭代任何列表或者生成器函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
table, td,th{
border: 1px solid red;
border-collapse: collapse;
}
table{
width: 800px;
}
td,th{
padding: 4px;
}
.last{
background: orange;
}
</style>
</head>
<body>
<table>
<tr>
<th>序号</th>
<th>ID</th>
<th>name</th>
<th>age</th>
</tr>
{% for user in user_list %}
{% if loop.last %}
<tr class="last">
{% else %}
<tr>
{% endif %}
{# <th>{{ loop.index }}</th>#}
{# <th>{{ loop.index0 }}</th>#}
{# <th>{{ loop.revindex0 }}</th>#}
<th>{{ loop.revindex }}</th>
<th>{{ user.id }}</th>
<th>{{ user.name }}</th>
<th>{{ user.age }}</th>
</tr>
{% endfor %}
</table>
</body>
</html>
|
- 循环和if语句可以组合使用,以模拟 Python 循环中的 continue 功能,下面这个循环将只会渲染user.id为偶数的那些user:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<table border="1" width="1200">
<tr>
<th width="200">序号[从小到大,从0开始]</th>
<th width="200">序号[从小到大,从1开始]</th>
<th width="200">序号[从大到小,到0结束]</th>
<th width="200">序号[从大到小,到1结束]</th>
<th>ID</th>
<th>name</th>
<th>age</th>
</tr>
{% for user in user_list if user.id%2==0 %}
<tr>
<td>{{ loop.index0 }}</td>
<td>{{ loop.index }}</td>
<td>{{ loop.revindex0 }}</td>
<td>{{ loop.revindex }}</td>
<td>{{ user.id }}</td>
<td>{{ user.name }}</td>
<td>{{ user.age }}</td>
</tr>
{% endfor %}
</table>
|
- 在一个 for 循环块中你可以访问这些特殊的变量:
| 变量 |
描述 |
| loop.index |
当前循环迭代的次数(从 1 开始) |
| loop.index0 |
当前循环迭代的次数(从 0 开始) |
| loop.revindex |
到循环结束需要迭代的次数(从 1 开始) |
| loop.revindex0 |
到循环结束需要迭代的次数(从 0 开始) |
| loop.first |
如果是第一次迭代,为 True 。 |
| loop.last |
如果是最后一次迭代,为 True 。 |
| loop.length |
序列中的项目数。 |
| loop.cycle |
在一串序列间期取值的辅助函数。见下面示例程序。 |
- 在循环内部,你可以使用一个叫做loop的特殊变量来获得关于for循环的一些信息
- 比如:要是我们想知道当前被迭代的元素序号,并模拟Python中的enumerate函数做的事情,则可以使用loop变量的index属性,例如:
1
2
3
4
5
|
<ul>
{% for item in data_list %}
<li>{{ loop.index0 }},item={{ item }}</li>
{% endfor %}
</ul>
|
1
2
3
|
0,item=a
1,item=b
2,item=c
|
- loop.cycle函数会在每次循环的时候,返回其参数中的下一个元素,可以拿上面的例子来说明:
1
2
3
4
5
|
<ul>
{% for item in data_list %}
<li>{{ loop.cycle("男","女")}},item={{ item }}</li>
{% endfor %}
</ul>
|
1
2
3
|
男,item=a
女,item=b
男,item=c
|
课堂代码
视图代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
import click
from flask import Flask,render_template,g
# flask开发小型的项目,直接在当前flask应用配置即可。手动创建模板目录。
# flask开发中大型项目,直接在当前flask的每一个子应用(蓝图)下构建目录。
app = Flask(import_name=__name__, template_folder="templates")
# 加载配置
app.config.from_object(Config)
@app.route("/")
def index():
title = "站点标题"
data_list = ["a","b","c"]
data_dict = {
"name": "xiaoming",
"id": 100,
}
user_list = [
{"id":2, "name": "xiaoming", "age":15},
{"id":3, "name": "xiaoming", "age":16},
{"id":4, "name": "xiaoming", "age":17},
]
g.name = "来自视图"
return render_template("index.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
index.html,模板代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{title}}</title>
</head>
<body>
{# <h1>{{title}}</h1>
<p>{{ data_list }}</p>
<p>{{ data_list.1 }}</p>
<p>{{ data_list | first }}</p>
<p>{{ data_list | last }}</p>
<p>{{ data_dict }}</p>
<p>{{ data_dict.name }}</p>
#}{# <p>{{ data_list.-1 }}</p>#}{#
<p>{{ user_list.0 }}</p>
<p>{{ user_list.0.name }}</p>
#}
{# <p>{{ data_list[0] }}</p>#}
{# <p>{{ data_list[-1] }}</p>#}
{# <p>{{ data_dict['name'] }}</p>#}
{# <p>{{ config }}</p>#}
{# <p>{{ config.ENV }}</p>#}
{# <p>{{ request }}</p>#}
{# <p>获取地址栏参数:id={{ request.args.id }}</p>#}
{# <p>{{ session }}</p>#}
{# <p>{{ session.new }}</p>#}
{# <p>{{ g.name }}</p>#}
{# <p>{{ url_for("index",id=1) }}</p>#}
{% if "a" in data_list %}
<p>{{ data_list }}包含a字符</p>
{% endif %}
{% if "A" in data_list %}
<p>{{ data_list }}包含A字符</p>
{% else %}
<p>{{ data_list }}不包含A字符</p>
{% endif %}
<table border="1" width="1200">
<tr>
<th width="200">序号[从小到大,从0开始]</th>
<th width="200">序号[从小到大,从1开始]</th>
<th width="200">序号[从大到小,到0结束]</th>
<th width="200">序号[从大到小,到1结束]</th>
<th>ID</th>
<th>name</th>
<th>age</th>
</tr>
{% for user in user_list if user.id%2==0 %}
<tr>
<td>{{ loop.index0 }}</td>
<td>{{ loop.index }}</td>
<td>{{ loop.revindex0 }}</td>
<td>{{ loop.revindex }}</td>
<td>{{ user.id }}</td>
<td>{{ user.name }}</td>
<td>{{ user.age }}</td>
</tr>
{% endfor %}
</table>
<ul>
{% for item in data_list %}
<li>{{ loop.index0 }},item={{ item }}</li>
{% endfor %}
</ul>
<ul>
{% for item in data_list %}
<li>{{ loop.cycle("男","女")}},item={{ item }}</li>
{% endfor %}
</ul>
</body>
</html>
|
过滤器
flask中也有过滤器,并且也可以被用在 if 语句或者for语句中:
视图代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import random
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
@app.route("/")
def index():
book_list = [
{"id":1, "price": 78.50, "title":"javascript入门", "cover": "<img src='/static/images/course.png'>"},
{"id":2, "price": 78.5, "title":"python入门", "cover": "<img src='/static/images/course.png'>"},
{"id":3, "price": 78.6666, "title":"django web项目实战", "cover": "<img src='/static/images/course.png'>"}
]
return render_template("index8.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
index8.html,模板代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
table, td,th{
border: 1px solid red;
border-collapse: collapse;
}
table{
width: 800px;
}
td,th{
padding: 4px;
}
img{
width: 100px;
}
</style>
</head>
<body>
<table>
<tr>
<th>ID</th>
<th>title</th>
<th>price</th>
<th>cover</th>
</tr>
{% for book in book_list %}
<tr>
<th>{{ book.id }}</th>
<th>{{ book.title | title }}</th>
<th>{{ book.price }}</th>
<th>{{ book.cover | safe }}</th>
</tr>
{% endfor %}
</table>
</body>
</html>
|
flask中, 过滤器的本质就是函数。有时候我们不仅仅只是需要输出变量的值,我们还需要修改变量的显示,甚至格式化、运算等等,而在模板中是不能直接调用 Python 的方法,那么这就用到了过滤器。
使用方式:
- 过滤器的使用方式为:变量名 | 过滤器 | 。。。。。
1
|
{{variable | filter_name(args1,args2,....)}}
|
- 如:
title过滤器的作用:把变量的值的首字母转换为大写,其他字母转换为小写
在 jinja2 中,过滤器是可以支持链式调用的,示例如下:
1
|
{{ "hello world" | reverse | upper }}
|
常见的内建过滤器
字符串操作
1
|
{{ '<h1>hello</h1>' | safe }}
|
1
|
<p>{{ 'HELLO' | lower }}</p>
|
1
|
<p>{{ 'hello' | upper }}</p>
|
1
|
<p>{{ 'olleh' | reverse }}</p>
|
1
|
<p>{{ '%s is %d' | format('name',17) }}</p>
|
1
2
|
<p>{{ '<script>alert("hello")</script>' | striptags }}</p>
<p>{{ "如果x<y,z>x,那么x和z之间是否相等?" | striptags }}</p>
|
1
|
<p>{{ 'hello every one' | truncate(9)}}</p>
|
列表操作
1
|
<p>{{ [1,2,3,4,5,6] | first }}</p>
|
1
|
<p>{{ [1,2,3,4,5,6] | last }}</p>
|
1
|
<p>{{ [1,2,3,4,5,6] | length }}</p>
|
1
|
<p>{{ [1,2,3,4,5,6] | sum }}</p>
|
<p>{{ [6,2,3,1,5,4] | sort }}</p>
语句块过滤
{% filter upper %}
<p>abc</p>
<p>{{ ["a","c"] }}</p>
<p>{{ ["a","c"] }}</p>
<p>{{ ["a","c"] }}</p>
<p>{{ ["a","c"] }}</p>
{% endfilter %}
自定义过滤器
过滤器的本质是函数。当模板内置的过滤器不能满足需求,可以自定义过滤器。自定义过滤器有两种实现方式:
- 一种是通过Flask应用对象的 app.add_template_filter 方法
- 通过装饰器来实现自定义过滤器
重要:自定义的过滤器名称如果和内置的过滤器重名,会覆盖内置的过滤器。
需求:编写一个过滤器,保留2位小数
方式一
通过调用应用程序实例的 add_template_filter 方法实现自定义过滤器。该方法第一个参数是函数名,第二个参数是自定义的过滤器名称:
1
2
3
4
5
6
|
# 自定义过滤器
def do_fixed(data):
return f"{data:.2f}"
# 注册过滤器到当前应用实例对象
app.add_template_filter(do_fixed, "fixed")
|
方式二
用装饰器来实现自定义过滤器。装饰器传入的参数是自定义的过滤器名称。
1
2
3
4
|
# 自定义过滤器,通过装饰器注册到app应用实例对象
@app.template_filter("fixed")
def do_fixed(data):
return f"{data:.2f}"
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
# 自定义过滤器,通过装饰器注册到app应用实例对象
@app.template_filter("fixed")
def do_fixed(data):
return f"{data:.2f}"
@app.route("/")
def index():
title = "网页标题"
book_list = [
{"id":1, "price": 78.50, "title":"javascript入门", "cover": "<img src='/static/images/course.png'>"},
{"id":2, "price": 78.5, "title":"python入门", "cover": "<img src='/static/images/course.png'>"},
{"id":3, "price": 78.6666, "title":"django web项目实战", "cover": "<img src='/static/images/course.png'>"}
]
return render_template("index9.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
table, td,th{
border: 1px solid red;
border-collapse: collapse;
}
table{
width: 800px;
}
td,th{
padding: 4px;
}
img{
width: 100px;
}
</style>
</head>
<body>
<table>
<tr>
<th>ID</th>
<th>title</th>
<th>price</th>
<th>cover</th>
</tr>
{% for book in book_list %}
<tr>
<th>{{ book.id }}</th>
<th>{{ book.title | title }}</th>
<th>{{ book.price | fixed }}</th>
<th>{{ book.cover | safe }}</th>
</tr>
{% endfor %}
</table>
</body>
</html>
|
案例:给手机进行部分屏蔽
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
@app.template_filter("mobile")
def do_mobile(data, content):
return f"{data[:3]}{content}{data[-4:]}"
@app.route("/")
def index():
title = "网页标题"
user_list = [
{"id":1,"name":"张三","mobile":"13112345678"},
{"id":2,"name":"张三","mobile":"13112345678"},
{"id":3,"name":"张三","mobile":"13112345678"},
{"id":4,"name":"张三","mobile":"13112345678"},
]
return render_template("index12.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
index2.html,模板代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
table, td,th{
border: 1px solid red;
border-collapse: collapse;
}
table{
width: 800px;
}
td,th{
padding: 4px;
}
img{
width: 100px;
}
</style>
</head>
<body>
<table>
<tr>
<th>ID</th>
<th>name</th>
<th>mobile</th>
</tr>
{% for user in user_list %}
<tr>
<th>{{ user.id }}</th>
<th>{{ user.name }}</th>
<th>{{ user.mobile | mobile("****") }}</th>
</tr>
{% endfor %}
</table>
</body>
</html>
|
效果:

模板继承
在模板中,可能会遇到以下情况:
- 多个模板具有完全相同的顶部和底部内容
- 多个模板中具有相同的模板代码内容,但是内容中部分值不一样
- 多个模板中具有完全相同的 html 代码块内容
像遇到这种情况,可以使用 JinJa2 模板中的 继承 来进行实现
模板继承是为了重用模板中的公共内容。一般Web开发中,继承主要使用在网站的顶部菜单、底部。这些内容可以定义在父模板中,子模板直接继承,而不需要重复书写。
1
2
3
4
5
6
|
{% block 区块名称 %} {% endblock 区块名称 %}
{% block 区块名称 %} {% endblock %}
例如:顶部菜单
{% block menu %}{% endblock %}
|
- block相当于在父模板中挖个坑,当子模板继承父模板时,可以进行对应指定同名区块进行代码填充。
- 子模板使用 extends 标签声明继承自哪个父模板
- 父模板中定义的区块在子模板中被重新定义,在子模板中调用父模板的内容可以使用super()调用父模板声明的区块内容。
manage.py,视图代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
from flask import Flask, render_template
app = Flask(__name__, template_folder="templates")
@app.route("/")
def index():
title = "首页内容和标题"
return render_template("index.html", **locals())
@app.route("/list")
def list_page():
title = "列表页内容和标题"
return render_template("list.html", **locals())
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
父模板代码:
base.html
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
</head>
<body>
<h1>头部内容-菜单-登录窗口</h1>
{% block main %}
<div>公共页面中间部分内容 - {{ title }}</div>
{% endblock main %}
<h1>脚部内容-版权信息,网点地图</h1>
</body>
</html>
|
子模板代码:
Index.html,代码:
1
2
3
4
5
6
|
{% extends "base.html" %}
{% block main %}
<div>首页中间部分内容 - {{ title }}</div>
{{super()}}
{% endblock main %}
|
list.html,代码:
1
2
3
4
5
|
{% extends "base.html" %}
{% block main %}
<div>列表页中间部分内容 - {{ title }}</div>
{% endblock %}
|
模板继承使用时注意点:
-
不支持多继承
-
为了便于阅读,在子模板中使用extends时,尽量写在模板的第一行。
-
不能在一个模板文件中定义多个相同名字的block标签,否则会覆盖。
-
当在页面中使用多个block标签时,建议给结束标签起个名字,当多个block嵌套时,阅读性更好。
CSRF 攻击防范
CSRF : 跨域请求伪造攻击。
在 Flask 中, Flask-wtf 扩展有一套完善的 csrf 防护体系,对于我们开发者来说,使用起来非常简单
- 设置应用程序的 secret_key,用于加密生成的 csrf_token 的值
1
2
3
4
5
6
7
8
9
10
|
# 1. session加密的时候已经配置过了.如果没有在配置项中设置,则如下:
app.secret_key = "#此处可以写随机字符串#"
# 2. 也可以写在配置类中。
class Config(object):
DEBUG = True
SECRET_KEY = "dsad32DASSLD*13%^32"
"""加载配置"""
app.config.from_object(Config)
|
- 导入 flask_wtf 中的 CSRFProtect类,进行初始化,并在初始化的时候关联 app
1
2
3
4
5
6
7
8
9
10
|
# 方式1:
from flask_wtf import CSRFProtect
csrf = CSRFProtect() # 这块代码可能在文件中。
app = Flask(import_name=__name__, template_folder="templates")
csrf.init_app(app) # 避免出现引用导包,所以提供了init_app的用法
# 方式2:
# from flask_wtf import CSRFProtect
# app = Flask(import_name=__name__, template_folder="templates")
# CSRFProtect(app)
|
- 在表单中使用 CSRF 令牌:
1
2
3
|
<form action="/login" method="post">
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}" />
</form>
|
视图代码;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
from flask import Flask, render_template
from flask_wtf import CSRFProtect
# 实例化csrf
csrf = CSRFProtect()
app = Flask(__name__, template_folder="templates")
# csrf = CSRFProtect(app=app) # 也可以实例化的同时,直接初始化加载项目配置信息
# 初始化csrf
csrf.init_app(app)
# csrf的使用务必设置秘钥
app.config["SECRET_KEY"] = "my secret key"
@app.route("/login")
def login():
return render_template("login.html", **locals())
@app.route("/token", methods=["POST"])
def token():
return "ok"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
login.html,模板代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
<form action="/token" method="post">
<input type="hidden" name="csrf_token" value="{{ csrf_token() }}" />
账户:<input type="text" name="username"> <br><br>
口令:<input type="password" name="password"> <br><br>
<button>登录</button>
</form>
</body>
</html>
|
数据库操作
ORM
ORM 全拼Object-Relation Mapping,中文意为 对象-关系映射。主要实现模型对象到关系数据库数据的映射
优点:
- 只需要面向对象编程, 不需要面向数据库编写代码.
- 对数据库的操作都转化成对类/对象的属性和方法的操作. 字段—>属性, 关键字-> 操作方法
- 不用编写各种数据库的
sql语句.
- 实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异
- 不再需要关注当前项目使用的是哪种数据库。
- 通过简单的配置就可以轻松更换数据库, 而不需要修改代码.
缺点:
- 相比较直接使用SQL语句操作数据库,ORM需要把操作转换成SQL语句,所以有性能损失.
- 根据对象的操作转换成SQL语句,根据查询的结果转化成对象, 在映射过程中有性能损失.
- 增加了学习成本,不同的ORM提供的操作不一样
Flask-SQLAlchemy
flask默认提供模型操作,但是并没有提供ORM,所以一般开发的时候我们会采用flask-SQLAlchemy模块来实现ORM操作。
SQLAlchemy是一个关系型数据库框架,它提供了高层的 ORM 和底层的原生数据库的操作。
我们使用sqlalchemy 不需要调用sqlalchemy 本身这个模块,而是采用flask-sqlalchemy ,这是一个简化了 SQLAlchemy 操作的flask扩展模块。
SQLAlchemy:https://www.sqlalchemy.org/
flask-SQLAlchemy:https://flask-sqlalchemy.palletsprojects.com/en/2.x/quickstart/
安装 flask-sqlalchemy【清华源】
1
|
pip install flask-sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
|
如果sqlalchemy连接的是 mysql /MariaDB数据库,需要安装 mysqldb 或pymysql驱动
1
|
conda install flask-mysqldb -c conda-forge
|
安装flask-mysqldb时,注意
使用pip install 安装 flask-mysqldb的时候,python底层依赖于一个底层的模块 mysqlclient 模块
如果没有这个模块,则会报错如下:
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-install-21hysnd4/mysqlclient/
解决方案:
1
2
3
4
5
6
7
8
9
10
11
|
sudo apt-get install -y libmysqlclient-dev python3-dev
# 运行上面的安装命令如果再次报错如下:
# dpkg 被中断,您必须手工运行 ‘sudo dpkg --configure -a’ 解决此问题。
# 则根据提示执行命令以下命令,再次安装mysqlclient
# sudo dpkg --configure -a
# apt-get install libmysqlclient-dev python3-dev
解决了mysqlclient问题以后,重新安装 flask-mysqldb即可。
pip install flask-mysqldb -i https://pypi.tuna.tsinghua.edu.cn/simple
|
数据库连接设置
- 在 Flask-SQLAlchemy 中,数据库的链接配置信息使用URL指定,而且程序使用的数据库必须保存到Flask的 SQLALCHEMY_DATABASE_URI 配置项中
manage.py,代码:
1
2
3
4
5
6
|
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 如果不使用mysqldb改用pymysql,则需要在连接时指定pymysql
# app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
|
其他设置项:
1
2
3
4
|
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = True
#查询时会显示原始SQL语句
SQLALCHEMY_ECHO = True
|
- 配置完成需要去 MySQL 中创建项目所使用的数据库
1
2
|
mysql -uroot -p123
create database flaskdemo charset=utf8mb4;
|
常用的SQLAlchemy字段类型
| 模型字段类型名 |
python中数据类型 |
说明 |
| Integer |
int |
普通整数,一般是32位 |
| SmallInteger |
int |
取值范围小的整数,一般是16位 |
| BigInteger |
int或long |
不限制精度的整数 |
| Float |
float |
浮点数 |
| Numeric |
decimal.Decimal |
普通数值,一般是32位 |
| String |
str |
变长字符串 |
| Text |
str |
变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode |
unicode |
变长Unicode字符串 |
| UnicodeText |
unicode |
变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean |
bool |
布尔值 |
| DateTime |
datetime.datetime |
日期和时间 |
| Date |
datetime.date |
日期 |
| Time |
datetime.time |
时间 |
| LargeBinary |
bytes |
二进制文件内容 |
| Enum |
enum.Enum |
枚举类型,相当于django的choices,但是功能没有choices那么强大 |
常用的SQLAlchemy列约束选项
| 选项名 |
说明 |
| primary_key |
如果为True,代表当前数据表的主键 |
| unique |
如果为True,为这列创建唯一 索引,代表这列不允许出现重复的值 |
| index |
如果为True,为这列创建普通索引,提高查询效率 |
| nullable |
如果为True,允许有空值,如果为False,不允许有空值 |
| default |
为这列定义默认值 |
数据库基本操作
- 在SQLAlchemy中,添加、修改、删除操作,均由数据库会话(sessionSM)管理。
- 会话用 db.session 表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用 db.commit() 方法提交会话。
- 在SQLAlchemy 中,查询操作是通过 query 对象操作数据。
- 最基本的查询是返回表中所有数据,也可以通过filter过滤器进行更精确的数据库查询。
模型类定义
我们后面会把模型创建到单独的文件中,但是现在我们先把模型类写在main.py文件中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
class Config(object):
DEBUG = True
# 数据库链接配置 = 数据库名称://登录账号:登录密码@数据库主机IP:数据库访问端口/数据库名称?charset=编码类型
SQLALCHEMY_DATABASE_URI = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = False
# ORM运行时会显示ORM生成的原始SQL语句[调试]
SQLALCHEMY_ECHO = True
app.config.from_object(Config)
"""模型类定义"""
db = SQLAlchemy(app=app)
# 等同于
# db = SQLAlchemy()
# db.init_app(app) # 加载配置并完成初始化过程
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
"""
# 企业中,往往大部分的公司会出现以下2种不同的数据库开发情况。
# 1. 企业中有DBA,DBA会提前创建数据库和项目中具体业务的数据表。
也就是说我们不需要自己手动建库建表,只需要根据数据库表结构,使用python声明对应的模型与之匹配,就可以操作数据库了。
# 2. 企业没有DBA,比较坑爹:
# 2.1 开发人员,自己手撸SQL语句,手动建库建表。
# 2.2 开发人员,编写模型,使用数据迁移,手动建库和数据迁移建表。
# 原生SQL语句
create table db_student(
id int primary key auto_increment comment "主键",
name varchar(15) comment "姓名",
age smallint comment "年龄",
sex tinyint default 1 comment "性别",
email varchar(128) comment "邮箱地址",
money NUMERIC(10,2) default 0.0 comment "钱包",
key (name),
unique key (email)
);
# 字段根据SQL语句来声明
"""
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), index=True, comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), unique=True, comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
def __repr__(self): # 相当于django的__str__
return f"{self.name}<{self.__class__.__name__}>"
# 所有的模型必须直接或间接继承于db.Model
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
"""
# 原生SQL语句
create table db_course (
id int primary key auto_increment comment "主键",
name varchar(64) comment "课程",
price NUMERIC(7,2) comment "价格",
unique (name)
);
# 字段根据SQL语句来声明
"""
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2), comment="价格")
# repr()方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
class Teacher(db.Model):
"""老师数据模型"""
__tablename__ = "db_teacher"
"""
# 原生SQL语句
create table db_teacher (
id int primary key auto_increment comment "主键",
name varchar(64) comment "姓名",
option enum("讲师", "助教", "班主任") comment "职位",
unique (`name`)
);
# 字段根据SQL语句来声明
"""
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="姓名")
option = db.Column(db.Enum("讲师", "助教", "班主任"), default="讲师")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
@app.route("/")
def index():
return "ok"
if __name__ == '__main__':
app.run()
|
数据表操作
创建和删除表
创建表
1
2
3
4
5
6
|
with app.app_context():
# create_all()方法执行的时候,需要放在模型的后面
# 检测数据库中是否存在和模型匹配的数据表。
# 如果没有,则根据模型转换的建表语句进行建表。
# 如果找到,则不会进行额外处理
db.create_all()
|
删除表
1
2
|
with app.app_context():
db.drop_all() # 慎用,很给力的!!这表示删除数据库中所有模型对应的表。
|
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
|
from datetime import datetime
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 如果不使用mysqldb改用pymysql,则需要在连接时指定pymysql
# app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
"""模型声明"""
class Student(db.Model):
"""学生信息"""
# 表名
__tablename__ = "db_student"
"""
# 企业中,往往大部分的公司会出现以下2种不同的数据库开发情况。
# 1. 企业中有DBA,DBA会提前创建数据库和项目中具体业务的数据表。
也就是说我们不需要自己手动建库建表,只需要根据数据库表结构,使用python声明对应的模型与之匹配,就可以操作数据库了。
# 2. 企业没有DBA,比较坑爹:
# 2.1 开发人员,自己手撸SQL语句,手动建库建表。
# 2.2 开发人员,编写模型,使用数据迁移,手动建库和数据迁移建表。
# 原生SQL语句
create table db_student(
id int primary key auto_increment comment "主键",
name varchar(15) comment "姓名",
age smallint comment "年龄",
sex tinyint default 1 comment "性别",
email varchar(128) comment "邮箱地址",
money NUMERIC(10,2) default 0.0 comment "钱包",
key (name),
unique key (email)
);
# 字段根据SQL语句来声明
"""
# 字段列表
# 属性名 = db.Column(字段类型, 字段列约束选项)
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(255), index=True, comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(255), unique=True, comment="邮箱地址")
money = db.Column(db.Numeric(10, 2), default=0.0, comment="钱包")
def __repr__(self): # 相当于django的__str__
return f"{self.name}<{self.__class__.__name__}>"
# 所有的模型必须直接或间接继承于db.Model
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
"""
# 原生SQL语句
create table db_course (
id int primary key auto_increment comment "主键",
name varchar(64) comment "课程",
price NUMERIC(7,2) comment "价格",
unique (name)
);
# 字段根据SQL语句来声明
"""
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2), comment="价格")
# pubdate = db.Column(db.DateTime(), default=datetime.now, comment="发布时间")
# repr()方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
class Teacher(db.Model):
"""老师数据模型"""
__tablename__ = "db_teacher"
"""
# 原生SQL语句
create table db_teacher (
id int primary key auto_increment comment "主键",
name varchar(64) comment "姓名",
option enum("讲师", "助教", "班主任") comment "职位",
unique (`name`)
);
# 字段根据SQL语句来声明
"""
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="姓名")
option = db.Column(db.Enum("讲师", "助教", "班主任"), default="讲师")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
@app.route("/")
def index():
student = Student(
name="小明",
age=16,
sex=True,
email="xiaoming@qq.com",
)
db.session.add(student)
db.session.commit()
return "ok"
if __name__ == '__main__':
with app.app_context():
# 自动根据项目中所有的模型与数据库中的数据表进行对比,没有创建的表,会自动生成建表语句,自动创建
# 如果已经存在的数据表,则不会创建。
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
数据操作
添加一条数据
1
2
3
4
5
6
7
8
9
|
# 添加一条数据
student = Student(name="小明", age=17, email="xiaoming@qq.com", money=100) # 实例化模型对象
db.session.add(student) # 把模型对象添加数据库session会话对象中。db.session是SQLAlchemy中内置的会话管理对象sessionSM的成员
db.session.commit() # 提交会话
#再次插入一条数据
student2 = Student(name='小红', sex=False, age=13, email="16565666@qq.com", money=600)
db.session.add(student2)
db.session.commit()
|
一次插入多条数据
1
2
3
4
5
6
7
8
9
10
11
12
|
st1 = Student(name='wang',email='wang@163.com',age=22)
st2 = Student(name='zhang',email='zhang@189.com',age=22)
st3 = Student(name='chen',email='chen@126.com',age=22)
st4 = Student(name='zhou',email='zhou@163.com',age=22)
st5 = Student(name='tang',email='tang@163.com',age=22)
st6 = Student(name='wu',email='wu@gmail.com',age=22)
st7 = Student(name='qian',email='qian@gmail.com',age=22)
st8 = Student(name='liu',email='liu@163.com',age=22)
st9 = Student(name='li',email='li@163.com',age=22)
st10 = Student(name='sun',email='sun@163.com',age=22)
db.session.add_all([st1,st2,st3,st4,st5,st6,st7,st8,st9,st10])
db.session.commit()
|
删除数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
# 方法1[先查询后删除,2条语句]
# 先查询出来
student = Student.query.first()
print(student)
# 再进行删除
db.session.delete(student)
db.session.commit()
# 方法2【一条语句执行,性能更好更高效,在数据改动时添加条件才进行操作,这种用法就是乐观锁】
# 乐观锁和悲观锁
Student.query.filter(Student.id > 5).delete()
db.session.commit()
"""
乐观锁和悲观锁,并非真正的数据库锁,是数据库在应对并发操作时,防止出现资源抢夺的,基于不同人生观所实现2种解决方案。
举例:双11活动,商城里面商品id=5商品,库存=10了,现在我们要基于乐观锁和悲观锁来解决下单过程中,出现的资源抢夺现象,避免出现超卖。
乐观锁:
---> 先查看库存 num=10
---> 进行下单操作,买6件
---> 付款
---> 扣除库存 update goods set num=num-6 where num=10 and id=5
---> 如果执行成功,则表示没有人抢,购买成功
如果执行事变,则表示已经有人先抢购
悲观锁:
---> 先给id=5的数据,加锁
select * from goods where id=5 for update
---> 进行下单操作,买6件
---> 付款
---> 扣除库存 update goods set num=num-6 where id=5
---> 执行成功解锁
"""
|
更新数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 先查询数据,然后进行更新,2条语句
stu = Student.query.first()
stu.name = 'dong'
db.session.commit()
# 直接根据条件更新,一条语句[乐观锁]
Student.query.filter(Student.name == 'chen').update({'money': 1998})
db.session.commit()
# 字段引用[利用当前一条数据的字典值进行辅助操作,实现类似django里面F函数的效果]
# 每次自增100
Student.query.filter(Student.name == "li").update({"money": Student.money + 100})
db.session.commit()
# 在原有money的基础上按age补贴1000*age
Student.query.filter(Student.name == "zhang").update({"money":Student.money+1000 * Student.age})
db.session.commit()
|
基本查询
SQLAlchemy常用的查询过滤器
| 过滤器 |
说明 |
| filter() |
把过滤器添加到原查询上,返回一个新查询 |
| filter_by() |
把等值过滤器添加到原查询上,返回一个新查询 |
| limit() |
使用指定的值限定原查询返回的结果数量 |
| offset() |
设置结果范围的开始位置,偏移原查询返回的结果,返回一个新查询 |
| order_by() |
根据指定条件对原查询结果进行排序,返回一个新查询 |
| group_by() |
根据指定条件对原查询结果进行分组,返回一个新查询 |
SQLAlchemy常用的查询结果方法
| 方法 |
说明 |
| all() |
以列表形式返回查询的所有结果 |
| first() |
返回查询的第一个结果,模型对象,如果未查到,返回None |
| first_or_404() |
返回查询的第一个结果,模型对象,如果未查到,通过abort 返回404异常 |
| get() |
返回指定主键对应的模型对象,如不存在,返回None |
| get_or_404() |
返回指定主键对应的行,如不存在,abort 返回404 |
| count() |
返回查询结果的数量 |
| paginate() |
返回一个Paginate分页器对象,它包含指定范围内的结果 |
| having |
返回结果中符合条件的数据,必须跟在group by后面,其他地方无法使用。 |
get():参数为主键,表示根据主键查询数据,如果主键不存在返回None
1
2
3
4
5
6
7
8
9
10
11
|
模型类.query.get()
"""根据主键来获取一条数据"""
# print(type(Student.query))
# get的参数只能是主键的值,多个主键组合的元组、和条件组成的字典
# my_object = query.get((5, 10)) # sqlalchemy/orm/query.py 中声明可以,但是需要基于联合主键的情况下使用。
# student = Student.query.get({"id":3,"sex":1}) # # sqlalchemy/orm/query.py 中声明可以,但是需要基于联合主键的情况下使用。
student = Student.query.get({"id":3})
# student = Student.query.get(6)
print(student)
|
课堂代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# 前面代码省略
@app.route("/query")
def query():
query1 = Student.query # 简写操作
query2 = db.session.query(Student)
print(type(query1), query1)
print(type(query2), query2)
return "ok"
@app.route("/get")
def get():
"""get根据主键获取数据"""
# student1 = Student.query.get({"id":10})
student1 = Student.query.get(30)
# student2 = db.session.query(Student).get({"id":10})
student2 = db.session.query(Student).get(30)
# 结果是模型对象
print(type(student1), student1)
print(type(student2), student2)
# 查询不到结果,则返回值为None
if student1:
print(student1.name, student1.age)
if student2:
print(student2.name, student2.age)
return "ok"
@app.route("/")
def all():
return "ok"
if __name__ == '__main__':
with app.app_context():
# 自动根据项目中所有的模型与数据库中的数据表进行对比,没有创建的表,会自动生成建表语句,自动创建
# 如果已经存在的数据表,则不会创建。
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
all()返回查询到的所有对象
1
2
3
4
5
6
7
8
9
10
11
12
|
模型类.query.all()
"""获取多个数据"""
student = Student.query.all()
print(student) # [dong<Student>, 小红<Student>, wang<Student>, chen<Student>, zhou<Student>, tang<Student>, wu<Student>, qian<Student>, liu<Student>, li<Student>, sun<Student>]
student = Student.query.filter(Student.id<5).all() # 没有结果返回空列表[]
print(student) # [dong<Student>, 小红<Student>, wang<Student>]
# all()的返回值是一个python列表,可以直接使用切片,与django的QuerySet完全不是一回事。
student = Student.query.filter(Student.id < 5).all()[:-1] # 没有结果返回空列表[]
print(student) # [dong<Student>, 小红<Student>]
|
count 返回结果的数量
1
2
3
|
# 返回结果的数量
ret = Student.query.filter(Student.id<5).count()
print(ret)
|
first()返回查询到的第一个对象【first获取一条数据,all获取多条数据】
1
2
3
4
5
6
7
8
|
模型类.query.first()
"""获取第一个数据"""
student = Student.query.first()
print(student)
student = Student.query.filter(Student.id==5).first() # 没有结果返回None
print(student)
|
filter条件查询,支持各种运算符和查询方法或者模糊查询方法。
返回名字结尾字符为g的所有数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
# 模糊查询
# 使用163邮箱的所有用户
student_list = Student.query.filter(Student.email.endswith("@163.com")).all()
print(student_list)
# 姓名以"zh"开头的
student_list = Student.query.filter(Student.name.startswith("zh")).all()
print(student_list)
# 名字中带有"a"字母的数据
student_list = Student.query.filter(Student.name.contains("a")).all()
print(student_list)
"""单条件比较"""
# 则需要指定条件格式为: filter(模型.字段 比较运算符 值)。
# 运算符可以是: ==表示相等, !=不相等,> 表示大于 < 表示小于,>=大于等于,<=小于等于
# student_list = Student.query.filter(Student.age > 18).all()
# print(student_list) # [wang<Student>, chen<Student>, zhou<Student>,...]
"""多条件比较"""
# 要求多个条件都要满足,相当于逻辑查询中的 并且(and)!!
student_list = Student.query.filter(Student.age > 18, Student.sex == True).all()
print(student_list) # [wang<Student>, chen<Student>, qian<Student>, liu<Student>]
# 另一种写法的查询方式
# db.session.query(Student) 相当于 Student.query
student_list = db.session.query(Student).filter(Student.money>100).all()
print(student_list) # [dong<Student>, 小红<Student>, chen<Student>, li<Student>]
|
filter_by精确条件查询,只支持字段的值是否相等这种条件
例如:返回age等于22的学生
1
2
3
4
5
6
7
|
# 单条件
student_list = Student.query.filter_by(age=22).all()
print(student_list)
# 多条件
student_list = Student.query.filter_by(age=22,sex=True).all()
print(student_list)
|
练习:
1
2
3
4
5
6
7
|
查询所有男生数据
查询id为4的学生[3种方式]
查询年龄等于22的所有学生数据
查询name为liu的学生数据
|
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
@app.route("/")
def index():
"""
# 查询所有男生数据
student_list = Student.query.filter(Student.sex==True).all()
print(student_list)
# 查询id为6的学生[3种方式]
"""
# student = Student.query.get(6)
# print(student)
# student = Student.query.filter(Student.id==6).first()
# print(student)
# student = Student.query.filter_by(id=6).first()
# print(student)
"""
查询年龄等于22的所有学生数据
"""
# student_list = Student.query.filter(Student.age==22).all() # marshmallow
# print(student_list) # [dong<Student>, zhou<Student>, tang<Student>, li<Student>, sun<Student>]
"""
查询name为liu的学生数据
"""
# student = Student.query.filter(Student.name=="liu").first()
# print(student)
return "ok"
|
多条件查询
逻辑与,需要导入and_,返回and_()条件满足的所有数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
from sqlalchemy import and_
Student.query.filter(and_(Student.name!='wang',Student.email.endswith('163.com'))).all()
# # and_(条件1,条件2,....) 等价于 filter(条件1,条件2,.....)
# # age > 18 and email like "%163.com"
# # student_list = Student.query.filter(Student.age > 18, Student.email.endswith("163.com")).all()
#
# student_list = Student.query.filter(
# and_(
# Student.age > 18,
# Student.email.endswith("163.com")
# )
# ).all()
|
逻辑或,需要导入or_
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
from sqlalchemy import or_
Student.query.filter(or_(Student.name!='wang',Student.email.endswith('163.com'))).all()
# 查询年龄在22岁,使用的邮箱是126或者163邮箱的
student_list = Student.query.filter(Student.age==22, or_(
Student.email.endswith("@126.com"),
Student.email.endswith("@163.com"),
)).all()
print(student_list)
# 复合条件的查询情况
# 查询年龄>18岁的女生或者年龄>22岁的男生
# 查询(年龄>18岁的女生)或者(年龄>22岁的男生)
student_list = Student.query.filter(or_(
and_(Student.age>18, Student.sex==False),
and_(Student.age>22, Student.sex==True),
)).all()
# student_list = Student.query.filter(or_(
# and_(Student.age>18, not_(Student.sex)),
# and_(Student.age>22, Student.sex),
# )).all()
print(student_list)
|
逻辑非,返回名字不等于wang的所有数据
1
|
Student.query.filter(Student.name!='wang').all()
|
not_ 相当于取反
1
2
3
4
5
6
7
8
|
from sqlalchemy import not_
Student.query.filter(not_(Student.name=='wang')).all()
# # 查询年龄不等于22
# student_list = Student.query.filter(Student.age != 22).all()
# print(student_list)
# student_list = Student.query.filter(not_(Student.age==22)).all()
# print(student_list)
|
in_范围查询
1
2
3
4
5
6
7
|
# 查询id是 5, 7, 10 的学生信息
student_list = Student.query.filter(Student.id.in_([5, 7, 10])).all()
print(student_list)
# 查询id不是 1 3 5 的学生信息
student_list = Student.query.filter(not_(Student.id.in_([1, 3, 5]))).all()
print( student_list )
|
order_by 排序
1
2
3
4
5
6
7
8
|
# 倒序[值从大到小]
student_list = Student.query.order_by(Student.id.desc()).all()
# 升序[值从小到大]
student_list = Student.query.order_by(Student.id.asc()).all()
# 多字段排序[第一个字段值一样时,比较第二个字段,进行排序]
student_list = Student.query.order_by(Student.money.asc(), Student.age.asc(), Student.id.asc()).all()
print(student_list)
|
count统计
1
2
3
4
|
# 查询age>=19的男生的数量
from sqlalchemy import and_
# ret = Student.query.filter( and_(Student.age>=19,Student.sex==True) ).count()
ret = Student.query.filter( Student.age>=19, Student.sex==True ).count()
|
对结果进行偏移量和数量的限制
1
2
3
4
5
6
7
8
9
10
11
|
# 查询年龄最大的3个学生
student_list = Student.query.order_by(Student.age.desc()).limit(3).all()
print(student_list)
# 查询年龄排第4到第7名的学生
student_list = Student.query.order_by(Student.age.desc()).offset(3).limit(4).all()
print(student_list)
# 查询年龄最小的3个人
student_list = Student.query.order_by(Student.age.asc()).limit(3).all()
print(student_list)
|
SQL
1
2
3
4
5
6
7
8
9
|
# 查询年龄最大的3个学生
# select * from db_student order by age desc limit 3;
# 查询年龄排第4到第7名的学生
select * from db_student order by age desc limit 3, 4;
# select * from db_student order by age desc limit 4 offset 3;
# 查询年龄最小的3个人
# select * from db_student order by age asc limit 3;
|
练习
1
2
3
4
5
|
# 查询age是18 或者 使用163邮箱的所有学生
Student.query.filter(or_(Student.age==18,Student.email.endswith("163.com"))).all()
# 查询id为 [1, 3, 5, 7, 9] 的学生列表
student_list = Student.query.filter(Student.id.in_([1, 3, 5, 7, 9])).all()
print(student_list)
|
分页器
manage.py,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
class Config(object):
DEBUG = True
# 数据库链接配置 = 数据库名称://登录账号:登录密码@数据库主机IP:数据库访问端口/数据库名称?charset=编码类型
SQLALCHEMY_DATABASE_URI = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = False
# ORM运行时会显示ORM生成的原始SQL语句[调试]
SQLALCHEMY_ECHO = True
app.config.from_object(Config)
"""模型类定义"""
db = SQLAlchemy(app=app)
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), index=True, comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), unique=True, comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
def __repr__(self): # 相当于django的__str__
return f"{self.name}<{self.__class__.__name__}>"
# 所有的模型必须直接或间接继承于db.Model
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2), comment="价格")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
class Teacher(db.Model):
"""老师数据模型"""
__tablename__ = "db_teacher"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="姓名")
option = db.Column(db.Enum("讲师", "助教", "班主任"), default="讲师")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
from flask import request,render_template
@app.route("/")
def index():
# 分页器
page = int(request.args.get("page", 1))
size = int(request.args.get("size", 3))
pagination = Student.query.paginate(page, size)
print(pagination)
"""
from flask_sqlalchemy import Pagination
# 常用属性
total 总数据量
items 每一页数据项列表
pages 总页码===> math.ceil( total/per_page )
# 常用方法
prev 上一页分页对象
prev_num 上一页页码
has_prev 是否有上一页
next 下一页分页对象
next_num 下一页页码
has_next 是否有下一页
"""
print(pagination.items) # 当前页的数据项列表
print(pagination.total) # 总数据量
print(pagination.pages) # 总页码数量
print(pagination.prev_num) # 上一页页码
print(pagination.next_num) # 下一页页码
print(pagination.has_prev) # 是否有上一页
print(pagination.has_next) # 是否有下一页
print(pagination.prev()) # 上一页的分页对象
print(pagination.next()) # 下一页的分页对象
# """前后端分离"""
# data = {
# "page": pagination.page, # 当前页码
# "pages": pagination.pages, # 总页码
# "has_prev": pagination.has_prev, # 是否有上一页
# "prev_num": pagination.prev_num, # 上一页页码
# "has_next": pagination.has_next, # 是否有下一页
# "next_num": pagination.next_num, # 下一页页码
# "items": [{
# "id": item.id,
# "name": item.name,
# "age": item.age,
# "sex": item.sex,
# "money": item.money,
# } for item in pagination.items]
# }
# return data
"""前后端不分离"""
return render_template("list.html",**locals())
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run()
|
list.html,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
.page a,.page span{
padding: 2px 6px;
color: #fff;
background: #6666ff;
text-decoration: none;
}
.page span{
color: #fff;
background: orange;
}
</style>
</head>
<body>
<table border="1" align="center" width="600">
<tr>
<th>ID</th>
<th>age</th>
<th>name</th>
<th>sex</th>
<th>money</th>
</tr>
{% for student in pagination.items %}
<tr>
<td>{{ student.id }}</td>
<td>{{ student.age }}</td>
<td>{{ student.name }}</td>
<td>{{ "男" if student.sex else "女" }}</td>
<td>{{ student.money }}</td>
</tr>
{% endfor %}
<tr align="center">
<td colspan="5" class="page">
{% if pagination.has_prev %}
<a href="?page=1">首 页</a>
<a href="?page={{ pagination.page-1 }}">上一页</a>
<a href="?page={{ pagination.page-1 }}">{{ pagination.page-1 }}</a>
{% endif %}
<span>{{ pagination.page }}</span>
{% if pagination.has_next %}
<a href="?page={{ pagination.page+1 }}">{{ pagination.page+1 }}</a>
<a href="?page={{ pagination.page+1 }}">下一页</a>
<a href="?page={{ pagination.pages }}">尾 页</a>
{% endif %}
</td>
</tr>
</table>
</body>
</html>
|
聚合分组
分组查询和分组查询结果过滤
一般分组都会结合聚合函数来一起使用。SQLAlchemy中所有的聚合函数都在func模块中声明的。
from sqlalchemy import func
| 函数名 |
说明 |
|
| func.count |
统计总数 |
|
| func.avg |
平均值 |
|
| func.min |
最小值 |
|
| func.max |
最大值 |
|
| func.sum |
和 |
|
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
"""聚合函数"""
from sqlalchemy import func
# 获取所有学生的money总数
# SELECT sum(db_student.money) AS sum_1 FROM db_student LIMIT %s
# ret = db.session.query(func.sum(Student.money)).first()[0]
# print(ret) # 3998.0
# # 查询女生的数量
# ret = db.session.query(func.count(Student.id)).filter(Student.sex==False).first()[0]
# print(ret) # 7
# # 查询所有学生的平均年龄
# ret = db.session.query(func.avg(Student.age)).first()[0]
# print(ret) # 18.2727
"""
聚合分组
在聚合分组的情况下,db.session.query中的参数只能是被分组的字段或者是被聚合的数据
"""
# # 查询当前所有男生女生的数量
# ret = db.session.query(Student.sex,func.count(Student.id)).group_by(Student.sex).all()
# print(ret) # [(False, 7), (True, 4)]
# # 查询各个年龄段的学生数量
# ret = db.session.query(Student.age, func.count(Student.id)).group_by(Student.age).all()
# print(ret) # [(15, 2), (13, 1), (22, 4), (19, 1), (18, 1), (16, 1), (17, 1)]
#
# # 查看当前男生女生的平均年龄
# ret = db.session.query(Student.sex, func.avg(Student.age)).group_by(Student.sex).all()
# ret = [{"sex":"男" if item[0] else "女","age":float(item[1])} for item in ret]
# print(ret) # [{'sex': '女', 'age': 18.0}, {'sex': '男', 'age': 18.75}]
# # 分组后的过滤操作 having
# # 在所有学生中,找出各个年龄中拥有最多钱的同学,并在这些同学里面筛选出money > 500的数据
# subquery = func.max(Student.money)
# print(subquery) # max(db_student.money)
# ret = db.session.query(Student.age, subquery).group_by(Student.age).having(subquery > 500).all()
# print(ret) # [(18, Decimal('1000.00')), (22, Decimal('26000.00')), (23, Decimal('1998.00'))]
"""
多字段分组
字段1 字段2
1 3
2 4
分组如下:
13
14
23
24
"""
# 各个年龄里,男生和女生的money总数
subquery = func.sum(Student.money)
ret = db.session.query(Student.sex, Student.age, subquery).group_by(Student.sex, Student.age).all()
print(ret) # [(False, 15, 1000.0), (False, 13, 600.0), (True, 15, 0.0), (True, 22, 1998.0), (False, 19, 0.0), (False, 22, 400.0), (False, 18, 0.0), (True, 16, 0.0), (False, 17, 0.0)]
|
SQL方法中的关键字顺序:
1
2
3
4
5
6
7
|
模型.query. // db.session.query.
filter/ filter_by
group by
having
order_by
limit offset
all / get / first / count / pagination
|
执行原生SQL语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
"""执行原生SQL语句"""
# # 查询多条数据
# ret = db.session.execute("select * from db_student").fetchall()
# print(ret)
# # 查询一条数据
# ret = db.session.execute("select * from db_student").fetchone()
# print(ret)
"""
name age achievement
80
小明 17 81
83
group_concat 逗号合并
小明 17 80,81,83
concat 字符串拼接
小明 17 808183
"""
# # 添加数据
# db.session.execute("insert db_student (name,age,sex,email,money) select name,age,sex,concat(now(),email),money from db_student")
# db.session.commit()
# # # 更新/删除
# db.session.execute("UPDATE db_student SET money=(db_student.money + %s) WHERE db_student.age = %s" % (200, 22))
# db.session.commit()
"""分组合并"""
# 统计各个年龄段的学生人数,并记录对应年龄段的学生ID
ret = db.session.execute("select age,count(id),group_concat(id) from db_student group by age").fetchall()
print(ret)
return "ok"
|
关联查询
常用的SQLAlchemy关系选项
| 选项名 |
说明 |
| backref |
在关系的另一模型中添加反向引用,用于设置外键名称,在1查多的 |
| primary join |
明确指定两个模型之间使用的连表条件,用于1对1 或者1对多连表中 |
| lazy |
指定如何加载关联模型数据的方式,用于1对1或1对多链表中。参数值:select(立即加载,查询所有相关数据显示,相当于lazy=True)subquery(立即加载,但使用子查询)dynamic(不立即加载,但提供加载记录的查询对象) |
| uselist |
指定1对1或1对多连表时,返回的数据结果是模型对象还是模型列表,如果为False,不使用列表,而使用模型对象。1对1或多对1关系中,需要设置relationship中的uselist=Flase,1对多或多对多关系中,需要设置relationshio中的uselist=True。 |
| secondary |
指定多对多关系中关系表的名字。多对多关系中,需建立关系表,设置 secondary=关系表 |
| secondary join |
在SQLAlchemy中无法自行决定时,指定多对多关系中的二级连表条件 |
三范式+逆范式
第三范式:数据不能冗余,把关联性不强的数据可以移除到另一个表中。使用外键进行管理。
1
2
3
|
1对1:把主表的主键放到附加表中作为外键存在。
1对多:把主表(1) 的主键放到附加表(多)作为外键存在。
多对多:把主表(多)的主键和附加表的(多)主键,放到第三方表(关系表)中作为外键。
|
模型之间的关联
一对一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
class Student(db.Model):
"""个人信息主表"""
....
# 关联属性,这个不会被视作表字段,只是模型对象的属性。
# 因为StudentInfo和Student是一对一的关系,所以uselist=False表示关联一个数据
info = db.relationship("StudentInfo", uselist=False, backref="own")
class StudentInfo(db.Model):
"""个人信息附加表"""
# 外键,
# 如果是一对一,则外键放在附加表对应的模型中
# 如果是一对多,则外键放在多的表对象的模型中
# uid = db.Column(db.Integer, db.ForeignKey(Student.id),comment="外键")
uid = db.Column(db.Integer, db.ForeignKey("student表名.主键"),comment="外键")
|
关联属性声明在主模型中【最常用】
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
from flask import Flask, request, render_template
from flask_sqlalchemy import SQLAlchemy
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
"""模型声明"""
class Student(db.Model):
"""学生信息"""
# 表名
__tablename__ = "db_student"
# 字段列表
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(255), index=True, comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(255), unique=True, comment="邮箱地址")
money = db.Column(db.Numeric(10, 2), default=0.0, comment="钱包")
info = db.relationship("StudentInfo", uselist=False, backref="own")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
class StudentInfo(db.Model):
"""学生信息附加表"""
__tablename__ = "db_student_info"
id = db.Column(db.Integer, primary_key=True, comment="主键")
address = db.Column(db.String(500), nullable=True, comment="地址")
mobile = db.Column(db.String(15), nullable=True, comment="紧急号码")
student_id = db.Column(db.Integer, db.ForeignKey("db_student.id"), comment="学生id")
@app.route("/q1")
def q1():
# 添加主表信息的时候通过关联属性db.relationship同步添加附件表信息
student = Student(
name="xiaolan02",
age=16,
sex=False,
money=10000,
email="xiaolan02@qq.com",
info=StudentInfo(address="北京市昌平区百沙路204号", mobile="13312345678")
)
db.session.add(student)
db.session.commit()
return "ok"
@app.route("/q2")
def q2():
# 添加附加表数据,通过关联属性中db.relationshop的backref同步添加主表数据
info = StudentInfo(
address="北京市昌平区百沙路204号",
mobile="15012345678",
own = Student(
name="xiaolan03",
age=16,
sex=False,
money=10000,
email="xiaolan03@qq.com",
)
)
db.session.add(info)
db.session.commit()
return "ok"
@app.route("/q3")
def q3():
"""查询数据"""
# # 正向关联----> 从主模型查询外键模型
# student = Student.query.get(2)
# print(student.name) # xiaolan02
# print(student.info) # <StudentInfo 1>
# print(student.info.address) # 北京市昌平区百沙路204号
# # 反向关联----> 从外键模型查询主模型
# student_info = StudentInfo.query.filter(StudentInfo.mobile=="15012345678").first()
# print(student_info.address) # 北京市昌平区百沙路204号
# print(student_info.own) # xiaolan03<Student>
# print(student_info.own.name) # xiaolan03
# print(student_info.student_id) # 4
return "ok"
@app.route("/")
def q4():
"""修改数据"""
# # 通过主表使用关联属性可以修改附加表的数据
# student = Student.query.get(2)
# student.info.address = "广州市天河区天河东路103号"
# db.session.commit()
# 也可以通过附加表模型直接修改主表的数据
student_info = StudentInfo.query.filter(StudentInfo.mobile == "13312345678").first()
print(student_info.own)
student_info.own.age = 22
db.session.commit()
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
在外键模型中声明关联属性
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
|
from flask import Flask, request, render_template
from flask_sqlalchemy import SQLAlchemy
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = True
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
"""模型声明"""
class Student(db.Model):
"""学生信息"""
# 表名
__tablename__ = "db_student"
# 字段列表
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(255), index=True, comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(255), unique=True, comment="邮箱地址")
money = db.Column(db.Numeric(10, 2), default=0.0, comment="钱包")
# info = db.relationship("StudentInfo", uselist=False, backref="own")
def __repr__(self):
return f"{self.name}<{self.__class__.__name__}>"
class StudentInfo(db.Model):
"""学生信息附加表"""
__tablename__ = "db_student_info"
id = db.Column(db.Integer, primary_key=True, comment="主键")
address = db.Column(db.String(500), nullable=True, comment="地址")
mobile = db.Column(db.String(15), nullable=True, comment="紧急号码")
own = db.relationship("Student", uselist=False, backref="info")
student_id = db.Column(db.Integer, db.ForeignKey("db_student.id"), comment="学生id")
@app.route("/q1")
def q1():
# 添加主表信息的时候通过关联属性db.relationship同步添加附件表信息
student = Student(
name="xiaolan02",
age=16,
sex=False,
money=10000,
email="xiaolan02@qq.com",
info=StudentInfo(address="北京市昌平区百沙路204号", mobile="13312345678")
)
db.session.add(student)
db.session.commit()
return "ok"
@app.route("/q2")
def q2():
# 添加附加表数据,通过关联属性中db.relationshop的backref同步添加主表数据
info = StudentInfo(
address="北京市昌平区百沙路204号",
mobile="15012345678",
own = Student(
name="xiaolan03",
age=16,
sex=False,
money=10000,
email="xiaolan03@qq.com",
)
)
db.session.add(info)
db.session.commit()
return "ok"
@app.route("/q3")
def q3():
"""查询数据"""
# # 正向关联----> 从主模型查询外键模型
# student = Student.query.get(2)
# print(student.name) # xiaolan02
# print(student.info) # <StudentInfo 1>
# print(student.info.address) # 北京市昌平区百沙路204号
# # 反向关联----> 从外键模型查询主模型
# student_info = StudentInfo.query.filter(StudentInfo.mobile=="15012345678").first()
# print(student_info.address) # 北京市昌平区百沙路204号
# print(student_info.own) # xiaolan03<Student>
# print(student_info.own.name) # xiaolan03
# print(student_info.student_id) # 4
return "ok"
@app.route("/")
def q4():
"""修改数据"""
# # 通过主表使用关联属性可以修改附加表的数据
# student = Student.query.get(2)
# student.info.address = "广州市天河区天河东路103号"
# db.session.commit()
# 也可以通过附加表模型直接修改主表的数据
student_info = StudentInfo.query.filter(StudentInfo.mobile == "13312345678").first()
print(student_info.own)
student_info.own.age = 22
db.session.commit()
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
一对多
1
2
3
4
5
6
7
8
9
|
class Student(db.Model):
...
# 关联属性,一的一方添加模型关联属性
address_list = db.relationship("StudentAddress", uselist=True, backref="own", lazy='dynamic')
class StudentAddress(db.Model):
...
# 外键,多的一方模型中添加外间
student_id = db.Column(db.ForeignKey(Student.id))
|
- 其中realtionship描述了Student和StudentAddress的关系。第1个参数为对应参照的类"StudentAddress"
- 第3个参数backref为类StudentAddress声明关联属性
- 第4个参数lazy决定了什么时候SQLALchemy从数据库中加载外键模型的数据
- lazy=‘subquery’,查询当前数据模型时,采用子查询(subquery),把外键模型的属性也同时查询出来了。
- lazy=True或lazy=‘select’,查询当前数据模型时,不会把外键模型的数据查询出来,只有操作到外键关联属性时,才进行连表查询数据[执行SQL]
- lazy=‘dynamic’,查询当前数据模型时,不会把外键模型的数据立刻查询出来,只有操作到外键关联属性并操作外键模型具体字段时,才进行连表查询数据[执行SQL]
- 常用的lazy选项:dynamic和select
课堂代码:
manage.py,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
|
from flask import Flask, request, render_template
from flask_sqlalchemy import SQLAlchemy
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
address_list = db.relationship("StudentAddress", uselist=True, backref="own", lazy="dynamic")
def __repr__(self):
return f"{self.name}<Student>"
class StudentAddress(db.Model):
"""学生收货地址"""
__tablename__ = "db_student_address"
id = db.Column(db.Integer, primary_key=True, comment="主键")
province = db.Column(db.String(20), comment="省份")
city = db.Column(db.String(20), comment="城市")
area = db.Column(db.String(20), comment="地区")
address = db.Column(db.String(250), comment="详细地址")
student_id = db.Column(db.Integer, db.ForeignKey("db_student.id",), comment="学生id")
def __repr__(self):
return f"{self.province}-{self.city}-{self.area}-{self.address}"
@app.route("/q1")
def q1():
"""添加数据"""
# # 添加主模型,可以以列表形式,一次性添加多个附加模型数据进去。
# student = Student(
# name="xiaolan001",
# age=16,
# sex=False,
# money=10000,
# email="xiaolan01@qq.com",
# address_list=[
# StudentAddress(province="北京市", city="北京市", area="昌平区", address="百沙路201"),
# StudentAddress(province="北京市", city="北京市", area="昌平区", address="百沙路202"),
# StudentAddress(province="北京市", city="北京市", area="昌平区", address="百沙路203"),
# ]
# )
# db.session.add(student)
# db.session.commit()
# 添加外键模型数据的同时,添加主模型数据
address = StudentAddress(
province="天津市",
city="天津市",
area="静海区",
address="静安路1103号",
own=Student(
name="xiaolan04",
age=16,
sex=False,
money=10000,
email="xiaolan04@qq.com",
)
)
db.session.add(address)
db.session.commit()
return "ok"
@app.route("/")
def q2():
# 正向关联----> 从主模型查询外键模型
student = Student.query.filter(Student.name == "xiaolan001").first()
print(student) # xiaolan001<Student>
# 获取地址列表
# lazy="dynamic",student.address_list 是一条未执行的SQL语句。没有拿到关联模型的数据
# lazy="select" || lazy=True,student.address_list 是一个列表。
# lazy="subquery",student.address_list 也是一个列表。
print("2>>> ", student.address_list)
# 获取地址列表中某个成员的字段
print("3>>> ", student.address_list[0].address) # dynamic 是在关联模型属性调用具体的字段以后才执行SQL语句
print("4>>> ", student.address_list[0].address) # 来到这里的时候,因为上面已经获取到数据了,此时这里是缓存中提取了数据的
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
多对多
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
# 关系表
achievement = db.Table('tb_achievement',
db.Column('student_id', db.Integer, db.ForeignKey('tb_student.id')),
db.Column('course_id', db.Integer, db.ForeignKey('tb_course.id')),
)
class Course(db.Model):
...
student_list = db.relationship('Student',secondary=achievement,
backref='course_list',
lazy='dynamic')
class Student(db.Model):
...
# 关系模型,[关系模型和关系表,任选其一]
class Achievement(db.Model):
...
|
多对多,也可以拆解成3个模型(2个主模型,1个关系模型,关系模型保存了2个主模型的外键),其中tb_achievement作为单独模型存在。
基于第三方关系表构建多对多
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
|
from flask import Flask, request, render_template
from flask_sqlalchemy import SQLAlchemy
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
# 第三方关系表[只会记录2个模型之间的关联关系]
student_course = db.Table(
"db_student_course",
db.Column('id', db.Integer, primary_key=True, comment="主键ID"),
db.Column('student_id', db.Integer, db.ForeignKey('db_student.id'), comment="学生"),
db.Column('course_id', db.Integer, db.ForeignKey('db_course.id'), comment="课程"),
)
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
# 关联属性[任意一个主模型中声明即可]
course_list = db.relationship("Course", secondary=student_course, backref="student_list", lazy="dynamic")
def __repr__(self):
return f"{self.name}<Student>"
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2))
def __repr__(self):
return f'{self.name}<{self.__class__.__name__}>'
@app.route("/q1")
def q1():
"""添加数据"""
"""添加其中一个主模型数据时,同时绑定添加另外一个主模型的数据,这个过程中,关系表会自动绑定2个模型之间的关系"""
# student = Student(
# name="xiaozhao",
# age=13,
# sex=False,
# money=30000,
# email="100000@qq.com",
# course_list=[
# Course(name="python入门", price=99.99),
# Course(name="python初级", price=199.99),
# Course(name="python进阶", price=299.99),
# ]
# )
# db.session.add(student)
# db.session.commit()
"""在学生报读课程的基础上,新增报读课程。"""
# student = Student(
# name="xiaohong",
# age=14,
# sex=False,
# money=30000,
# email="300000@qq.com",
# )
# db.session.add(student)
# db.session.commit()
#
# student = Student.query.filter(Student.name=="xiaohong").first()
# student.course_list.append(Course.query.get(3)) # 新增已经存在的课程
# student.course_list.append(Course(name="python顶级", price=399.99)) # 已有课程,并让当前学生报读该课程
# db.session.commit()
"""添加学生报读课程的测试数据"""
# student1 = Student.query.get(1)
# course_list = Course.query.filter(Course.id.in_([1,2])).all()
# student1.course_list.extend(course_list)
#
# student2 = Student.query.get(2)
# course_list = Course.query.filter(Course.id.in_([3,2])).all()
# student2.course_list.extend(course_list)
#
# student3 = Student.query.get(3)
# course_list = Course.query.filter(Course.id.in_([4,3,1])).all()
# student3.course_list.extend(course_list)
# db.session.commit()
return "ok"
@app.route("/q2")
def q2():
"""查询操作"""
# 查询ID=4的学生报读的课程列表
# student = Student.query.get(4)
# course_list = [{"name":item.name,"price":float(item.price)} for item in student.course_list]
# print(course_list)
# 查询出2号课程,都有那些学生在读?
# course = Course.query.get(2)
# student_list = [{"name":item.name,"age":item.age} for item in course.student_list]
# print(student_list)
return "ok"
@app.route("/")
def q3():
"""更新数据"""
# # 给报读了3号课程的同学,返现红包200块钱
# course = Course.query.get(3)
# for student in course.student_list:
# student.money+=200
# db.session.commit()
# db.Table的缺陷: 无法通过主模型直接操作db.Table中的外键之外的其他字段
course = Course.query.get(3)
print(course.student_list)
# 解决:在声明2个模型是多对多的时候,把这个模型的关联关系使用模型来创建声明
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
基于第三方关系模型构建多对多
在SQLAlchemy中,基于db.Table创建的关系表,如果需要新增除了外键以外其他字段,无法操作。所以将来实现多对多的时候,除了上面db.Table方案以外,还可以把关系表声明成模型的方法,如果声明成模型,则原来课程和学生之间的多对多的关系,就会变成远程的1对多了。
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
def __repr__(self):
return f"{self.name}<Student>"
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2))
def __repr__(self):
return f'{self.name}<{self.__class__.__name__}>'
from sqlalchemy.orm import backref
class StudentCourse(db.Model):
"""学生和课程之间的关系模型"""
__tablename__ = "db_student_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
student_id = db.Column(db.Integer, db.ForeignKey(Student.id))
course_id = db.Column(db.Integer, db.ForeignKey(Course.id))
score = db.Column(db.Numeric(4,1), default=0, comment="成绩")
time = db.Column(db.DateTime, default=datetime.now, comment="考试时间")
# 关联属性
student = db.relationship("Student", uselist=False, backref=backref("to_course", uselist=True))
course = db.relationship("Course", uselist=False, backref=backref("to_student", uselist=True))
@app.route("/q1")
def q1():
"""添加数据"""
# 记录xiaobai本次的python入门考试成绩: 88
# rel = StudentCourse(
# student= Student(
# name="xiaobai",
# age=13,
# sex=False,
# money=30000,
# email="100000@qq.com",
# ),
# course = Course(name="python入门", price=99.99),
# score = 81,
# )
# db.session.add(rel)
# db.session.commit()
rel2 = StudentCourse(
student= Student.query.filter(Student.name=="xiaobai").first(), # 学生已存在
course = Course(name="python基础", price=199.99), # 新曾课程
score = 75,
)
db.session.add(rel2)
db.session.commit()
return "ok"
@app.route("/")
def q2():
"""查询操作"""
# 查询xiaobai的成绩
student = Student.query.filter(Student.name == "xiaobai").first()
print(student.to_course)
for student_course in student.to_course:
print(f"学生:{student_course.student.name},课程:{student_course.course.name},成绩:{student_course.score}")
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
relationship还有一个设置外键级联的属性:cascade=“all, delete, delete-orphan”
作业:
1. 我们现在学习的flask框架集成SQLAlchemy操作数据库使用的是flask-SQLAlchemy模块。如果原生的python下面应该如何使用SQLAlchemy进行初始化数据库连接和声明模型并实现模型的基本操作[增删查改,关联查询]?
2. flask中的SQLAlchemy如何进行自关联查询? 这里自己写一个关于行政区划的自关联操作。
逻辑外键
也叫虚拟外键。主要就是在开发中为了减少数据库的性能消耗,提升系统运行效率,一般项目中如果单表数据太大就不会使用数据库本身维护的物理外键,而是采用由ORM或者我们逻辑代码进行查询关联的逻辑外键。
SQLAlchemy设置外键模型的虚拟外键,有2种方案:
方案1,查询数据时临时指定逻辑外键的映射关系:
1
|
模型.query.join(模型类,主模型.主键==外键模型.外键).join(模型类,主模型.主键==外键模型.外键).with_entities(字段1,字段2.label("字段别名"),....).all()
|
方案2,在模型声明时指定逻辑外键的映射关系(最常用,这种设置方案,在操作模型时与原来默认设置的物理外键的关联操作是一模一样的写法):
1
2
3
4
5
6
7
8
9
10
|
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True, comment="主键")
# 虚拟外键,原有参数不变,新增2个表达关联关系的属性:
# primaryjoin, 指定2个模型之间的主外键关系,相当于原生SQL语句中的join
# foreign_keys,指定外键
address_list = db.relationship("StudentAddress", uselist=True, backref="student", lazy="subquery", primaryjoin="Student.id==StudentAddress.student_id", foreign_keys="StudentAddress.student_id")
class StudentAddress(db.Model):
# 原来的外键设置为普通索引即可。
student_id = db.Column(db.Integer, comment="学生id")
|
例1,虚拟外键使用的方案1,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
def __repr__(self):
return f"{self.name}<Student>"
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2))
def __repr__(self):
return f'{self.name}<{self.__class__.__name__}>'
class StudentCourse(db.Model):
"""学生和课程之间的关系模型"""
__tablename__ = "db_student_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
student_id = db.Column(db.Integer)
course_id = db.Column(db.Integer)
score = db.Column(db.Numeric(4,1), default=0, comment="成绩")
time = db.Column(db.DateTime, default=datetime.now, comment="考试时间")
@app.route("/")
def q2():
# 添加测试数据
# stu0 = Student(name="xiaoming-0",age=15,sex=True,email="xiaoming0@qq.com", money=1000)
# stu1 = Student(name="xiaoming-1",age=15,sex=True,email="xiaoming1@qq.com", money=1000)
# stu2 = Student(name="xiaoming-2",age=15,sex=True,email="xiaoming2@qq.com", money=1000)
# stu3 = Student(name="xiaoming-3",age=15,sex=True,email="xiaoming3@qq.com", money=1000)
# stu4 = Student(name="xiaoming-4",age=15,sex=True,email="xiaoming4@qq.com", money=1000)
# stu5 = Student(name="xiaoming-5",age=15,sex=True,email="xiaoming5@qq.com", money=1000)
# stu6 = Student(name="xiaoming-6",age=15,sex=True,email="xiaoming6@qq.com", money=1000)
# stu7 = Student(name="xiaoming-7",age=15,sex=True,email="xiaoming7@qq.com", money=1000)
# stu8 = Student(name="xiaoming-8",age=15,sex=True,email="xiaoming8@qq.com", money=1000)
# stu9 = Student(name="xiaoming-9",age=15,sex=True,email="xiaoming9@qq.com", money=1000)
# db.session.add_all([stu0,stu1,stu2,stu3,stu4,stu5,stu6,stu7,stu8,stu9])
# course1 = Course(name="python基础第1季", price=1000)
# course2 = Course(name="python基础第2季", price=1000)
# course3 = Course(name="python基础第3季", price=1000)
# course4 = Course(name="python基础第4季", price=1000)
# course5 = Course(name="python基础第5季", price=1000)
# db.session.add_all([course1, course2, course3, course4, course5])
# data = [
# StudentCourse(student_id=1,course_id=1,score=60,time=datetime.now()),
# StudentCourse(student_id=1,course_id=2,score=60,time=datetime.now()),
# StudentCourse(student_id=1,course_id=3,score=60,time=datetime.now()),
# StudentCourse(student_id=2,course_id=1,score=60,time=datetime.now()),
# StudentCourse(student_id=2,course_id=2,score=60,time=datetime.now()),
# StudentCourse(student_id=3,course_id=3,score=60,time=datetime.now()),
# StudentCourse(student_id=3,course_id=4,score=60,time=datetime.now()),
# StudentCourse(student_id=4,course_id=5,score=60,time=datetime.now()),
# StudentCourse(student_id=4,course_id=1,score=60,time=datetime.now()),
# StudentCourse(student_id=4,course_id=2,score=60,time=datetime.now()),
# StudentCourse(student_id=5,course_id=1,score=60,time=datetime.now()),
# StudentCourse(student_id=5,course_id=2,score=60,time=datetime.now()),
# StudentCourse(student_id=5,course_id=3,score=60,time=datetime.now()),
# StudentCourse(student_id=5,course_id=4,score=60,time=datetime.now()),
# ]
# db.session.add_all(data)
# db.session.commit()
# 使用逻辑外检来查询数据
# 主模型.query.join(从模型类名, 关系语句)
# 主模型.query.join(从模型类名, 主模型.主键==从模型类名.外键)
# 查询课程[python基础第3季]有多少学生在读?2表关联
# course = Course.query.join(
# StudentCourse,
# Course.id==StudentCourse.course_id
# ).with_entities(
# Course.id, Course.name, Course.price, StudentCourse.student_id, StudentCourse.score
# ).filter(Course.name=="python基础第3季").count()
#
# print(course)
# 查询课程[python基础第3季]有哪些学生在读?3表关联
# 正向查询和逆向查询都是通过声明临时外键关系来完成关联查询操作。
student_list = Course.query.join(
StudentCourse,
Course.id==StudentCourse.course_id
).join(
Student,
Student.id==StudentCourse.student_id
).with_entities(
Course.name.label("course_name"), StudentCourse.score.label("score"), Student.name.label("student_name"),
).filter(Course.name=="python基础第3季").all()
print(student_list)
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
例2,虚拟外键使用的方案2,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from datetime import datetime
# 实例化
db = SQLAlchemy()
app = Flask(__name__)
# SQLAlchemy的链接配置:"数据库名://账户名:密码@服务器地址:端口/数据库名称?配置参数选项"
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
#查询时会显示原始SQL语句
app.config["SQLALCHEMY_ECHO"] = True
# 初始化,加载项目配置信息
db.init_app(app=app)
class Student(db.Model):
"""学生信息模型"""
# 声明与当前模型绑定的数据表名称
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
def __repr__(self):
return f"{self.name}<Student>"
class Course(db.Model):
"""课程数据模型"""
__tablename__ = "db_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
name = db.Column(db.String(64), unique=True, comment="课程")
price = db.Column(db.Numeric(7, 2))
def __repr__(self):
return f'{self.name}<{self.__class__.__name__}>'
from sqlalchemy.orm import backref
class StudentCourse(db.Model):
"""学生和课程之间的关系模型"""
__tablename__ = "db_student_course"
id = db.Column(db.Integer, primary_key=True, comment="主键")
student_id = db.Column(db.Integer)
course_id = db.Column(db.Integer)
score = db.Column(db.Numeric(4,1), default=0, comment="成绩")
time = db.Column(db.DateTime, default=datetime.now, comment="考试时间")
student = db.relationship(
"Student",
uselist=False,
backref=backref("to_course", uselist=True),
lazy="subquery",
primaryjoin="Student.id==StudentCourse.student_id",
foreign_keys="StudentCourse.student_id"
)
course = db.relationship(
"Course",
uselist=False,
backref=backref("to_student", uselist=True),
lazy="subquery",
primaryjoin="Course.id==StudentCourse.course_id",
foreign_keys="StudentCourse.course_id"
)
@app.route("/")
def q2():
student = Student.query.filter(Student.name=="xiaoming-0").first()
print([{
"course_name":item.course.name,
"score":item.score,
"student_name":item.student.name,
} for item in student.to_course])
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run(host="0.0.0.0", port=5000, debug=True)
|
数据迁移
- 在开发过程中,需要修改数据库模型,而且还要在修改之后更新数据库。最直接的方式就是删除旧表,但这样会丢失数据,所以往往更常见的方式就是使用alter来改变数据结构,原有数据中的新字段值设置默认值或null=True.
- 更好的解决办法是使用数据迁移,它可以追踪数据库表结构的变化,然后把变动应用到数据库中。
- 在Flask中可以使用Flask-Migrate的第三方扩展,来实现数据迁移。并且集成到Flask终端脚本中,所有操作通过flask db 命令就能完成。
- 为了导出数据库迁移命令,Flask-Migrate提供了一个MigrateCommand类,可以附加到flask框架中。
首先要在虚拟环境中安装Flask-Migrate。
1
|
pip install Flask-Migrate
|
官网地址:https://flask-migrate.readthedocs.io/en/latest/
代码文件内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 导入数据迁移核心类
from flask_migrate import Migrate
app = Flask(__name__)
class Config(object):
DEBUG = True
# 数据库连接配置
# SQLALCHEMY_DATABASE_URI = "数据库类型://数据库账号:密码@数据库地址:端口/数据库名称?charset=utf8mb4"
SQLALCHEMY_DATABASE_URI = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = True
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = True
app.config.from_object(Config)
db = SQLAlchemy(app=app)
# 初始化数据迁移
migrate = Migrate(app, db)
# migrate = Migrate()
# migrate.init_app(app, db)
"""模型类定义"""
# 关系表的声明方式
achieve = db.Table('tb_achievement',
db.Column('student_id', db.Integer, db.ForeignKey('tb_student.id')),
db.Column('course_id', db.Integer, db.ForeignKey('tb_course.id'))
)
class Course(db.Model):
# 定义表名
__tablename__ = 'tb_course'
# 定义字段对象
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
price = db.Column(db.Numeric(6,2))
teacher_id = db.Column(db.Integer, db.ForeignKey('tb_teacher.id'))
students = db.relationship('Student', secondary=achieve, backref='courses', lazy='subquery')
# repr()方法类似于django的__str__,用于打印模型对象时显示的字符串信息
def __repr__(self):
return 'Course:%s'% self.name
class Student(db.Model):
__tablename__ = 'tb_student'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
email = db.Column(db.String(64),unique=True)
age = db.Column(db.SmallInteger,nullable=False)
sex = db.Column(db.Boolean,default=1)
def __repr__(self):
return 'Student:%s' % self.name
class Teacher(db.Model):
__tablename__ = 'tb_teacher'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
# 课程与老师之间的多对一关联
courses = db.relationship('Course', backref='teacher', lazy='subquery')
def __repr__(self):
return 'Teacher:%s' % self.name
@app.route("/")
def index():
return "ok"
if __name__ == '__main__':
app.run(debug=True)
|
创建迁移版本仓库
1
2
3
4
5
6
|
# 切换到项目根目录下
cd ~/Desktop/flaskdemo
# 设置flask项目的启动脚本位置,例如我们现在的脚本叫manage.py
export FLASK_APP=manage.py
# 数据库迁移初始化,这个命令会在当前项目根目录下创建migrations文件夹,将来所有数据表相关的迁移文件都放在里面。
flask db init
|
创建迁移版本
- 自动创建迁移版本有两个函数
- upgrade():函数把迁移中的改动应用到数据库中。
- downgrade():函数则将改动删除。
- 自动创建的迁移脚本会根据模型定义和数据库当前状态的差异,生成upgrade()和downgrade()函数的内容。
- 对比不一定完全正确,有可能会遗漏一些细节,需要进行检查
1
2
3
4
5
6
|
# 根据flask项目的模型生成迁移文件 -m的后面你不要使用中文!!
flask db migrate -m 'initial migration'
# 这里等同于django里面的 makemigrations,生成迁移版本文件
# 完成2件事情:
# 1. 在migrations/versions生成一个数据库迁移文件
# 2. 如果是首次生成迁移文件的项目,则迁移工具还会在数据库创建一个记录数据库版本的version表
|
升级版本库的版本
1
2
|
# 从migations目录下的versions中根据迁移文件upgrade方法把数据表的结构同步到数据库中。
flask db upgrade
|
降级版本库的版本
1
2
|
# 从migations目录下的versions中根据迁移文件downgrade把数据表的结构同步到数据库中。
flask db downgrade
|
版本库的历史管理
可以根据history命令找到版本号,然后传给downgrade命令:
1
2
3
|
flask db history
输出格式:<base> -> 版本号 (head), initial migration
|
回滚到指定版本
1
2
3
|
flask db downgrade # 默认返回上一个版本
flask db downgrade 版本号 # 回滚到指定版本号对应的版本
flask db upgrade 版本号 # 升级到指定版本号对应的版本
|
数据迁移的步骤:
1
2
3
4
5
6
7
8
9
10
11
12
|
1. 初始化数据迁移的目录
export FLASK_APP=4-manage.py
flask db init
2. 数据库的数据迁移版本初始化,生成迁移文件
flask db migrate -m 'initial migration'
3. 升级版本[新增一个迁移记录]
flask db upgrade
4. 降级版本[回滚一个迁移记录]
flask db downgrade
|
模块推荐
文档: https://faker.readthedocs.io/en/master/locales/zh_CN.html
批量生成测试数据: https://github.com/joke2k/faker
1
|
pip install faker -i https://pypi.douban.com/simple
|
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
class Config(object):
DEBUG = True
# 数据库连接配置
# SQLALCHEMY_DATABASE_URI = "数据库类型://数据库账号:密码@数据库地址:端口/数据库名称?charset=utf8mb4"
SQLALCHEMY_DATABASE_URI = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = False
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = False
app.config.from_object(Config)
db = SQLAlchemy(app=app)
class Student(db.Model):
"""学生信息模型"""
__tablename__ = "db_student"
id = db.Column(db.Integer, primary_key=True,comment="主键")
name = db.Column(db.String(15), comment="姓名")
age = db.Column(db.SmallInteger, comment="年龄")
sex = db.Column(db.Boolean, default=True, comment="性别")
email = db.Column(db.String(128), comment="邮箱地址")
money = db.Column(db.Numeric(10,2), default=0.0, comment="钱包")
def __repr__(self):
return f"{self.name}<Student>"
# 自定义批量生成学生
import random,click
from faker import Faker
# 自定义终端命令
@app.cli.command("faker_user") # 指定终端命令的调用名称
@click.argument("num", default=5, type=int) # 命令的选项
def faker_user_command(num):
"""生成测试学生信息"""
faker = Faker(locale="ZH_CN")
for i in range(num):
sex = bool( random.randint(0,1) )
student = Student(
name= faker.name_male() if sex else faker.name_female(),
age=random.randint(15,60),
sex=sex,
email=faker.free_email(),
money= float( random.randint(100,100000) / 100 ),
)
db.session.add(student)
# 在循环外面统一提交
db.session.commit()
@app.route("/")
def index():
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all()
app.run()
"""
export FLASK_APP=manage.py
flask faker-user 10
"""
|
flask-session
flask-session,允许设置session到指定的存储空间中,例如:redis/mongoDB/mysql。
文档: https://flask-session.readthedocs.io/en/latest/
pip install Flask-Session
使用session之前,必须配置一下配置项:
1
2
|
# session秘钥
app.config["SECRET_KEY"] = "*(%#4sxcz(^(#$#8423"
|
SQLAlchemy存储session的基本配置
需要手动创建session表,在项目第一次启动的时候,使用db.create_all()来完成创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 引入session存储驱动类
from flask_session import Session
# 引入sessio操作类,注意:引入路径不同,大小写不同的。
from flask import session
app = Flask(__name__)
# 务必要先创建模块的实例对象
db = SQLAlchemy()
session_store = Session()
class Config(object):
DEBUG = True
# 数据库连接配置
# SQLALCHEMY_DATABASE_URI = "数据库类型://数据库账号:密码@数据库地址:端口/数据库名称?charset=utf8mb4"
SQLALCHEMY_DATABASE_URI = "mysql://root:123@127.0.0.1:3306/flaskdemo?charset=utf8mb4"
# 动态追踪修改设置,如未设置只会提示警告
SQLALCHEMY_TRACK_MODIFICATIONS = False
# 查询时会显示原始SQL语句
SQLALCHEMY_ECHO = False
# 秘钥
SECRET_KEY = "*(%#4sxcz(^(#$#8423" # session秘钥
# 把session通过SQLAlchmey保存到mysql中
SESSION_TYPE = "sqlalchemy" # session类型为sqlalchemy
SESSION_SQLALCHEMY = db # SQLAlchemy的数据库连接对象
SESSION_SQLALCHEMY_TABLE = 'db_session' # session要保存的表名称
SESSION_PERMANENT = True # 如果设置为True,则关闭浏览器session就失效
SESSION_USE_SIGNER = True # 是否对发送到浏览器上session的cookie值进行加密
SESSION_KEY_PREFIX = "session:" # session数据表中sessionID的前缀,默认就是 session:
app.config.from_object(Config)
# 在app加载配置以后,注册app对象
db.init_app(app)
session_store.init_app(app)
@app.route("/set")
def set_session():
session["uname"] = "xiaoming"
session["age"] = 18
return "ok"
@app.route("/get")
def get_session():
print(session.get("uname"))
print(session.get("age"))
return "ok"
@app.route("/del")
def del_session():
# 此处的删除,不是删除用户对应的session表记录,而是删除session值而已。
print(session.pop("uname"))
print(session.pop("age"))
return "ok"
if __name__ == '__main__':
with app.app_context():
db.create_all() # 使用Session存储库必须要调用db.create_all()或者数据迁移生成session表
app.run()
|
redis保存session的基本配置
这个功能必须确保,服务器必须已经安装了redis而且当前项目虚拟环境中已经安装了redis扩展库
1
|
pip install flask-redis -i https://pypi.douban.com/simple
|
flask-redis是第三方开发者为了方便我们在flask框架中集成redis数据库操作所封装一个redis操作库、
在flask中要基于flask-redis进行数据库则可以完成以下3个步骤即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
from flask import Flask
from flask_redis import FlaskRedis
# 实例化
app = Flask(__name__)
session_redis = FlaskRedis(config_prefix="SESSION")
user_redis = FlaskRedis(config_prefix="USER")
order_redis = FlaskRedis(config_prefix="ORDER")
# 初始化 flask_redis
session_redis.init_app(app)
user_redis.init_app(app)
order_redis.init_app(app)
@app.route("/")
def q2():
user_redis.setnx("doing", 100)
return "ok"
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
在redis中保存session,代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
from flask import Flask
from flask_redis import FlaskRedis
# 引入session存储驱动类
from flask_session import Session
# 引入sessio操作类,注意:引入路径不同,大小写不同的。
from flask import session
app = Flask(__name__)
# 要先创建模块的实例对象
session_store = Session()
redis = FlaskRedis() # config_prefix 用于指定redis的URL配置项前缀,默认值是REDIS,对应的配置项:REDIS_URL
class Config(object):
DEBUG = True
# 数据库连接配置
# 2. 在config配置中使用 REDIS_URL配置redis的url地址
REDIS_URL = "redis://@127.0.0.1:6379/0"
# 把session保存到redis
SESSION_TYPE = "redis" # session存储方式为redis
SESSION_PERMANENT = False # 如果设置session的生命周期是否是会话期, 为True,则关闭浏览器session就失效
SESSION_USE_SIGNER = False # 是否对发送到浏览器上session的cookie值进行加密
SESSION_KEY_PREFIX = "session:" # 保存到redis的session数的名称前缀
# session保存数据到redis时启用的链接对象
SESSION_REDIS = redis # 用于连接redis的配置
app.config.from_object(Config)
# 在app加载配置以后,注册app对象
redis.init_app(app)
session_store.init_app(app)
@app.route("/set")
def set_session():
session["uname"] = "xiaoming"
session["age"] = 18
return "ok"
@app.route("/get")
def get_session():
print(session.get("uname"))
print(session.get("age"))
return "ok"
@app.route("/del")
def del_session():
# 此处的删除,是直接删除保存在redis中的数据,当所有session被删除,则key也会消失了。
print(session.pop("uname"))
print(session.pop("age"))
return "ok"
if __name__ == '__main__':
app.run()
|
蓝图 Blueprint
模块化
随着flask程序越来越复杂,我们需要对程序进行模块化的处理,之前学习过django的子应用管理,flask程序进行可以进行类似的模块化处理保存代码。
简单来说,Blueprint 是一个存储视图方法/模型代码的容器(目录),这些操作在这个Blueprint 被注册到flask的APP实例对象应用之后就可以被调用,Flask 可以通过Blueprint来组织URL以及处理客户端请求。
Flask使用Blueprint让应用实现模块化,在Flask中,Blueprint具有如下属性:
- 一个项目可以具有多个Blueprint
- 可以将一个Blueprint注册到任何一个未使用的URL下比如 “/”、“/sample”或者子域名,就是路由前缀
- 在一个flask项目中,同一个BluePrint模块可以注册多次,也就是说一个蓝图可以对应多个不同的url地址。
- Blueprint可以单独具有自己的模板、静态文件或者其它的通用操作方法,它并不是必须要实现应用的视图和函数的
- 在一个flask项目初始化时,就应该要注册需要使用的Blueprint
注意:flask中的Blueprint并不是一个完整的项目应用,它不能独立运行,而必须要把蓝图blueprint注册到某一个flask项目中才能使用。
在flask中,要使用蓝图Blueprint可以分为四个步骤:
- 手动创建一个蓝图的包目录,例如users,并在
__init__.py文件中创建蓝图对象
1
2
3
4
5
|
from flask import Blueprint
# 等同于 app = Flask(__name__),只是这里并非一个独立的flask项目,所以需要在第一个参数中,指定蓝图名称,其他参数与之前实例化app应用对象是一样的。
users=Blueprint('users',__name__)
# users=Blueprint('users',__name__,static_folder="users_static")
|
- 在这个users蓝图目录下创建蓝图的子文件, 其中我们可以创建views.py文件,保存当前蓝图使用的视图函数
1
2
3
4
5
6
|
# 光写视图,不用写路由
def index():
return "ok, users.views.index"
def list():
return "用户列表"
|
- 在
users/__init__.py中引入views.py中所有的视图函数并绑定路由
1
2
3
4
5
6
7
8
9
10
|
from flask import Blueprint
from . import views
# 等同于 app = Flask(__name__),只是这里并非一个独立的flask项目,所以需要在第一个参数中,指定蓝图名称,其他参数与之前实例化app应用对象是一样的。
users=Blueprint('users',__name__)
# users=Blueprint('users',__name__,static_folder="users_static")
# 注册路由
users.add_url_rule(rule="/index",view_func=views.index) # 路由必须以/开头
users.add_url_rule(rule="/list",view_func=views.list) # 路由必须以/开头
|
- 在主应用下程序入口manage.py文件中把这个users蓝图对象注册app实例对象中,运行起来。
1
2
3
4
5
6
7
8
9
10
11
|
from flask import Flask
from users import users
# 实例化
app = Flask(__name__)
# 注册蓝图
app.register_blueprint(users, url_prefix='/users') # 路由必须以/开头
if __name__ == '__main__':
app.run(host="0.0.0.0", port=5000, debug=True)
|
当这个应用启动后,通过/users/可以访问到蓝图中定义的视图函数
蓝图运行机制
- 蓝图BluePrint实际上的作用就是,充当当前蓝图目录下的所有视图和url路由地址的绑定关系的容器,可以在将来flask的app应用实例对象上执行操作的路由关系.
- 在视图被蓝图的add_url_rule注册时,这个操作本质就是将视图和url地址的映射关系添加到蓝图的临时路由表变量deferred_functions中。
- 蓝图对象根本没有路由表,当我们在蓝图中的视图函数上调用route装饰器(或者add_url_role)注册路由时,它只是在蓝图对象的内部的deferred_functions(延迟操作路由记录列表)中添加了一个路由项(路由项实际上就是一个绑定了视图和url地址的lambda匿名函数)
- 当执行app.register_blueprint()注册蓝图时,app应用实例对象会将从蓝图对象的 deferred_functions列表中循环取出每一个之前注册的路由项,并把app应用实例对象自己作为参数执行路由项对应的lambda匿名函数,lambda匿名函数执行以后就会调用app.add_url_rule() 方法,这就将蓝图下之前暂存的路由信息全部添加到了app应用实例对象的url_map路由表中了,所以用户就可以在flask中访问到了蓝图中的视图。
蓝图的url拼接
- 当我们在app应用实例对象上注册一个蓝图时,可以指定一个url_prefix关键字参数(这个参数默认是/)
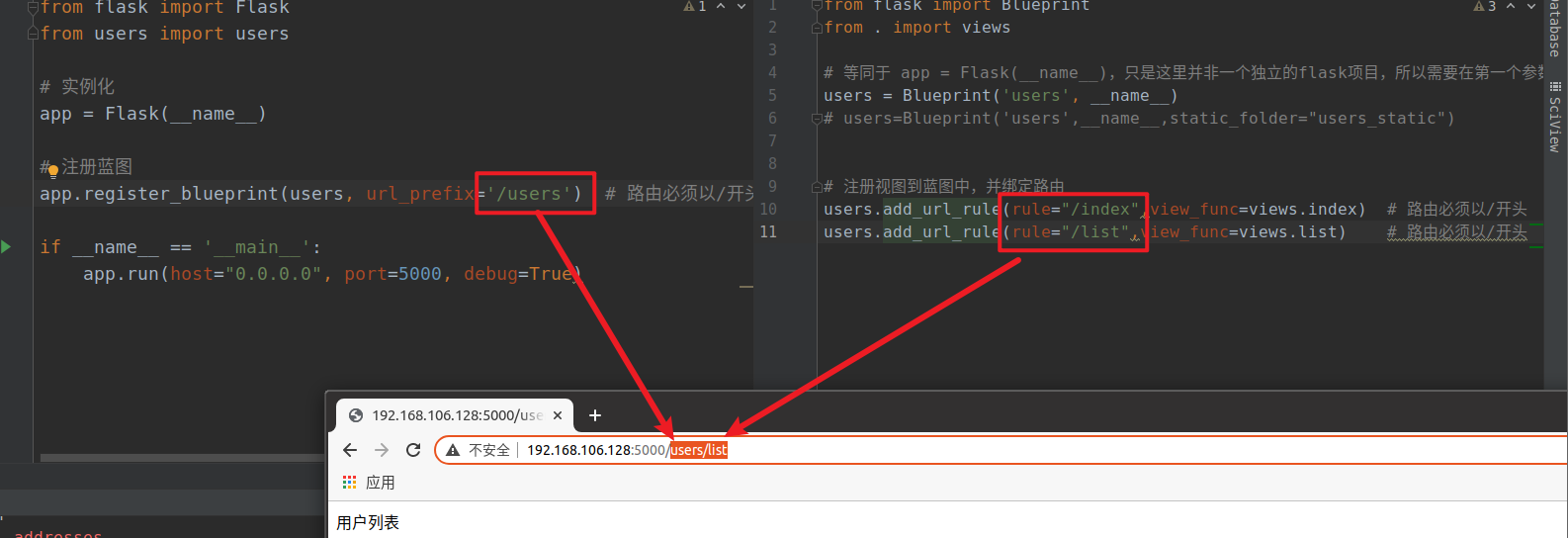
- 在app应用实例对象的最终的路由表 url_map中,在蓝图上注册的路由URL自动被加上了这个路由前缀,这个可以保证在多个蓝图中使用相同的子路由而不会最终引起冲突,只要在注册蓝图时将不同的蓝图挂接到不同的自路径即可
- 注意:有了蓝图以后,在flask使用url_for在使用时,如果要生成一个蓝图里面的视图对应的路由地址,则需要声明当前蓝图名称+视图名称
1
2
|
# url_for('蓝图名称.视图函数名')
url_for('users.home') # /users + /home /users就是蓝图中的路由前缀 /home就是子路由
|
users/views.py,代码:
1
2
3
4
5
6
7
8
9
|
# 光写视图,不用写路由
from flask import url_for
def index():
return "ok, users.views.index"
def list():
url = url_for("users.index")
return f"用户列表 <a href='{url}'>蓝图的index方法</a>"
|
注册蓝图下的静态文件[很少使用]
和app应用对象不同,蓝图对象创建时不会默认注册静态目录的路由。需要我们在创建时手动指定 static_folder 参数。
下面的代码将蓝图所在目录下的static_users目录设置为静态目录
users/__init__.py,代码:
1
2
3
4
5
6
7
8
9
10
11
|
from flask import Blueprint
from . import views
# 等同于 app = Flask(__name__),只是这里并非一个独立的flask项目,所以需要在第一个参数中,指定蓝图名称,其他参数与之前实例化app应用对象是一样的。
# users = Blueprint('users', __name__)
users=Blueprint('users', __name__, static_folder="static_users") # 分不同蓝图保存静态资源
# 注册视图到蓝图中,并绑定路由
users.add_url_rule(rule="/index",view_func=views.index) # 路由必须以/开头
users.add_url_rule(rule="/list",view_func=views.list) # 路由必须以/开头
|
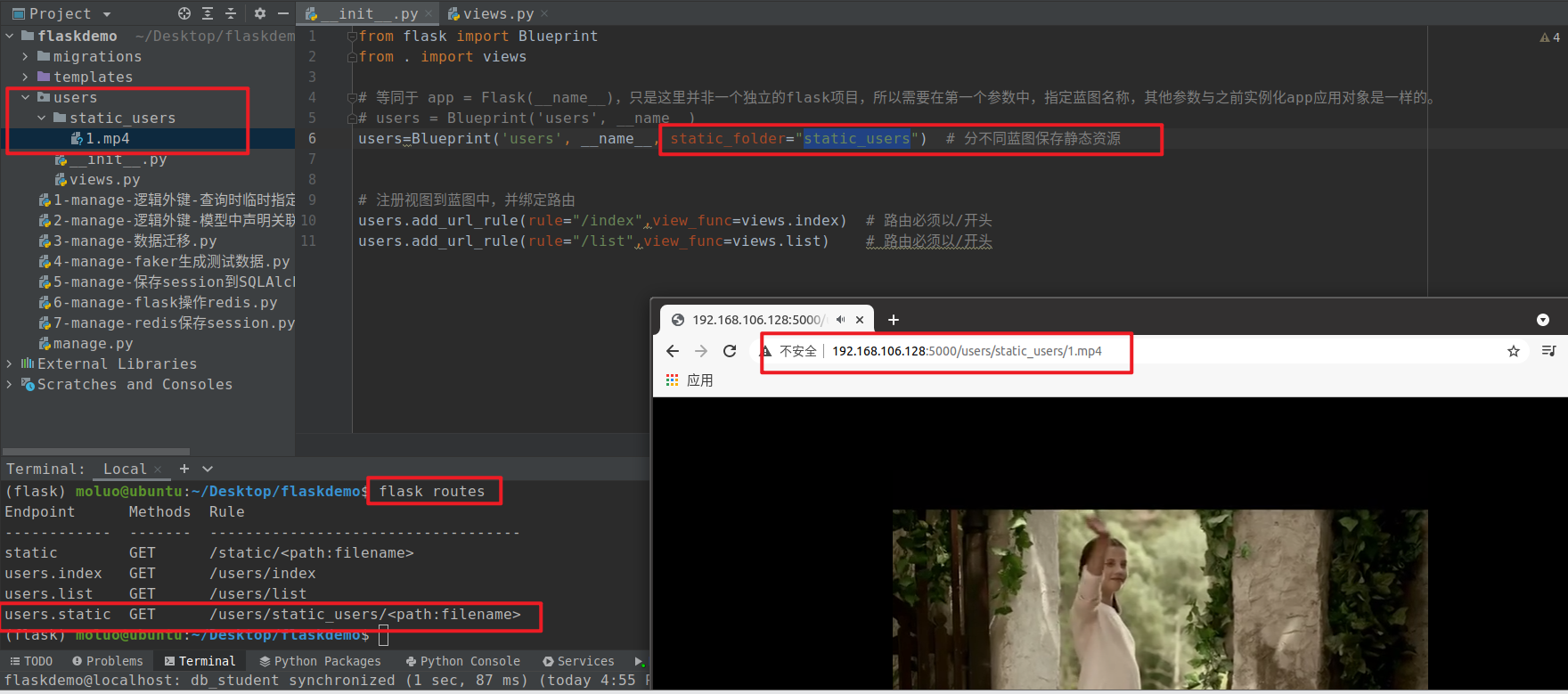
现在就可以使用http://127.0.0.1:5000/users/static_users/1.mp4访问users/static_users/目录下的静态文件了.
当然,也可以修改访问静态文件的路径 :可以在创建蓝图对象时使用 static_url_path 来改变静态目录的url地址。
1
2
3
4
5
6
7
8
9
10
|
from flask import Blueprint
from . import views
# 等同于 app = Flask(__name__),只是这里并非一个独立的flask项目,所以需要在第一个参数中,指定蓝图名称,其他参数与之前实例化app应用对象是一样的。
# users=Blueprint('users',__name__)
users=Blueprint('users',__name__,static_folder="static_users", static_url_path="/file") # 分不同蓝图保存静态资源, 路由必须以/开头
# 注册路由
users.add_url_rule(rule="/index",view_func=views.index) # 路由必须以/开头
users.add_url_rule(rule="/list",view_func=views.list) # 路由必须以/开头
|
现在就可以使用http://127.0.0.1:5000/users/file/1.mp4访问users/static_users/目录下的静态文件了.
设置蓝图下的html模版[很少使用]
创建蓝图中的模板目录templates,users.__init__.py,代码:
1
2
3
4
5
6
7
8
9
10
|
from flask import Blueprint
from . import views
# 等同于 app = Flask(__name__),只是这里并非一个独立的flask项目,所以需要在第一个参数中,指定蓝图名称,其他参数与之前实例化app应用对象是一样的。
# users = Blueprint('users', __name__)
users=Blueprint('users', __name__, static_folder="static_users", static_url_path="/file", template_folder="templates") # 分不同蓝图保存静态资源
# 注册视图到蓝图中,并绑定路由
users.add_url_rule(rule="/index",view_func=views.index) # 路由必须以/开头
users.add_url_rule(rule="/list",view_func=views.list) # 路由必须以/开头
|
视图users.views,代码:
1
2
3
4
5
6
7
8
9
10
11
|
# 光写视图,不用写路由
from flask import url_for,render_template
def index():
title = "hello! users.index视图的数据"
return render_template("index.html", **locals())
def list():
url = url_for("users.index")
return f"用户列表 <a href='{url}'>蓝图的index方法</a>"
|
模板代码,users/templates/index.html,代码:
1
2
3
4
5
6
7
8
9
10
11
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1>users.template</h1>
<p>{{ title }}</p>
</body>
</html>
|